Servo: El modo inmersivo no alcanza los 60 fps
Estoy usando esto para rastrear investigaciones sobre la causa de valores bajos de FPS cuando uso el modo inmersivo en dispositivos.
 jdm
jdm
Todos 71 comentarios
Alguna información que se ha descubierto:
- hay largas esperas entre xrWaitFrame y xrBeginFrame
- en la aplicación de demostración, estos ocurren secuencialmente
- en el modelo de Servo, esperamos un marco de dispositivo , luego, una vez que recibimos el renderizado del hilo webgl, comenzamos el siguiente marco de openxr
Un rastro de la demostración de pintura con marcadores para las API de OpenXR se reproduce estos días, y también se muestra durante ese período:
- el hilo webgl usa la mayor parte de la CPU (una gran mayoría de ese tiempo se gasta en gl :: Finish, que se llama desde el dispositivo de surfman :: bind_surface_to_context)
- el hilo principal es el segundo más ocupado, con el mayor uso gastado en eglCreatePbufferFromClientBuffer y casi el mismo tiempo dedicado a tomar el objeto Egl de TLS
- La representación de Webrender también aparece en esta pila.
- winrt :: servo :: flush también aparece aquí, y no me queda claro si realmente necesitamos intercambiar los búferes GL de la aplicación principal mientras estamos en modo inmersivo
- El tercer uso más alto de CPU es el hilo de secuencia de comandos, que pasa mucho tiempo dentro del código JIT
- después de ese hilo, el uso de la CPU es generalmente bastante bajo, pero aparecen algunos símbolos de la caja de estilo que indican que se está produciendo el diseño
jdm
en 3 ene. 2020
Dados esos puntos de datos, intentaré dos enfoques para comenzar:
- iniciar el siguiente cuadro XR tan pronto como sea posible después de esperar el cuadro del dispositivo
- reducir la cantidad de veces que necesitamos llamar gl :: Finish (hilo webgl), eglCreateBufferFromClientBuffer y TLS (hilo principal)
jdm
en 3 ene. 2020
https://github.com/servo/servo/pull/25343#issuecomment -567706735 tiene más investigación sobre el impacto de enviar mensajes a varios lugares del motor. No apunta con ningún dedo claro, pero sugiere que se deben tomar medidas más precisas.
jdm
en 3 ene. 2020
El uso de gl :: Finish proviene de https://github.com/pcwalton/surfman/blob/6705a9aaa8f33ac1324fdb1913242800e68c7720/surfman/src/platform/windows/angle/context.rs#L259 -L266.
jdm
en 3 ene. 2020
Cambiar gl :: Finish a gl :: Flush aumenta la velocidad de fotogramas de ~ 15-> 30, pero hay un retraso extremadamente notable en el contenido del fotograma que refleja realmente el movimiento de la cabeza del usuario, lo que hace que el fotograma actual siga la cabeza del usuario en mientras tanto.
jdm
en 3 ene. 2020
Los mutex con clave están deshabilitados de forma predeterminada en ANGLE por razones que eluden, pero mozangle los habilita explícitamente (https://github.com/servo/mozangle/blob/706a9baaf8026c1a3cb6c67ba63aa5f4734264d0/build_data.rs#L175), y eso es con lo que se prueba surfman . Voy a hacer una compilación de ANGLE que los habilite y veré si eso es suficiente para evitar las llamadas gl :: Finish.
jdm
en 3 ene. 2020
¡Confirmado! Forzar mutex con clave en ANGLE me da 25-30 FPS en la demostración de pintura sin ninguno de los problemas de retraso que vinieron con el cambio de la llamada gl :: Finish.
jdm
en 3 ene. 2020
Ah, y otro dato según las investigaciones de lars:
- w / dom.ion.enabled establecido en falso, el tiempo JIT desaparece. Las cargas iniciales son mucho más lentas, pero una vez que las cosas están funcionando, son bastante buenas.
- Todavía no es fantástico: el uso de memoria es bastante alto (básicamente toda la memoria disponible) en ese ejemplo de babylon.js
- deberíamos hacer otra actualización de spidermonkey para incorporar optimizaciones relacionadas con arm64 que han estado sucediendo para FxR en dispositivos Android
jdm
en 3 ene. 2020
Creo que entendí mal la presencia de std::thread::local::LocalKey<surfman::egll::Egl> en los perfiles; estoy bastante seguro de que la lectura de TLS es solo una pequeña parte del tiempo que se le carga, y son las funciones llamadas dentro del bloque TLS como eglCreatePbufferFromClientBuffer y DXGIAcquireSync que _actualmente_ se toma el tiempo.
jdm
en 3 ene. 2020
Lamentablemente, deshabilitar js.ion.enabled parece dañar el FPS de la demostración de pintura, reduciéndolo a 20-25.
jdm
en 4 ene. 2020
En lugar de llamar a Device :: create_surface_texture_from_texture dos veces en cada cuadro (una vez para cada textura d3d para cada ojo), podría ser posible crear texturas de superficie para todas las texturas swapchain cuando se crea el dispositivo openxr webxr. Si esto funciona, eliminaría al segundo usuario más grande de CPU del hilo principal durante el modo inmersivo.
jdm
en 4 ene. 2020
Otra idea para reducir el uso de memoria: ¿hay algún impacto si configuramos el bfcache en un número muy bajo para que la canalización de la página de inicio de HL original sea desalojada al navegar a una de las demostraciones?
jdm
en 4 ene. 2020
El siguiente parche webxr no mejora claramente los FPS, pero podría mejorar la estabilidad de la imagen. Necesito crear dos compilaciones separadas que pueda ejecutar una detrás de la otra para verificar.
diff --git a/webxr/openxr/mod.rs b/webxr/openxr/mod.rs
index 91c78da..a6866de 100644
--- a/webxr/openxr/mod.rs
+++ b/webxr/openxr/mod.rs
@@ -416,11 +416,30 @@ impl DeviceAPI<Surface> for OpenXrDevice {
}
fn wait_for_animation_frame(&mut self) -> Option<Frame> {
- if !self.handle_openxr_events() {
- // Session is not running anymore.
- return None;
+ loop {
+ if !self.handle_openxr_events() {
+ // Session is not running anymore.
+ return None;
+ }
+ self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
+ // XXXManishearth this code should perhaps be in wait_for_animation_frame,
+ // but we then get errors that wait_image was called without a release_image()
+ self.frame_stream
+ .begin()
+ .expect("failed to start frame stream");
+
+ if self.frame_state.should_render {
+ break;
+ }
+
+ self.frame_stream.end(
+ self.frame_state.predicted_display_time,
+ EnvironmentBlendMode::ADDITIVE,
+ &[],
+ ).unwrap();
}
- self.frame_state = self.frame_waiter.wait().expect("error waiting for frame");
+
let time_ns = time::precise_time_ns();
// XXXManishearth should we check frame_state.should_render?
let (_view_flags, views) = self
@@ -506,12 +525,6 @@ impl DeviceAPI<Surface> for OpenXrDevice {
0,
);
- // XXXManishearth this code should perhaps be in wait_for_animation_frame,
- // but we then get errors that wait_image was called without a release_image()
- self.frame_stream
- .begin()
- .expect("failed to start frame stream");
-
self.left_image = self.left_swapchain.acquire_image().unwrap();
self.left_swapchain
.wait_image(openxr::Duration::INFINITE)
@manishearth ¿ alguna idea sobre esto? Es mi intento de acercarme al modelo descrito por https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#Session.
jdm
en 4 ene. 2020
Sí, eso se ve bien. Tenía la intención de mover begin() hacia arriba en waf, y creo que el error mencionado en el comentario ya no ocurre, pero tampoco tuvo un efecto notable en FPS, así que no lo seguí. demasiado por ahora. Si mejora la estabilidad, ¡está bien!
 Manishearth
en 4 ene. 2020
Manishearth
en 4 ene. 2020
¡Realmente feliz por el descubrimiento con llave! Las llamadas de Surfman de hecho ocupan una gran parte del presupuesto del marco, pero es un poco difícil determinar qué es y qué no es necesario.
Manishearth
en 4 ene. 2020
Sí, re: deshabilitar js.ion.enabled , eso solo será un beneficio cuando estemos hambrientos de RAM y gastando la mayor parte de nuestro tiempo en GC y recompilando funciones. Y eso debería mejorarse con un SM más nuevo. IIRC, el backend ARM64 de la era 66 también tuvo un rendimiento de intérprete y JIT de referencia relativamente bajo; Deberíamos ver aceleraciones en todos los ámbitos con una actualización, pero especialmente en aplicaciones con uso intensivo de RAM.
 larsbergstrom
en 4 ene. 2020
larsbergstrom
en 4 ene. 2020
Se publicó un nuevo paquete ANGLE con las exclusiones mutuas habilitadas. Crearé una solicitud de extracción para actualizarla más tarde.
jdm
en 6 ene. 2020
Intenté crear las texturas de la superficie para todas las imágenes de la cadena de intercambio de openxr durante la inicialización del dispositivo XR, pero todavía hay un montón de tiempo en el hilo principal dedicado a llamar a eglCreatePbufferFromClientBuffer en la superficie que recibimos del hilo webgl en cada fotograma. Tal vez haya alguna forma de almacenar en caché esas texturas de superficie para que podamos reutilizarlas si recibimos la misma superficie ...
jdm
en 6 ene. 2020
El mayor uso de CPU del subproceso principal proviene de render_animation_frame, con la mayor parte en el tiempo de ejecución de OpenXR, pero las llamadas a BlitFramebuffer y FramebufferTexture2D definitivamente también aparecen en el perfil. Me pregunto si sería una mejora hacer blit ambos ojos a la vez en una sola textura. Tal vez eso esté relacionado con las cosas de la matriz de texturas que se discuten en https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt.
jdm
en 6 ene. 2020
Podemos cerrar los dos ojos a la vez, sin embargo, tengo entendido que el tiempo de ejecución
entonces puede hacer su propio blit. La matriz de texturas es el método más rápido. Pero
Vale la pena intentarlo, la API de vista de proyección permite hacer esto.
En cuanto al tráfico ANGLE del hilo principal, detener el bucle RAF de
ensuciar la lona ayuda? Hasta ahora esto no ha hecho nada, pero vale la pena
tiro, idealmente no deberíamos estar haciendo nada de diseño / renderizado en el
hilo.
El lunes 6 de enero de 2020 a las 11:49 p.m. Josh Matthews [email protected]
escribió:
El mayor uso de CPU del subproceso principal proviene de render_animation_frame, con
la mayor parte de eso en el tiempo de ejecución de OpenXR, pero llama a BlitFramebuffer y
FramebufferTexture2D definitivamente también aparece en el perfil. me pregunto
si fuera una mejora cerrar los dos ojos a la vez a un solo
¿textura? Tal vez eso esté relacionado con las cosas de la matriz de texturas que se discuten
en
https://github.com/microsoft/OpenXR-SDK-VisualStudio/#render -with-texture-array-and-vprt
.-
Recibes esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/servo/servo/issues/25425?email_source=notifications&email_token=AAMK6SBRH72JGZMXTUKOXETQ4NY37A5CNFSM4KCRI6AKYY3PNVWWK3TUL52HS4DFVREXG43VMDVNIG4W63 ,
o darse de baja
https://github.com/notifications/unsubscribe-auth/AAMK6SECM6MDNZZ6Y7VL7SDQ4NY37ANCNFSM4KCRI6AA
.
Manishearth
en 6 ene. 2020
Quitar la lona ensuciando solo limpia el perfil; no pareció dar lugar a un aumento significativo de FPS.
jdm
en 6 ene. 2020
Intenté crear un caché de texturas de superficie para las superficies del hilo webgl, así como las texturas de la cadena de intercambio de openxr, y aunque el tiempo de eglCreatePbufferFromClientBuffer desapareció por completo, no noté ningún cambio significativo en FPS.
jdm
en 6 ene. 2020
Alguna información de tiempo para varias operaciones en la tubería inmersiva (todas las medidas en ms):
Name min max avg
raf queued 0.070833 14.010261 0.576834
<1ms: 393
<2ms: 28
<4ms: 5
<8ms: 1
<16ms: 2
<32ms: 0
32+ms: 0
raf transmitted 0.404270 33.649583 7.403302
<1ms: 123
<2ms: 43
<4ms: 48
<8ms: 48
<16ms: 95
<32ms: 69
32+ms: 3
raf wait 1.203500 191.064100 17.513593
<1ms: 0
<2ms: 17
<4ms: 98
<8ms: 95
<16ms: 48
<32ms: 69
32+ms: 101
raf execute 3.375000 128.663200 6.994588
<1ms: 0
<2ms: 0
<4ms: 5
<8ms: 351
<16ms: 70
<32ms: 1
32+ms: 2
raf receive 0.111510 8.564010 0.783503
<1ms: 353
<2ms: 52
<4ms: 18
<8ms: 4
<16ms: 1
<32ms: 0
32+ms: 0
raf render 2.372200 75.944000 4.219310
<1ms: 0
<2ms: 0
<4ms: 253
<8ms: 167
<16ms: 8
<32ms: 0
32+ms: 1
receive : tiempo desde que se envía la información del marco XR desde el hilo XR hasta que el enrutador IPC la recibe
queued : tiempo desde que el enrutador IPC recibe la información del marco hasta que se invoca XRSession :: raf_callback
execute : tiempo desde XRSession :: raf_callback invocado hasta regresar del método
transmitted : tiempo desde que se envía la solicitud de un nuevo rAF desde el hilo del script hasta que lo recibe el hilo XR
render : tiempo necesario para llamar render_animation_frame y reciclar la superficie
wait : tiempo empleado por wait_for_animation_frame (usando el parche de antes en este número que recorre los marcos que no deberían renderizarse)
Debajo de cada entrada se encuentra la distribución de los valores a lo largo de la sesión.
jdm
en 7 ene. 2020
Un punto de datos interesante de esa información de tiempo: la categoría transmitted parece mucho más alta de lo que debería ser. Ese es el retraso entre la ejecución de la devolución de llamada rAF y el subproceso XR que recibe el mensaje que transmite el cuadro completo a la textura de openxr. Hay bastante variación, lo que sugiere que o el hilo principal está ocupado haciendo otras cosas, o necesita ser despertado para procesarlo.
jdm
en 7 ene. 2020
Dados los datos anteriores, puedo intentar resucitar https://github.com/servo/webxr/issues/113 mañana para ver si eso afecta positivamente el tiempo de transmisión. Es posible que primero pinche en el hilo principal del generador de perfiles para ver si se me ocurren ideas sobre cómo saber si el hilo está ocupado con otras tareas o dormido.
jdm
en 7 ene. 2020
Otro punto de datos:
swap buffer 1.105938 28.193698 2.154793
<1ms: 0
<2ms: 273
<4ms: 110
<8ms: 15
<16ms: 2
<32ms: 2
32+ms: 0
swap complete 0.053802 4.337812 0.295064
<1ms: 308
<2ms: 9
<4ms: 6
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
swap request 0.003333 24033027.355364 4662890.724805
<1ms: 268
<2ms: 49
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 1
32+ms: 79
Estos son tiempos relacionados con 1) el retraso desde el envío del mensaje de intercambio de búfer hasta que se procesa en el hilo de webgl, 2) el tiempo necesario para intercambiar los búferes, 3) el retraso desde el envío del mensaje que indica que el intercambio está completo hasta que se recibe en el hilo de la secuencia de comandos. No hay nada muy sorprendente aquí (excepto esos valores atípicos extraños en la categoría swap request , pero que ocurren al comienzo de la sesión inmersiva durante la configuración de un faict), pero el intercambio de búfer real toma consistentemente entre 1 y 4 ms.
jdm
en 7 ene. 2020
Archivado # 117 después de leer un código de muestra de openxr y notar que las llamadas de Locate_views aparecen en el perfil.
jdm
en 7 ene. 2020
Presumiblemente https://github.com/servo/webxr/issues/117
 asajeffrey
en 7 ene. 2020
asajeffrey
en 7 ene. 2020
Un punto de datos interesante de esa información de tiempo: la categoría transmitida parece mucho más alta de lo que debería ser. Ese es el retraso entre la ejecución de la devolución de llamada rAF y el subproceso XR que recibe el mensaje que transmite el cuadro completo a la textura de openxr. Hay bastante variación, lo que sugiere que o el hilo principal está ocupado haciendo otras cosas, o necesita ser despertado para procesarlo.
Con respecto a las variaciones en el transmitted , podría relacionarse con el tiempo de espera utilizado como parte de run_one_frame cuando la sesión se ejecuta en el hilo principal (que está en esas medidas, ¿verdad?) , consulte https://github.com/servo/webxr/blob/c6abf4c60d165ffc978ad2ebd6bcddc3c21698e1/webxr-api/session.rs#L275
Supongo que cuando se recibe el RenderAnimationFrame msg (el enviado por el hilo de secuencia de comandos después de ejecutar las devoluciones de llamada) antes del tiempo de espera, se accede a la "ruta rápida", y si se pierde el tiempo de espera, el Servo pasa a otro iteración de perform_updates , y "ejecutar otro marco" ocurre bastante tarde en el ciclo, como parte de compositor.perform_updates , que a su vez se llama bastante tarde como parte de servo.handle_events .
Aparte de mover XR a su propio hilo, podría valer la pena ver si un valor más alto para el tiempo de espera mejora el valor promedio (aunque podría no ser la solución correcta ya que podría privar a otras cosas necesarias en el hilo principal).
 gterzian
en 8 ene. 2020
gterzian
en 8 ene. 2020
He progresado en la eliminación de openxr del hilo principal en https://github.com/servo/webxr/issues/113 , así que voy a tomar más medidas basadas en ese trabajo la próxima semana.
jdm
en 10 ene. 2020
Técnicas para obtener perfiles útiles del dispositivo:
- use un .servobuild que incluya
rustflags = "-C force-frame-pointers=yes" - descomentar estas líneas
- utilice WinXR_Perf.wprp de la pestaña char
Filesde los equipos de MS como un perfil de seguimiento personalizado en "Seguimiento del rendimiento" en el portal del dispositivo HL - construir con
--features profilemozjs
Estos seguimientos (obtenidos de "Iniciar seguimiento" en el portal del dispositivo) se podrán utilizar dentro de la herramienta Windows Performance Analyzer. Esta herramienta no muestra los nombres de los subprocesos, pero los subprocesos que utilizan la mayor parte de la CPU son fáciles de identificar en función de las pilas.
Para perfilar la distribución de tiempo de un marco openxr particular:
- agregue la vista "Actividad del sistema -> Eventos genéricos" en WPA
- filtrar la vista para mostrar solo la serie Microsoft.Windows.WinXrContinuousProvider
- amplíe a una duración corta, luego refine la región ampliada para que un evento xrBegin esté en el lado izquierdo de la vista, y un evento xrEnd esté en el lado derecho de la vista
Vistas más útiles para el uso de la CPU:
- Uso de CPU (muestreado) -> Utilización por proceso, subproceso, pila (filtre la vista para mostrar solo Servo, luego deshabilite la columna Proceso)
- Llama por proceso, apilado (filtrar la vista para mostrar solo el servo)
jdm
en 16 ene. 2020
Una posibilidad para hacer un poco menos de trabajo en el hilo del script:
- XRView :: new consume 0.02% de toda la CPU Servo
- dado que el contenido de los objetos de vista no cambia a menos que haya un evento FrameUpdateEvent :: UpdateViews (que proviene de Session :: update_clip_planes a través de XRSession :: UpdateRenderState), posiblemente podríamos almacenar en caché los objetos XRView en la XRSession y seguir usándolos hasta el el estado de representación se actualiza
- incluso podríamos mantener la representación JS de la lista de vistas almacenada en caché en XRSession y establecer el miembro de vistas de la pose, evitando tanto recrear los objetos XRView como asignar el vector y realizar la conversión de valor JS
jdm
en 16 ene. 2020
Una posibilidad para hacer menos trabajo al renderizar un marco inmersivo:
- GL y d3d tienen sistemas de coordenadas Y invertidos
- ANGLE oculta implícitamente esto cuando se presenta en la pantalla haciendo un trabajo detrás de escena
- para el modo inmersivo, usamos glBlitFramebuffer para realizar una inversión y cuando se transfieren los datos de textura GL a d3d
- Si podemos averiguar cómo hacer que ANGLE no realice la conversión internamente, podría ser posible invertir este modelo y hacer que la renderización de páginas web no inmersivas requiera un blit de inversión y adicional (a través de la opción webrender
surface_origin_is_top_left) mientras que el modo inmersivo podría desactivarse sin ninguna transformación
Basado en https://bugzilla.mozilla.org/show_bug.cgi?id=1591346 y hablando con jrmuizel, esto es lo que debemos hacer:
- obtener una cadena de intercambio d3d para el elemento de ventana en el que queremos representar las páginas no inmersivas (este será el SwapChainPanel en la aplicación XAML)
- envuélvalo en una imagen EGL (https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#554)
- Presentar explícitamente la cadena de intercambio cuando queramos actualizar la representación principal
- evite usar eglCreateWindowSurface y eglSwapBuffers en https://github.com/servo/servo/blob/master/support/hololens/ServoApp/ServoControl/OpenGLES.cpp#L205 -L208
Código de Gecko relevante: https://searchfox.org/mozilla-central/rev/c52d5f8025b5c9b2b4487159419ac9012762c40c/gfx/webrender_bindings/RenderCompositorANGLE.cpp#192
Código de ANGLE relevante: https://github.com/google/angle/blob/df0203a9ae7a285d885d7bc5c2d4754fe8a59c72/src/libANGLE/renderer/d3d/d3d11/winrt/SwapChainPanelNativeWindow.cpp#L244
jdm
en 16 ene. 2020
Ramas de wip actuales:
- https://github.com/servo/ipc-channel/tree/try-recv-error
- https://github.com/jdm/webxr/tree/oxr
- https://github.com/jdm/rust-offscreen-rendering-context/tree/angle-perf
- https://github.com/jdm/servo/tree/profile
Esto incluye una función xr-profile que agrega los datos de tiempo que mencioné anteriormente, así como una implementación inicial de los cambios de ÁNGULO para eliminar la transformación inversa y en modo inmersivo. El modo no inmersivo se renderiza correctamente, pero el modo inmersivo está al revés. Creo que necesito eliminar el código GL de render_animation_frame y reemplazarlo con una llamada directa a CopySubresourceRegion extrayendo el identificador compartido de la superficie GL para poder obtener su textura d3d.
jdm
en 17 ene. 2020
Archivado https://github.com/servo/servo/issues/25582 para el trabajo de inversión y ANGLE; Se llevarán a cabo más actualizaciones sobre ese trabajo en esa edición.
jdm
en 23 ene. 2020
El próximo elemento importante será investigar formas de evitar las llamadas glBlitFramebuffer en el backend openxr webxr por completo. Esto requiere:
- crear framebuffers openxr que coincidan con los framebuffers opacos webgl requeridos con precisión
- admitir un modo webgl donde el backend webxr proporciona todas las superficies de la cadena de intercambio, en lugar de crearlas (por ejemplo, en https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L458 y https://github.com/asajeffrey/surfman-chains/blob/27a7ab8fec73f19f0c4252ff7ab52e84609e1fa5/surfman-chains/lib.rs#L111-L118)
jdm
en 23 ene. 2020
Eso puede ser difícil, ya que surfman solo proporciona acceso de escritura al contexto que creó la superficie, por lo que si la superficie es creada por el subproceso openxr, el subproceso WebGL no podrá escribirla. https://github.com/pcwalton/surfman/blob/a515fb2f5d6b9e9b36ba4e8b498cdb4bea92d330/surfman/src/device.rs#L95 -L96
asajeffrey
en 23 ene. 2020
Se me ocurre: si hiciéramos el renderizado de openxr en el hilo webgl, muchos de los problemas relacionados con el hilo en torno al renderizado directamente en las texturas de openxr ya no serían problemas (es decir, las restricciones sobre eglCreatePbufferFromClientBuffer que prohíben el uso de varios dispositivos d3d). Considerar:
- todavía hay un hilo de openxr que es responsable de sondear los eventos de openxr, esperar un cuadro de animación, comenzar un nuevo cuadro y recuperar el estado del cuadro actual
- el estado del marco se envía al hilo del script, que realiza la devolución de llamada de la animación y luego envía un mensaje al hilo webgl para intercambiar el framebuffer de la capa xr
- cuando se recibe este mensaje de intercambio en el hilo de webgl, liberamos la última imagen de cadena de intercambio de openxr adquirida, enviamos un mensaje al hilo de openxr para finalizar el fotograma actual y adquirimos una nueva imagen de cadena de intercambio para el siguiente fotograma
Mi lectura de https://www.khronos.org/registry/OpenXR/specs/1.0/html/xrspec.html#threading -behavior sugiere que este diseño podría funcionar. El truco es si puede funcionar para nuestros backends que no son openxr y también para openxr.
De la especificación: "Si bien no es necesario llamar a xrBeginFrame y xrEndFrame en el mismo subproceso, la aplicación debe manejar la sincronización si se llaman en subprocesos separados".
jdm
en 25 ene. 2020
Por el momento, no hay comunicación directa entre los subprocesos del dispositivo XR y webgl, todo se realiza a través de un script o de su cadena de intercambio compartida. Me sentiría tentado a proporcionar una API de cadena de intercambio que se encuentre sobre una cadena de intercambio de surfman o una cadena de intercambio de openxr, y usarla para la comunicación de webgl a openxr.
asajeffrey
en 25 ene. 2020
Notas de una conversación sobre las mediciones de tiempo anteriores:
* concerns about wait time - why?????
* figure out time spent in JS vs. DOM logic
* when does openxr give us should render=false frames - maybe related to previous frame taking too long
* are threads being scheduled on inappropriate cpus? - on magic leap, main thread (including weber) pinned to big core.
* when one of the measured numbers is large, is there correlation with other large numbers?
* probably should pin openxr thread, running deterministic code
* consider clearing after telling script that the swap is complete - measure if clear is taking significant time in swap operation
* consider a swap chain API operation - “wait until a buffer swap occurs”
- block waiting on swapchain
- block waiting on swapchain + timeout
- async????????
- a gc would look like a spike in script execution time
Archivado # 25735 para realizar un seguimiento de las investigaciones que estoy realizando sobre la renderización directamente a las texturas openxr.
jdm
en 11 feb. 2020
Una cosa que debemos hacer es reducir cómo se compara spidermonkey en el dispositivo con otros motores. La forma más fácil de obtener algunos datos aquí es encontrar un punto de referencia JS simple que pueda ejecutar Servo y comparar el rendimiento de Servo con el navegador Edge instalado en el dispositivo. Además, podríamos intentar visitar algunas demostraciones complejas de Babilonia en ambos navegadores sin ingresar al modo inmersivo para ver si hay una diferencia de rendimiento significativa. Esto también nos dará un punto de referencia para comparar con la próxima actualización de spidermonkey.
jdm
en 13 feb. 2020
Algunos datos nuevos. Esto es con la actualización ANGLE, pero no con la IPC.
$ python timing.py raw
Name min max mean
raf queued 0.056198 5.673125 0.694902
<1ms: 335
<2ms: 26
<4ms: 17
<8ms: 7
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.822917 36.582083 7.658619
<1ms: 1
<2ms: 4
<4ms: 31
<8ms: 181
<16ms: 158
<32ms: 8
32+ms: 1
raf wait 1.196615 39.707709 10.256875
<1ms: 0
<2ms: 32
<4ms: 93
<8ms: 67
<16ms: 107
<32ms: 68
32+ms: 17
raf execute 3.078438 532.205677 7.752839
<1ms: 0
<2ms: 0
<4ms: 37
<8ms: 290
<16ms: 52
<32ms: 2
32+ms: 3
raf receive 0.084375 9.053125 1.024403
<1ms: 276
<2ms: 71
<4ms: 27
<8ms: 9
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.004115 73.939479 0.611254
<1ms: 369
<2ms: 10
<4ms: 5
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 2
raf render 5.706198 233.459636 9.241698
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 183
<16ms: 190
<32ms: 10
32+ms: 1
run_one_frame 7.663333 2631.052969 28.035143
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 3
<16ms: 157
<32ms: 185
32+ms: 41
swap buffer 0.611927 8.521302 1.580279
<1ms: 127
<2ms: 169
<4ms: 74
<8ms: 15
<16ms: 1
<32ms: 0
32+ms: 0
swap complete 0.046511 2.446302 0.215040
<1ms: 375
<2ms: 6
<4ms: 3
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Datos de tiempo: https://gist.github.com/Manishearth/825799a98bf4dca0d9a7e55058574736
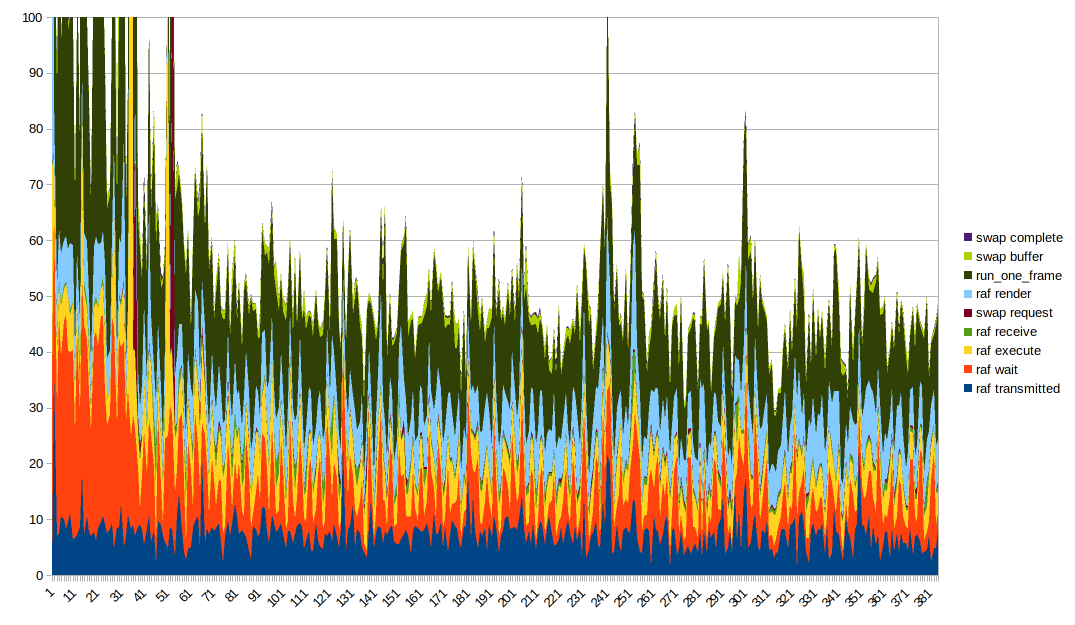
Obtener una buena visualización de datos de esto es complicado. Un gráfico de líneas apiladas parece ideal, aunque vale la pena señalar que run_one_frame mide múltiples tiempos ya medidos. Es útil jugar con el orden de los gráficos y colocar diferentes columnas en la parte inferior para ver mejor su efecto. Además, debe truncar el eje Y para obtener algo útil debido a algunos valores atípicos muy grandes.
Cosas interesantes a tener en cuenta:
- el tiempo de renderizado y el tiempo de ejecución parecen ser en su mayoría constantes, pero tienen picos cuando hay picos grandes en general. Sospecho que los picos grandes provienen simplemente de que todo se ralentiza por cualquier motivo
- El tiempo de transmisión parece estar bastante bien correlacionado con la forma general.
- El tiempo de espera también es parte de la razón por la que la forma general es así, es _mu_ ondulada
Manishearth
en 21 feb. 2020
Estado actual: con las correcciones de IPC, el FPS ahora ronda los 55. A veces se mueve mucho, pero por lo general no baja de 45, _excepto_ durante los primeros segundos después de la carga (donde puede bajar a 30), y cuando primero ve una mano (cuando baja a 20).
Manishearth
en 25 feb. 2020
Histograma más reciente para la demostración de pintura ( datos sin procesar ):
Name min max mean
raf queued 0.113854 5.707917 0.441650
<1ms: 352
<2ms: 13
<4ms: 5
<8ms: 1
<16ms: 0
<32ms: 0
32+ms: 0
raf transmitted 0.546667 44.954792 6.886162
<1ms: 4
<2ms: 2
<4ms: 23
<8ms: 279
<16ms: 59
<32ms: 3
32+ms: 1
raf wait 1.611667 37.913177 9.441104
<1ms: 0
<2ms: 6
<4ms: 98
<8ms: 82
<16ms: 135
<32ms: 43
32+ms: 6
raf execute 3.336562 418.198541 7.592147
<1ms: 0
<2ms: 0
<4ms: 11
<8ms: 319
<16ms: 36
<32ms: 2
32+ms: 3
raf receive 0.119323 9.804167 0.806074
<1ms: 324
<2ms: 31
<4ms: 13
<8ms: 1
<16ms: 1
<32ms: 0
32+ms: 0
swap request 0.003646 79.236354 0.761324
<1ms: 357
<2ms: 9
<4ms: 2
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 3
raf render 5.844687 172.898906 8.131682
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 283
<16ms: 86
<32ms: 1
32+ms: 1
run_one_frame 8.826198 2577.357604 25.922205
<1ms: 0
<2ms: 0
<4ms: 0
<8ms: 0
<16ms: 176
<32ms: 174
32+ms: 22
swap buffer 0.708177 12.528906 1.415950
<1ms: 164
<2ms: 161
<4ms: 38
<8ms: 4
<16ms: 4
<32ms: 0
32+ms: 0
swap complete 0.042917 1.554740 0.127729
<1ms: 370
<2ms: 1
<4ms: 0
<8ms: 0
<16ms: 0
<32ms: 0
32+ms: 0
Ejecución más larga (sin procesar ). Hecho para reducir el impacto de las ralentizaciones de inicio.
Nombre min max media
raf en cola 0.124896 6.356562 0.440674
<1 ms: 629
<2 ms: 13
<4 ms: 5
<8 ms: 1
<16 ms: 0
<32 ms: 0
32 + ms: 0
raf transmitido 0.640677 20.275104 6.944751
<1 ms: 2
<2 ms: 3
<4 ms: 29
<8 ms: 513
<16 ms: 99
<32 ms: 1
32 + ms: 0
raf espera 1.645886 40.955208 9.386255
<1 ms: 0
<2 ms: 10
<4 ms: 207
<8 ms: 114
<16 ms: 236
<32 ms: 65
32 + ms: 15
raf ejecutar 3.090104 526.041198 6.226997
<1 ms: 0
<2 ms: 0
<4 ms: 68
<8 ms: 546
<16 ms: 29
<32 ms: 1
32 + ms: 3
raf recibe 0,203334 6,441198 0,747615
<1 ms: 554
<2 ms: 84
<4 ms: 7
<8 ms: 2
<16 ms: 0
<32 ms: 0
32 + ms: 0
solicitud de intercambio 0,003490 73,644322 0,428460
<1 ms: 627
<2 ms: 18
<4 ms: 1
<8 ms: 0
<16 ms: 0
<32 ms: 0
32 + ms: 2
renderizado raf 5.450312 209.662969 8.055021
<1 ms: 0
<2 ms: 0
<4 ms: 0
<8 ms: 467
<16 ms: 176
<32 ms: 3
32 + ms: 1
run_one_frame 8.417291 2579.454948 22.226204
<1 ms: 0
<2 ms: 0
<4 ms: 0
<8 ms: 0
<16 ms: 326
<32 ms: 290
32 + ms: 33
búfer de intercambio 0,658125 12,179167 1,378725
<1 ms: 260
<2 ms: 308
<4 ms: 72
<8 ms: 4
<16 ms: 4
<32 ms: 0
32 + ms: 0
intercambio completo 0.041562 5.161458 0.136875
<1 ms: 642
<2 ms: 3
<4 ms: 1
<8 ms: 1
<16 ms: 0
<32 ms: 0
32 + ms: 0
Manishearth
en 27 feb. 2020
Gráficos:
Ejecución más larga:

Plazo más corto: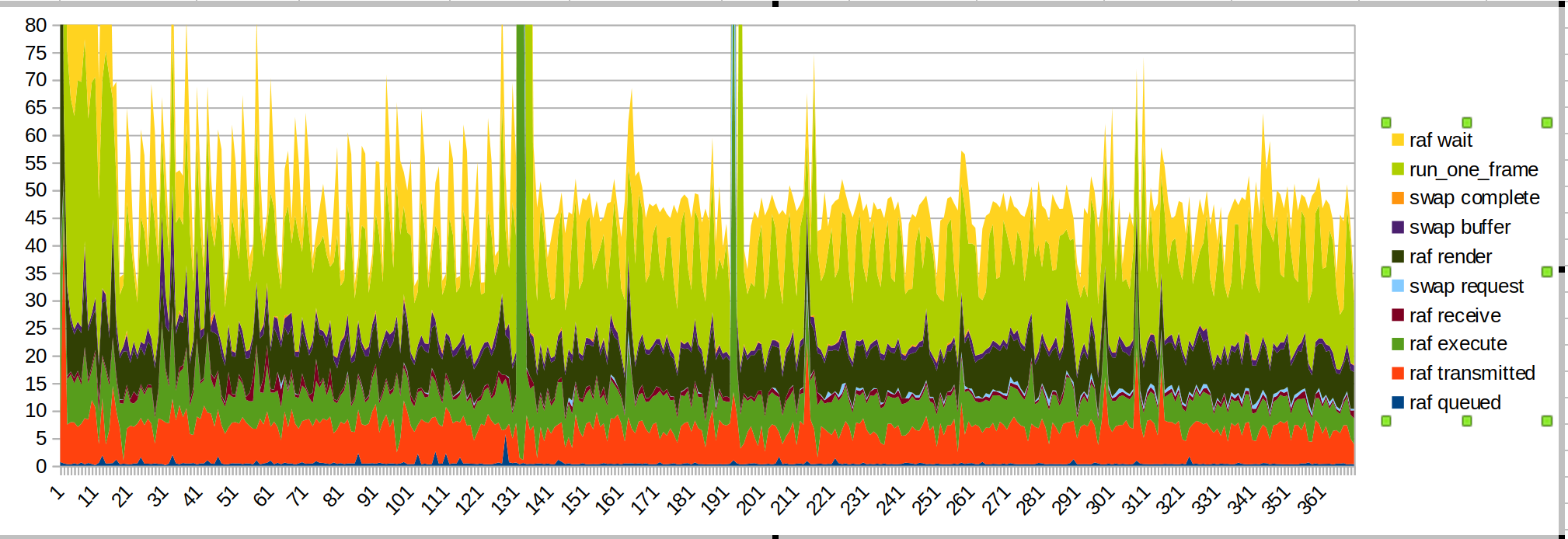
el gran pico es cuando pongo mi mano dentro del rango del sensor.
Esta vez coloqué los tiempos wait / run_one_frame en la parte superior porque son los más irregulares, y eso se debe a que el sistema operativo nos acelera.
Un par de cosas a tener en cuenta:
- El gran pico de las manos que se está introduciendo es causado por el código JS (verde albahaca, "render raf")
- el tiempo de transmisión se ha vuelto más fluido, como se esperaba
- cuando empiezo a dibujar hay otro pico de JS
- El tiempo de procesamiento y transmisión sigue siendo una parte importante del presupuesto. El rendimiento de la secuencia de comandos también podría mejorarse.
- Sospecho que el tiempo de transmisión es demasiado largo debido a que el hilo principal está ocupado haciendo otras cosas. Esto es https://github.com/servo/webxr/issues/113 , @jdm lo está investigando
- Las actualizaciones de surfman pueden mejorar los tiempos de renderizado. Las medidas de @asajeffrey en surfmanup parecen mejores que las mías
- compartir la superficie puede mejorar los tiempos de renderización (bloqueado en surfmanup)
- el FPS mostrado por el dispositivo se reduce casi a la mitad cuando se mide con xr-profile. Esto podría deberse a todo el IO.
Las torceduras de rendimiento debido a ver la mano y luego comenzar a dibujar no están presentes para el lanzador de bolas. ¿Quizás la demostración de pintura está funcionando mucho cuando decide dibujar la imagen de la mano por primera vez?
(Esta también podría ser la demostración de pintura que intenta interactuar con la biblioteca de entradas webxr)
Manishearth
en 27 feb. 2020
@Manishearth ¿También puede superponer el uso de la memoria y correlacionarlo con esos eventos? Además de la compilación por primera vez del código JS, es posible que esté fallando en una tonelada de código nuevo y se esté ejecutando contra los límites de memoria física e incurriendo en un montón de GC a medida que alcanza la presión de la memoria. Estaba viendo eso en la mayoría de situaciones no triviales. Espero que la actualización de SM de @nox ayude, ya que definitivamente fue un artefacto que vimos en esta compilación de SM en FxR Android.
larsbergstrom
en 27 feb. 2020
No tengo una manera fácil de obtener datos de perfiles de memoria de una manera que pueda correlacionarse con las cosas de perfiles xr.
Potencialmente, podría usar las herramientas de perforación existentes y averiguar si la forma es la misma.
Manishearth
en 27 feb. 2020
@Manishearth ¿El material de creación de perfiles xr muestra (o podría mostrar) eventos JS GC? Ese podría ser un proxy razonable.
larsbergstrom
en 27 feb. 2020
De cualquier manera, los picos de inicio no son mi principal preocupación, primero me gustaría obtener todo _else_ a 60 fps. Si está chiflado durante uno o dos segundos al inicio, es una preocupación menos urgente.
Manishearth
en 27 feb. 2020
Sí, podría mostrar eso, necesitaría algunos ajustes.
Manishearth
en 27 feb. 2020
@Manishearth ¡ Totalmente de acuerdo con las prioridades! No estaba seguro de si estabas intentando "deshacer los problemas" o reducir el estado estable. De acuerdo con este último más importante ahora mismo.
larsbergstrom
en 27 feb. 2020
No, principalmente estaba anotando todo el análisis que pude.
Manishearth
en 27 feb. 2020
Esos picos cerca del final del gráfico de la ejecución más pequeña donde el tiempo de transmisión también aumenta: fue entonces cuando estaba moviendo la cabeza y dibujando, y Alan también estaba notando caídas en FPS al hacer cosas, y lo atribuyó al sistema operativo haciendo otro trabajo . Después de que el IPC corrige mi presentimiento sobre los picos de tiempo de transmisión, es que son causados por el sistema operativo haciendo otro trabajo, por lo que podría ser lo que está sucediendo allí. En un mundo fuera del hilo principal, esperaría que fuera mucho más fluido.
Manishearth
en 27 feb. 2020
Ignóreme si esto ya se consideró, ¿ha pensado en desglosar la medida de run_one_frame por mensaje manejado, y también cronometrar el tiempo dedicado thread::sleep() -ing?
Podría valer la pena agregar tres puntos de medición:
una envoltura https://github.com/servo/webxr/blob/68b024221b8c72b5b33a63441d63803a13eadf03/webxr-api/session.rs#L364
y otro envoltorio https://github.com/servo/webxr/blob/2841497966d87bbd561f18ea66547dde9b13962f/webxr-api/lib.rs#L124 en su conjunto,
y también uno que envuelve la llamada a
thread::sleepsolamente.
En cuanto a los recv_timeout , esto podría ser algo para reconsiderar por completo.
Me resulta algo difícil razonar sobre la utilidad del tiempo de espera. Ya que está contando el marco renderizado, vea el frame_count , el caso de uso parecería ser "quizás manejar uno o varios mensajes que no están renderizando el marco, primero, seguido de renderizar un marco, evitando pasar por el ciclo de eventos completo del hilo principal "?
También tengo algunas dudas sobre el cálculo real de los delay usados en él, donde actualmente:
- comienza en
delay = timeout / 1000, contimeoutactualmente establecido en 5 ms - Luego crece exponencialmente, duplicándose en cada iteración a
delay = delay * 2; - Está marcado en la parte superior del ciclo con
while delay < timeout.
Entonces, la secuencia de inactividad, en el peor de los casos, es algo como: 5micro -> 10 -> 20 -> 40 -> 80 -> 160 -> 320 -> 640 -> 1.28milli -> 2.56 milli -> 5.12 milli
Cuando llegue a 5,12 milisegundos, saldrá del ciclo (desde delay > timeout ), habiendo esperado un total de 5,115 milisegundos, más el tiempo adicional que haya pasado esperando que el sistema operativo despierte el hilo después de cada sleep .
Así que creo que el problema es que puede estar durmiendo durante más de 5 ms en total, y también creo que no es una buena idea dormir dos veces durante más de 1 ms (y la segunda vez es más de 2,5 ms) desde que aparece un mensaje podría entrar durante ese tiempo y no se despertará.
No estoy muy seguro de cómo mejorarlo, parece que estás tratando de girar en busca de un mensaje potencial y, finalmente, pasar a la siguiente iteración del bucle de eventos principal si no hay nada disponible (¿por qué no bloquear en el recv?).
Puede cambiar para usar https://doc.rust-lang.org/std/thread/fn.yield_now.html , mirando este artículo sobre bloqueos , parece girar unas 40 veces mientras llama a yield cada vez , es óptimo (consulte el párrafo "Girar", no se puede vincular directamente a él). Después de eso, debe bloquear el receptor o simplemente continuar con la iteración actual del bucle de eventos (ya que se ejecuta como un sub bucle dentro del bucle de eventos de incrustación principal).
(obviamente, si no está midiendo con ipc activado, la parte anterior en recv_timeout es irrelevante, aunque es posible que desee medir la llamada a recv_timeout en el mpsc ya que el canal enhebrado hará algunos giros / rendimientos internos que también podrían influir en los resultados. Y dado que una "corrección de IPC" no identificada se mencionó en varias ocasiones anteriormente, supongo que está midiendo con ipc).
gterzian
en 27 feb. 2020
Ignóreme si esto ya se consideró, ¿ha pensado en desglosar la medición de run_one_frame por mensaje manejado, y también cronometrar el tiempo dedicado a thread :: sleep () - ing?
Ya está desglosado, los tiempos de espera / renderización son precisamente estos. Un solo tick de run_one_frame es un renderizado, una espera y un número indeterminado de eventos que se manejan (raro).
recv_timeout es una buena idea para la medición
Manishearth
en 27 feb. 2020
Lamentablemente, la actualización de spidermonkey en # 25678 no parece ser una mejora significativa: el FPS promedio de cada demostración, excepto la más restringida de memoria, disminuyó; la demostración de Hill Valley aumentó ligeramente. Ejecutar Servo con -Z gc-profile en los argumentos de inicialización no muestra ninguna diferencia en el comportamiento de GC entre el maestro y la rama de actualización de spidermonkey; no se informan GC después de que se haya cargado y mostrado el contenido de GL.
jdm
en 3 mar. 2020
Medidas para varias ramas:
master:
- espilit: 14-16 fps
- paint: 39-45 fps
- ball shooter: 30-40 fps
- hill valley: 8 fps, 200mb free mem
- mansion: 10-14fps, 650mb free mem
master + single swapchain:
- espilit: 10-12 fps
- paint: 29-55 fps, 1.2gb free mem
- ball shooter: 25-35 fps, 1.3gb free mem
- hill valley: 6-7 fps, 200mb free mem
- mansion: 10-11 fps, 700mb free mem
texture sharing + ANGLE 2.1.19:
- espilit: 13-15 fps, 670mb free mem
- paint: 39-45 fps
- ball shooter: 30-37 fps, 1.3gb free mem
- hill valley: 9-10 fps, 188mb free mem
- mansion: 13-14 fps, 671mb free mem
smup:
- espilit: 11-13 fps, 730mb free mem
- paint: 25-42 fps, 1.1gb free mem
- ball shooter: 26-30 fps, 1.4gb free mem
- hill valley: 10-11 fps, 145mb
- mansion: 9-11fps, 680mb free mem
¿¿El smup empeoró el rendimiento ???
asajeffrey
en 3 mar. 2020
Con los cambios de https://github.com/servo/servo/pull/25855#issuecomment -594203492, existe el resultado interesante de que la desactivación del Ion JIT comienza a 12 FPS, y luego, varios segundos después, se reduce abruptamente a 1 FPS y se queda ahí.
jdm
en 3 mar. 2020
Hice algunas medidas con esos parches.
En la pintura, obtengo 60 fps cuando no hay mucho contenido a la vista, y cuando miro el contenido dibujado, desciende a 50 fps (los picos amarillos son cuando miro el contenido dibujado). Es difícil saber por qué, sobre todo parece que el tiempo de espera se ve afectado por la aceleración de openxr, pero las otras cosas no parecen lo suficientemente lentas como para causar un problema. El tiempo de solicitud de intercambio es un poco más lento. El tiempo de ejecución de rAF es lento inicialmente (esta es la desaceleración inicial "primera vez que se ve un controlador") pero después de eso es bastante constante. Parece que openxr solo nos está estrangulando, pero no hay una desaceleración visible en otros lugares que pueda causar eso.

Manishearth
en 7 mar. 2020
Esto es lo que tengo para la demostración de arrastre. La escala y es la misma. Aquí es mucho más obvio que el tiempo de ejecución nos está frenando.

Manishearth
en 7 mar. 2020
Una cosa a tener en cuenta es que estaba tomando medidas con el número 25837 aplicado y podría afectar el rendimiento.
jdm
en 7 mar. 2020
No lo estaba, sin embargo, estaba obteniendo resultados similares a los tuyos.
Manishearth
en 7 mar. 2020
Gráficos de herramientas de rendimiento para el momento en el que pasa de 60FPS a 45FPS al mirar contenido:
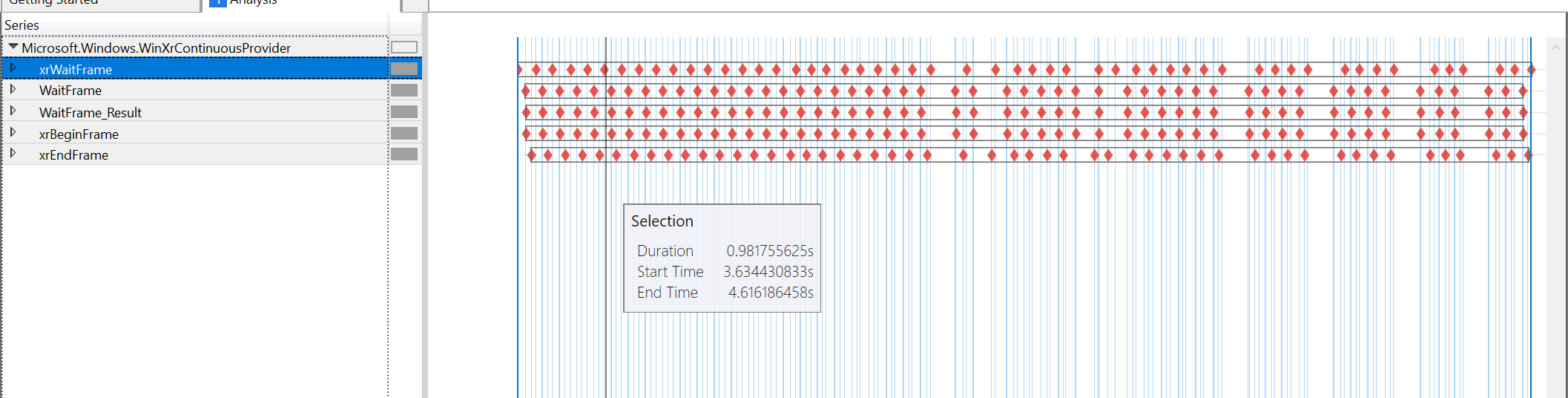
parece que la culpa es completamente de xrWaitFrame, todos los demás tiempos están bastante cerca. El xrBeginFrame todavía está casi inmediatamente después de xrWaitFrame, el xrEndFrame es 4us después del xrBeginFrame (en ambos casos). El siguiente xrWaitFrame es casi inmediatamente después del xrEndFrame. La única brecha no contabilizada es la causada por el propio xrWaitFrame.
Manishearth
en 11 mar. 2020
Con la demostración de arrastre, obtengo el siguiente rastro:

Esta es la demostración de pintura con la misma escala:
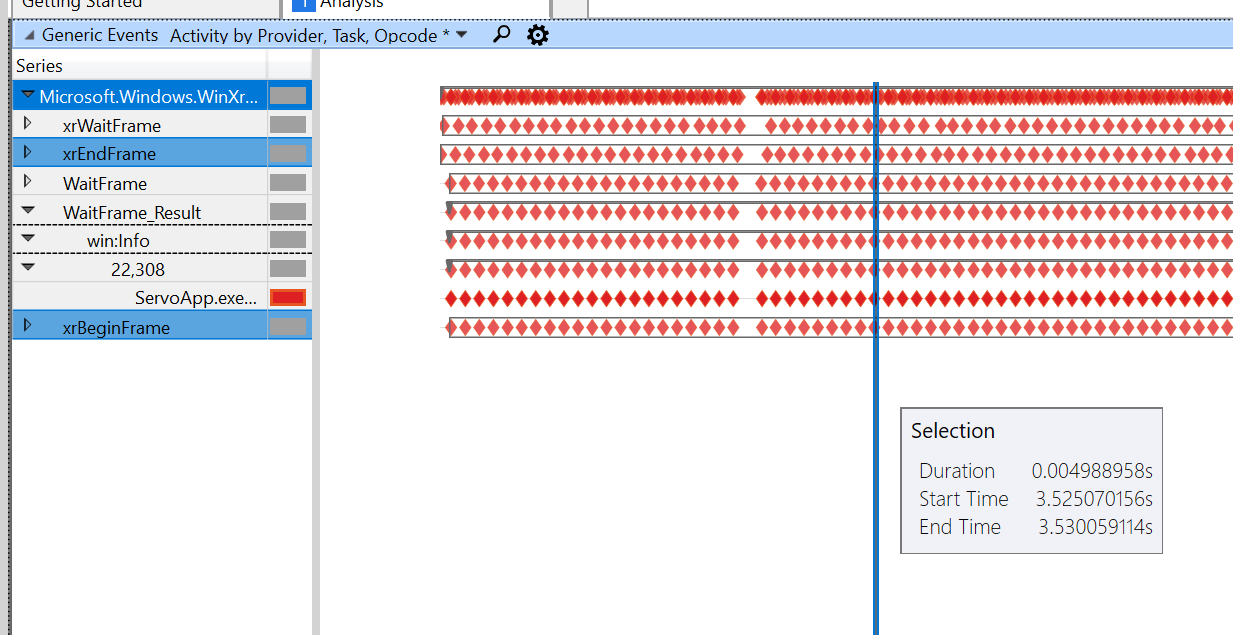
Somos lentos entre el fotograma inicial / final (¡de 5 ms a 38 ms en el más rápido!), Y luego se activa la limitación del fotograma de espera. Todavía no he descubierto por qué este es el caso, estoy revisando el código para ambos.
Manishearth
en 18 mar. 2020
La demostración de arrastre se ralentiza porque su fuente de luz proyecta una sombra. Las cosas de la sombra se hacen en el lado GL, por lo que no estoy seguro de que podamos acelerarlo fácilmente.
Manishearth
en 18 mar. 2020
Si se hace completamente a través de GLSL, es posible que tengamos dificultades; si se realiza en cada fotograma a través de las API de WebGL, es posible que haya lugares para optimizar.
jdm
en 18 mar. 2020
Sí, parece que todo está del lado GLSL; No pude ver ninguna llamada WebGL cuando se trata de cómo funcionan las API de sombra, solo algunos bits que se transmiten a los sombreadores
Manishearth
en 19 mar. 2020
Creo que esto se ha abordado en general. Podemos presentar problemas para demostraciones individuales que necesitan trabajo.
jdm
en 20 jul. 2020
Temas relacionados
 CYBAI
·
4Comentarios
CYBAI
·
4Comentarios
 noisiak
·
3Comentarios
gterzian
·
4Comentarios
noisiak
·
3Comentarios
gterzian
·
4Comentarios
 ayelen912
·
3Comentarios
ayelen912
·
3Comentarios
 roberto68
·
3Comentarios
roberto68
·
3Comentarios
Comentario más útil
Estado actual: con las correcciones de IPC, el FPS ahora ronda los 55. A veces se mueve mucho, pero por lo general no baja de 45, _excepto_ durante los primeros segundos después de la carga (donde puede bajar a 30), y cuando primero ve una mano (cuando baja a 20).