Xgboost: predicción diferente en v1.2.1 y rama maestra
Estoy usando la versión 1.2.1 lanzada para el desarrollo debido a su fácil instalación en Python y también escribo un código c simple para la predicción usando c_api. Si está vinculado a v1.2.1 libxgboost.so, la diferencia de las predicciones entre python y c es exactamente cero. Sin embargo, si está vinculado a libxgboost.so desde la rama maestra (confirme f3a425398 el 5 de noviembre de 2020), hay una diferencia.
Me gustaría implementar el código c en un sistema real usando la rama maestra, ya que me gustaría construir una biblioteca estática, y ahora la diferencia de las predicciones entre v1.2.1 y la rama maestra me obstaculiza.
Gracias.
 7starsea
7starsea
Todos 35 comentarios
¿Puede publicar un programa de ejemplo para que podamos reproducir el error?
 hcho3
en 6 nov. 2020
hcho3
en 6 nov. 2020
Además, ¿ve diferentes predicciones de la versión maestra del paquete Python y la API C?
hcho3
en 6 nov. 2020
Se han realizado algunas optimizaciones en el predictor de la CPU, que pueden generar un resultado diferente por un error de punto flotante diferente. Pero sí, ¿tienes un ejemplo reproducible?
 trivialfis
en 6 nov. 2020
trivialfis
en 6 nov. 2020
Además, ¿ve diferentes predicciones de la versión maestra del paquete Python y la API C?
Estoy comparando la v1.2.1 del paquete python y la rama maestra de la API C.
7starsea
en 6 nov. 2020
@ 7starsea ¿Puedes comparar también las salidas de la API de Python y C, ambas de la rama maestra? El problema podría ser la forma en que se utilizan las funciones de la API de C en su aplicación.
hcho3
en 6 nov. 2020
@ 7starsea ¿Puedes comparar también las salidas de la API de Python y C, ambas de la rama maestra? El problema podría ser la forma en que se utilizan las funciones de la API de C en su aplicación.
Comparé python y c api, ambas de v1.2.1 y las predicciones son exactamente las mismas.
7starsea
en 6 nov. 2020
@ 7starsea Lo tengo. Si publica programas Python y C que predicen desde el mismo modelo, podremos solucionar el problema aún más.
hcho3
en 6 nov. 2020
@ hcho3 aquí está el código de prueba
7starsea
en 6 nov. 2020
@ 7starsea Acabo de probar tu ejemplo y obtuve el siguiente resultado:
difference: [0. 0. 0. 0.] 0.0 0.0
Usé la última confirmación de XGBoost (debeae2509d90ec1d3402a3a185fba7a25113ff1).
hcho3
en 12 nov. 2020
@ 7starsea Acabo de probar tu ejemplo y obtuve el siguiente resultado:
difference: [0. 0. 0. 0.] 0.0 0.0Usé la última confirmación de XGBoost ( debeae2 ).
Interesante, ¿es su versión de Python v1.2.1?
Todavía tengo alguna diferencia entre python-versión 1.2.1 y c api vinculada a XGBoost ( debeae2 ).
7starsea
en 12 nov. 2020
@ 7starsea No, compilé XGBoost de la última fuente (commit debeae2509d90ec1d3402a3a185fba7a25113ff1), por lo que es más reciente que la v1.2.1. Mi paquete XGBoost Python imprime 1.3.0-SNAPSHOT para el campo xgboost.__version__ .
hcho3
en 12 nov. 2020
@ hcho3 Me pregunto si XGBoost debería mantener una predicción consistente entre diferentes versiones (al menos versiones consecutivas).
También se espera el lanzamiento de v1.3.0.
(parece que necesito entrenar el modelo usando la rama maestra ahora)
Gracias por tu tiempo.
7starsea
en 12 nov. 2020
@ 7starsea Si carga un modelo guardado de una versión anterior, debería poder obtener una predicción coherente.
No pude reproducir el problema con su secuencia de comandos. ¿Puedes intentar crear una imagen de Docker o una imagen de VM y compartirla conmigo?
hcho3
en 12 nov. 2020
@ 7starsea FYI, también intenté construir XGBoost 1.2.1 desde la fuente, de la siguiente manera:
git clone --recursive https://github.com/dmlc/xgboost -b release_1.2.0 xgb_source
cd xgb_source
mkdir build
cd build
cmake ..
make
cd ../python-package
python setup.py install
Los resultados muestran nuevamente difference: [0. 0. 0. 0.] 0.0 0.0
hcho3
en 12 nov. 2020
Para ver la diferencia, necesita dos versiones de XGBoost, v1.2.1 para python y
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest) # # internally using libxgboost.so v1.2.1
y uno para cpp
m1 = XgbShannonPredictor(fname)
y2 = m1.predict(rx2) # # internally using libxgboost.so from the master branch (debeae2)
Intentaré crear una imagen de la ventana acoplable (que es nueva para mí).
7starsea
en 12 nov. 2020
Déjame ver.
trivialfis
en 12 nov. 2020
Intentaré crear una imagen de la ventana acoplable (que es nueva para mí).
No es necesario.
trivialfis
en 12 nov. 2020
De hecho, logré reproducir el problema. Resulta que la versión de desarrollo de XGBoost produce una predicción diferente a la de XGBoost 1.2.0. Y el problema es simple de reproducir; no es necesario utilizar la API de C.
Ejemplo reproducible (EDITAR: establecer la semilla aleatoria):
import numpy as np
import xgboost as xgb
rng = np.random.default_rng(seed=2020)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest)
print(xgb.__version__)
print(y1)
Salida de 1.2.0:
1.2.0
[ 0.00698659 -0.00211251 0.00180039 -0.00016004 0.00526169 0.00801963
0.00016755 0.00226218 0.00276762 0.00408182 0.00303206 0.00291929
0.01101092 0.0068329 0.00145864 0.00326979 0.00572816 0.01019934
0.00074345 0.00784767 0.00173795 -0.00219297 0.0060181 0.00606489
0.00447372 0.00103396 0.00932363 0.00230178 0.00389203 0.00151157
0.0034163 0.00821933 0.006686 0.00630778 0.00331488 0.00775066
0.00443819 0.01030204 0.00924486 0.00645933 0.00777653 0.00231206
0.00457835 0.00390425 0.00947028 0.00410065 0.00220913 0.00292507
0.00637993 0.00796807 0.00140873 0.00887537 0.00496858 0.01049942
0.00908098 0.00332722 0.00799242 0.00228494 0.00463879 0.00213429
0.00729388 0.01049232 0.00790522 0.01269361 -0.00425893 0.00256333
0.00859573 0.00472835 0.00077197 0.00191873 0.01546788 0.0014475
0.00888193 0.00648022 0.00115797 0.00351191 0.00580138 0.00614035
0.00632426 0.00408354 0.00346044 -0.00034332 0.00599384 0.00302595
0.00657633 0.01086903 0.00625807 0.00096565 0.00061804 0.00038511
0.00523874 0.00633043 0.00379965 0.00302553 -0.00123322 0.00153473
0.00725579 0.00836438 0.01295918 0.00737873]
Nota. ejecutar el script con XGBoost 1.0.0 y 1.1.0 da como resultado el mismo resultado que 1.2.0.
Salida de la versión dev (c5645180a6afb9d3d771165e681985fe3522adf6)
1.3.0-SNAPSHOT
[ 0.00698666 -0.00211278 0.00180034 -0.00016027 0.00526194 0.00801962
0.00016758 0.00226211 0.00276773 0.00408198 0.00303223 0.00291933
0.01101091 0.00683288 0.00145871 0.00326988 0.00572827 0.01019943
0.00074329 0.00784767 0.00173803 -0.00219286 0.00601804 0.00606472
0.00447388 0.00103391 0.00932358 0.00230171 0.003892 0.00151177
0.00341637 0.00821943 0.00668607 0.00630774 0.00331502 0.00775074
0.0044381 0.01030211 0.00924495 0.00645958 0.00777672 0.00231205
0.00457842 0.00390424 0.00947046 0.00410091 0.0022092 0.00292498
0.00638005 0.00796804 0.00140869 0.00887531 0.00496863 0.01049942
0.00908096 0.00332738 0.00799218 0.00228496 0.004639 0.00213413
0.00729368 0.01049243 0.00790528 0.01269368 -0.00425872 0.00256319
0.00859569 0.00472848 0.0007721 0.00191874 0.01546813 0.00144742
0.00888212 0.00648021 0.00115819 0.00351191 0.00580168 0.00614044
0.00632418 0.0040833 0.00346038 -0.00034315 0.00599405 0.00302578
0.0065765 0.01086897 0.00625799 0.00096572 0.00061766 0.00038494
0.00523901 0.00633054 0.00379964 0.00302567 -0.00123339 0.00153471
0.00725584 0.00836433 0.01295913 0.00737863]
@ hcho3 ¿Quieres investigarlo? Puedo ayudar a bisecar si es necesario.
trivialfis
en 12 nov. 2020
Espera un segundo, olvidé establecer la semilla aleatoria en mi reproducción. Tonto de mí.
hcho3
en 12 nov. 2020
Actualicé mi reproducción con la semilla aleatoria fija. El error aún persiste. Intenté ejecutar la reproducción actualizada con XGBoost 1.0.0 y 1.1.0, y las predicciones concuerdan con la predicción de XGBoost 1.2.0.
En breve:
Prediction from 1.0.0
== Prediction from 1.1.0
== Prediction from 1.2.0
!= Prediction from latest master
@trivialfis Sí, su ayuda será apreciada.
hcho3
en 12 nov. 2020
Marcando esto como bloqueo.
hcho3
en 12 nov. 2020
Entendido.
trivialfis
en 12 nov. 2020
Rastreado hasta a4ce0eae43f7e0e2f91566ef2360830b86b9fdcf. @ShvetsKS ¿Le gustaría echar un vistazo?
trivialfis
en 12 nov. 2020
Rastreada hasta @ShvetsKS ¿Le gustaría echar un vistazo?
Seguro. ¿Podrías ayudarme a entrenar el modelo desde el reproductor de Python?
m2.load_model('xgb.model.bin') # load data
¿Qué versión de XGBoost se utiliza para el entrenamiento y qué parámetros deben proporcionarse exactamente?
 ShvetsKS
en 12 nov. 2020
ShvetsKS
en 12 nov. 2020
@ShvetsKS Puede obtener el archivo de modelo xgb.model.bin en https://github.com/7starsea/xgboost-testing. El modelo se entrenó con 1.0.0.
hcho3
en 12 nov. 2020
@ShvetsKS Puede obtener el archivo de modelo
xgb.model.binen https://github.com/7starsea/xgboost-testing. El modelo se entrenó con 1.0.0.
el modelo fue realmente entrenado con 1.2.1 y parámetros
param = {'max_depth': 8, 'eta': 0.1, 'min_child_weight': 2, 'gamma': 1e-8, 'subsample': 0.6, 'nthread': 4}
Gracias.
7starsea
en 12 nov. 2020
Parece que la pequeña diferencia se debe a un cambio en la secuencia de operación de coma flotante.
_ Razón exacta: _
Antes de a4ce0ea, incrementamos las respuestas de todos los árboles en la variable local psum (inicialmente igual a cero) y luego incrementamos el valor apropiado de out_preds .
En a4ce0ea incrementamos los valores out_preds directamente por cada respuesta de árbol.
La corrección está preparada: https://github.com/dmlc/xgboost/pull/6384
@ 7starsea gracias por encontrar la diferencia, ¿podrías revisar la solución anterior?
@ hcho3 , @trivialfis ¿Consideramos que esta diferencia es crítica en el futuro? Parece que es una restricción significativa que no permite cambiar la secuencia de operaciones de punto flotante para inferencia. Pero para la etapa de entrenamiento no existe tal requisito que yo recuerde.
ShvetsKS
en 12 nov. 2020
¿Consideramos que esa diferencia es crítica en el futuro?
Normalmente no. Déjame echar un vistazo a tus cambios. ;-)
trivialfis
en 12 nov. 2020
@ShvetsKS Acabo de verificar y la diferencia es exactamente cero ahora. Gracias por arreglar la diferencia de predicción.
7starsea
en 12 nov. 2020
@ShvetsKS
¿Consideramos que esa diferencia es crítica en el futuro? Parece que es una restricción significativa que no permite cambiar la secuencia de operaciones de punto flotante para inferencia
De hecho, nosotros ( @RAMitchell , @trivialfis y yo) estamos de acuerdo con usted aquí. Obligar a la reproducibilidad exacta de la predicción obstaculizará gravemente nuestra capacidad para realizar cambios. La aritmética de punto flotante es famosa por no asociar, por lo que la suma de una lista de números será ligeramente diferente según el orden de la suma.
He realizado un experimento para cuantificar cuánto cambia la predicción entre XGBoost 1.2.0 y la última rama master :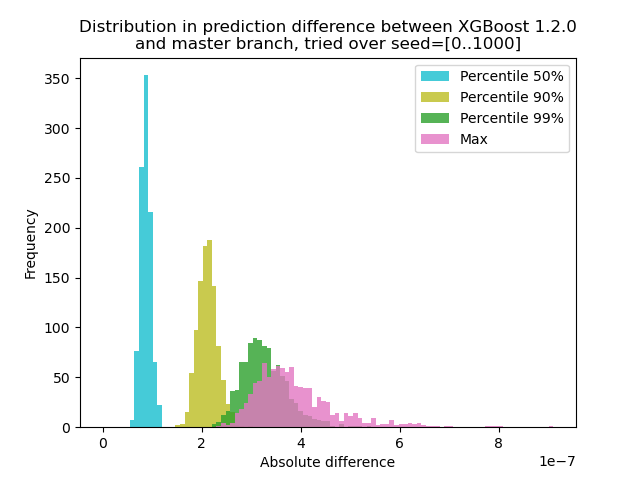
Genere datos con 1000 semillas aleatorias diferentes y luego ejecuté la predicción con las 1000 matrices, usando ambas versiones 1.2.0 y master. El cambio en la predicción cambia levemente entre semillas, pero la diferencia nunca es superior a 9.2e-7, por lo que lo más probable es que el cambio de predicción se deba a una aritmética de punto flotante y no a un error lógico .
Guión para el experimento
** test.py **: Genere 1000 matrices con diferentes semillas aleatorias y ejecute predicciones para ellas.
import numpy as np
import xgboost as xgb
import argparse
def main(args):
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
out = {}
for seed in range(1000):
rng = np.random.default_rng(seed=seed)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
dtest = xgb.DMatrix(rx, missing=0.0)
out[str(seed)] = m2.predict(dtest)
np.savez(args.out_pred, **out)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--out-pred', type=str, required=True)
args = parser.parse_args()
main(args)
import numpy as np
import matplotlib.pyplot as plt
xgb120 = np.load('xgb120.npz')
xgblatest = np.load('xgblatest.npz')
percentile_pts = [50, 90, 99]
colors = ['tab:cyan', 'tab:olive', 'tab:green', 'tab:pink']
percentile = {}
for x in percentile_pts:
percentile[x] = []
percentile['max'] = []
for seed in range(1000):
diff = np.abs(xgb120[str(seed)] - xgblatest[str(seed)])
t = np.percentile(diff, percentile_pts)
for x, y in zip(percentile_pts, t):
percentile[x].append(y)
percentile['max'].append(np.max(diff))
bins = np.linspace(0, np.max(percentile['max']), 100)
idx = 0
for x in percentile_pts:
plt.hist(percentile[x], label=f'Percentile {x}%', bins=bins, alpha=0.8, color=colors[idx])
idx += 1
plt.hist(percentile['max'], label='Max', bins=bins, alpha=0.8, color=colors[idx])
plt.legend(loc='best')
plt.title('Distribution in prediction difference between XGBoost 1.2.0\nand master branch, tried over seed=[0..1000]')
plt.xlabel('Absolute difference')
plt.ylabel('Frequency')
plt.savefig('foobar.png', dpi=100)
Dado que aquí el problema es que + con flotante no forma un grupo, podemos probar con la suma eliminada: Predecir en un solo árbol. El resultado debería ser exactamente el mismo.
trivialfis
en 13 nov. 2020
@trivialfis De hecho, cuando agregué ntree_limit=1 argumento a m2.predict() , la diferencia se desvanece a 0.
hcho3
en 13 nov. 2020
¡Estupendo! Entonces, lo siguiente es cómo lo documentamos o si debemos documentarlo.
trivialfis
en 13 nov. 2020
Déjame dormir en eso. Por ahora, basta con decir que este problema no es realmente un error.
hcho3
en 13 nov. 2020
Temas relacionados
 yananchen1989
·
3Comentarios
yananchen1989
·
3Comentarios
 nnorton24
·
3Comentarios
nnorton24
·
3Comentarios
 frankzhangrui
·
3Comentarios
frankzhangrui
·
3Comentarios
 vkuznet
·
3Comentarios
vkuznet
·
3Comentarios
 XiaoxiaoWang87
·
3Comentarios
XiaoxiaoWang87
·
3Comentarios
Comentario más útil
@ShvetsKS
De hecho, nosotros ( @RAMitchell , @trivialfis y yo) estamos de acuerdo con usted aquí. Obligar a la reproducibilidad exacta de la predicción obstaculizará gravemente nuestra capacidad para realizar cambios. La aritmética de punto flotante es famosa por no asociar, por lo que la suma de una lista de números será ligeramente diferente según el orden de la suma.
He realizado un experimento para cuantificar cuánto cambia la predicción entre XGBoost 1.2.0 y la última rama

master:Genere datos con 1000 semillas aleatorias diferentes y luego ejecuté la predicción con las 1000 matrices, usando ambas versiones 1.2.0 y master. El cambio en la predicción cambia levemente entre semillas, pero la diferencia nunca es superior a 9.2e-7, por lo que lo más probable es que el cambio de predicción se deba a una aritmética de punto flotante y no a un error lógico .
Guión para el experimento
** test.py **: Genere 1000 matrices con diferentes semillas aleatorias y ejecute predicciones para ellas.
Comando: `python test.py --out-pred [out.npz]`. Asegúrese de que su entorno Python tenga la versión correcta de XGBoost. Supongamos que `xgb120.npz` almacena el resultado de XGBoost 1.2.0 y que` xgblatest.npz` almacena el resultado del último maestro. ** compare.py **: haga un gráfico de histograma para la diferencia de predicción