Xgboost: prediksi berbeda di v1.2.1 dan cabang master
Saya menggunakan versi 1.2.1 yang dirilis untuk pengembangan karena pemasangannya yang mudah di python dan saya juga menulis kode c sederhana untuk prediksi menggunakan file c_api. Jika ditautkan ke v1.2.1 libxgboost.so, perbedaan prediksi antara python dan c persis nol. Namun, jika ditautkan ke libxgboost.so dari cabang master (komit f3a425398 pada 5 November 2020), ada perbedaan.
Saya ingin menyebarkan kode c dalam sistem nyata menggunakan cabang master karena saya ingin membangun lib statis, dan sekarang perbedaan prediksi antara v1.2.1 dan cabang master menghalangi saya.
Terima kasih.
 7starsea
7starsea
Semua 35 komentar
Bisakah Anda memposting contoh program sehingga kami dapat mereproduksi bug?
 hcho3
pada 6 Nov 2020
hcho3
pada 6 Nov 2020
Juga, apakah Anda melihat prediksi yang berbeda dari versi master paket Python dan C API?
hcho3
pada 6 Nov 2020
Ada beberapa optimasi yang dilakukan pada prediktor CPU, mungkin menghasilkan hasil yang berbeda dengan kesalahan floating point yang berbeda. Tapi ya, apakah Anda memiliki contoh yang dapat direproduksi?
 trivialfis
pada 6 Nov 2020
trivialfis
pada 6 Nov 2020
Juga, apakah Anda melihat prediksi yang berbeda dari versi master paket Python dan C API?
Saya membandingkan paket python v1.2.1 dan cabang master C API.
7starsea
pada 6 Nov 2020
@7starsea Bisakah Anda juga membandingkan output dari Python dan C API, keduanya dari cabang master? Masalahnya mungkin cara fungsi C API digunakan dalam aplikasi Anda.
hcho3
pada 6 Nov 2020
@7starsea Bisakah Anda juga membandingkan output dari Python dan C API, keduanya dari cabang master? Masalahnya mungkin cara fungsi C API digunakan dalam aplikasi Anda.
Saya membandingkan python dan c api, keduanya dari v1.2.1 dan prediksinya sama persis.
7starsea
pada 6 Nov 2020
@7starsea Mengerti. Jika Anda memposting program Python dan C yang memprediksi dari model yang sama, kami akan dapat memecahkan masalah lebih lanjut.
hcho3
pada 6 Nov 2020
@hcho3 di sini adalah kode pengujian
7starsea
pada 6 Nov 2020
@7starsea Saya baru saja mencoba contoh Anda dan mendapatkan hasil berikut:
difference: [0. 0. 0. 0.] 0.0 0.0
Saya menggunakan komit terbaru XGBoost (debeae2509d90ec1d3402a3a185fba7a25113ff1).
hcho3
pada 12 Nov 2020
@7starsea Saya baru saja mencoba contoh Anda dan mendapatkan hasil berikut:
difference: [0. 0. 0. 0.] 0.0 0.0Saya menggunakan komit terbaru XGBoost ( debeae2 ).
Menarik, apakah python versi v1.2.1 Anda?
Saya masih memiliki beberapa perbedaan antara python-versi 1.2.1 dan c api yang ditautkan ke XGBoost ( debeae2 ).
7starsea
pada 12 Nov 2020
@7starsea Tidak, saya mengkompilasi XGBoost dari sumber terbaru (commit debeae2509d90ec1d3402a3a185fba7a25113ff1), jadi ini lebih baru daripada v1.2.1. Paket XGBoost Python saya mencetak 1.3.0-SNAPSHOT untuk bidang xgboost.__version__ .
hcho3
pada 12 Nov 2020
@hcho3 Saya bertanya-tanya haruskah XGBoost menjaga prediksi yang konsisten antara versi yang berbeda (setidaknya versi berurutan)?
Juga mengharapkan rilis v1.3.0.
(Sepertinya saya perlu melatih model menggunakan cabang master sekarang)
Terima kasih atas waktunya.
7starsea
pada 12 Nov 2020
@7starsea Jika Anda memuat model yang disimpan dari versi sebelumnya, Anda harus dapat memperoleh prediksi yang konsisten.
Saya tidak dapat mereproduksi masalah menggunakan skrip Anda. Bisakah Anda mencoba membuat image Docker atau image VM dan membagikannya dengan saya?
hcho3
pada 12 Nov 2020
@7starsea FYI, saya juga mencoba membangun XGBoost 1.2.1 dari sumbernya, sebagai berikut:
git clone --recursive https://github.com/dmlc/xgboost -b release_1.2.0 xgb_source
cd xgb_source
mkdir build
cd build
cmake ..
make
cd ../python-package
python setup.py install
Hasilnya kembali menunjukkan difference: [0. 0. 0. 0.] 0.0 0.0
hcho3
pada 12 Nov 2020
Untuk melihat perbedaannya, Anda memerlukan dua versi XGBoost, v1.2.1 untuk python dan
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest) # # internally using libxgboost.so v1.2.1
dan satu untuk cpp
m1 = XgbShannonPredictor(fname)
y2 = m1.predict(rx2) # # internally using libxgboost.so from the master branch (debeae2)
Saya akan mencoba membuat gambar buruh pelabuhan (yang baru bagi saya).
7starsea
pada 12 Nov 2020
Mari saya lihat.
trivialfis
pada 12 Nov 2020
Saya akan mencoba membuat gambar buruh pelabuhan (yang baru bagi saya).
Tidak perlu.
trivialfis
pada 12 Nov 2020
Sebenarnya, saya berhasil mereproduksi masalah. Ternyata XGBoost versi dev menghasilkan prediksi yang berbeda dengan XGBoost 1.2.0. Dan masalahnya sederhana untuk direproduksi; tidak perlu menggunakan C API.
Contoh yang dapat direproduksi (EDIT: menyetel benih acak):
import numpy as np
import xgboost as xgb
rng = np.random.default_rng(seed=2020)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest)
print(xgb.__version__)
print(y1)
Keluaran dari 1.2.0:
1.2.0
[ 0.00698659 -0.00211251 0.00180039 -0.00016004 0.00526169 0.00801963
0.00016755 0.00226218 0.00276762 0.00408182 0.00303206 0.00291929
0.01101092 0.0068329 0.00145864 0.00326979 0.00572816 0.01019934
0.00074345 0.00784767 0.00173795 -0.00219297 0.0060181 0.00606489
0.00447372 0.00103396 0.00932363 0.00230178 0.00389203 0.00151157
0.0034163 0.00821933 0.006686 0.00630778 0.00331488 0.00775066
0.00443819 0.01030204 0.00924486 0.00645933 0.00777653 0.00231206
0.00457835 0.00390425 0.00947028 0.00410065 0.00220913 0.00292507
0.00637993 0.00796807 0.00140873 0.00887537 0.00496858 0.01049942
0.00908098 0.00332722 0.00799242 0.00228494 0.00463879 0.00213429
0.00729388 0.01049232 0.00790522 0.01269361 -0.00425893 0.00256333
0.00859573 0.00472835 0.00077197 0.00191873 0.01546788 0.0014475
0.00888193 0.00648022 0.00115797 0.00351191 0.00580138 0.00614035
0.00632426 0.00408354 0.00346044 -0.00034332 0.00599384 0.00302595
0.00657633 0.01086903 0.00625807 0.00096565 0.00061804 0.00038511
0.00523874 0.00633043 0.00379965 0.00302553 -0.00123322 0.00153473
0.00725579 0.00836438 0.01295918 0.00737873]
Catatan. menjalankan skrip dengan XGBoost 1.0.0 dan 1.1.0 menghasilkan keluaran yang sama dengan 1.2.0.
Keluaran dari versi dev (c5645180a6afb9d3d771165e681985fe3522adf6)
1.3.0-SNAPSHOT
[ 0.00698666 -0.00211278 0.00180034 -0.00016027 0.00526194 0.00801962
0.00016758 0.00226211 0.00276773 0.00408198 0.00303223 0.00291933
0.01101091 0.00683288 0.00145871 0.00326988 0.00572827 0.01019943
0.00074329 0.00784767 0.00173803 -0.00219286 0.00601804 0.00606472
0.00447388 0.00103391 0.00932358 0.00230171 0.003892 0.00151177
0.00341637 0.00821943 0.00668607 0.00630774 0.00331502 0.00775074
0.0044381 0.01030211 0.00924495 0.00645958 0.00777672 0.00231205
0.00457842 0.00390424 0.00947046 0.00410091 0.0022092 0.00292498
0.00638005 0.00796804 0.00140869 0.00887531 0.00496863 0.01049942
0.00908096 0.00332738 0.00799218 0.00228496 0.004639 0.00213413
0.00729368 0.01049243 0.00790528 0.01269368 -0.00425872 0.00256319
0.00859569 0.00472848 0.0007721 0.00191874 0.01546813 0.00144742
0.00888212 0.00648021 0.00115819 0.00351191 0.00580168 0.00614044
0.00632418 0.0040833 0.00346038 -0.00034315 0.00599405 0.00302578
0.0065765 0.01086897 0.00625799 0.00096572 0.00061766 0.00038494
0.00523901 0.00633054 0.00379964 0.00302567 -0.00123339 0.00153471
0.00725584 0.00836433 0.01295913 0.00737863]
@hcho3 Apakah Anda ingin melihat ke dalamnya? Saya dapat membantu membagi dua jika diperlukan.
trivialfis
pada 12 Nov 2020
Tunggu sebentar, saya lupa mengatur seed acak di repro saya. Saya konyol.
hcho3
pada 12 Nov 2020
Saya memperbarui repro saya dengan seed acak tetap. Bugnya masih berlanjut. Saya mencoba menjalankan repro yang diperbarui dengan XGBoost 1.0.0 dan 1.1.0, dan prediksinya sesuai dengan prediksi dari XGBoost 1.2.0.
Pendeknya:
Prediction from 1.0.0
== Prediction from 1.1.0
== Prediction from 1.2.0
!= Prediction from latest master
@trivialfis Ya, bantuan Anda akan dihargai.
hcho3
pada 12 Nov 2020
Menandai ini sebagai pemblokiran.
hcho3
pada 12 Nov 2020
Mengerti.
trivialfis
pada 12 Nov 2020
Dilacak ke a4ce0eae43f7e0e2f91566ef2360830b86b9fdcf . @ShvetsKS Apakah Anda ingin melihatnya?
trivialfis
pada 12 Nov 2020
Dilacak ke @ShvetsKS Apakah Anda ingin melihatnya?
Tentu. Bisakah Anda membantu melatih model dari reproduksi python:
m2.load_model('xgb.model.bin') # load data
Versi XGBoost apa yang digunakan untuk pelatihan dan parameter mana yang harus disediakan dengan tepat?
 ShvetsKS
pada 12 Nov 2020
ShvetsKS
pada 12 Nov 2020
@ShvetsKS Anda dapat memperoleh file model xgb.model.bin dari https://github.com/7starsea/xgboost-testing. Model dilatih dengan 1.0.0.
hcho3
pada 12 Nov 2020
@ShvetsKS Anda dapat memperoleh file model
xgb.model.bindari https://github.com/7starsea/xgboost-testing. Model dilatih dengan 1.0.0.
model sebenarnya dilatih dengan 1.2.1 dan parameter
param = {'max_depth': 8, 'eta': 0.1, 'min_child_weight': 2, 'gamma': 1e-8, 'subsample': 0.6, 'nthread': 4}
Terima kasih.
7starsea
pada 12 Nov 2020
Tampaknya perbedaan kecil ini disebabkan oleh perubahan urutan operasi floating point.
_Alasan yang tepat:_
Sebelum a4ce0ea kami menambahkan semua respons pohon ke variabel lokal psum (awalnya sama dengan nol) dan kemudian menaikkan nilai yang sesuai dari out_preds .
Di a4ce0ea kami menaikkan nilai out_preds secara langsung oleh setiap respons pohon.
Perbaikan disiapkan: https://github.com/dmlc/xgboost/pull/6384
@7starsea terima kasih telah menemukan perbedaannya, dapatkah Anda memeriksa perbaikan di atas?
@hcho3 , @trivialfis Apakah kita menganggap perbedaan seperti itu penting di masa depan? Tampaknya itu adalah batasan signifikan yang tidak mengizinkan perubahan urutan operasi floating point untuk inferensi. Tapi untuk tahap pelatihan tidak ada persyaratan seperti yang saya ingat.
ShvetsKS
pada 12 Nov 2020
Apakah kita menganggap perbedaan seperti itu penting di masa depan?
Biasanya tidak. Biarkan saya melihat perubahan Anda. ;-)
trivialfis
pada 12 Nov 2020
@ShvetsKS Saya baru saja memeriksa dan perbedaannya persis nol sekarang. Terima kasih telah memperbaiki perbedaan prediksi.
7starsea
pada 12 Nov 2020
@ShvetsKS
Apakah kita menganggap perbedaan seperti itu penting di masa depan? Sepertinya itu batasan signifikan yang tidak mengizinkan perubahan urutan operasi floating point untuk inferensi
Memang, kami ( @RAMitchell , @trivialfis , dan saya) setuju dengan Anda di sini. Mengamanatkan reproduktifitas prediksi yang tepat akan sangat menghambat kemampuan kita untuk membuat perubahan. Aritmatika titik-mengambang terkenal non-asosiatif, sehingga jumlah daftar angka akan sedikit berbeda tergantung pada urutan penambahan.
Saya telah menjalankan eksperimen untuk mengukur seberapa besar perubahan prediksi antara XGBoost 1.2.0 dan cabang master :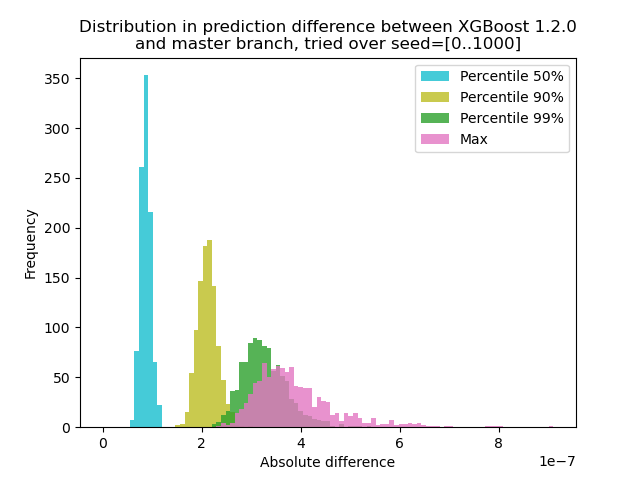
Saya menghasilkan data dengan 1000 biji acak yang berbeda dan kemudian menjalankan prediksi dengan 1000 matriks, menggunakan versi 1.2.0 dan master. Perubahan prediksi sedikit berubah di antara benih, tetapi perbedaannya tidak pernah lebih dari 9.2e-7, jadi kemungkinan besar perubahan prediksi disebabkan oleh aritmatika titik-mengambang dan bukan kesalahan logika .
Skrip untuk percobaan
**test.py**: Hasilkan 1000 matriks dengan seed acak yang berbeda dan jalankan prediksi untuknya.
import numpy as np
import xgboost as xgb
import argparse
def main(args):
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
out = {}
for seed in range(1000):
rng = np.random.default_rng(seed=seed)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
dtest = xgb.DMatrix(rx, missing=0.0)
out[str(seed)] = m2.predict(dtest)
np.savez(args.out_pred, **out)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--out-pred', type=str, required=True)
args = parser.parse_args()
main(args)
import numpy as np
import matplotlib.pyplot as plt
xgb120 = np.load('xgb120.npz')
xgblatest = np.load('xgblatest.npz')
percentile_pts = [50, 90, 99]
colors = ['tab:cyan', 'tab:olive', 'tab:green', 'tab:pink']
percentile = {}
for x in percentile_pts:
percentile[x] = []
percentile['max'] = []
for seed in range(1000):
diff = np.abs(xgb120[str(seed)] - xgblatest[str(seed)])
t = np.percentile(diff, percentile_pts)
for x, y in zip(percentile_pts, t):
percentile[x].append(y)
percentile['max'].append(np.max(diff))
bins = np.linspace(0, np.max(percentile['max']), 100)
idx = 0
for x in percentile_pts:
plt.hist(percentile[x], label=f'Percentile {x}%', bins=bins, alpha=0.8, color=colors[idx])
idx += 1
plt.hist(percentile['max'], label='Max', bins=bins, alpha=0.8, color=colors[idx])
plt.legend(loc='best')
plt.title('Distribution in prediction difference between XGBoost 1.2.0\nand master branch, tried over seed=[0..1000]')
plt.xlabel('Absolute difference')
plt.ylabel('Frequency')
plt.savefig('foobar.png', dpi=100)
Karena di sini masalahnya adalah + dengan float tidak membentuk grup, kita dapat menguji dengan jumlah yang dihapus: Memprediksi pada satu pohon. Hasilnya harus persis sama.
trivialfis
pada 13 Nov 2020
@trivialfi Memang, ketika saya menambahkan argumen ntree_limit=1 ke m2.predict() , perbedaannya hilang menjadi 0.
hcho3
pada 13 Nov 2020
Besar! Jadi hal selanjutnya adalah bagaimana kita mendokumentasikannya atau apakah kita harus mendokumentasikannya.
trivialfis
pada 13 Nov 2020
Biarkan aku tidur di atasnya. Untuk saat ini, cukup untuk mengatakan bahwa masalah ini sebenarnya bukan bug.
hcho3
pada 13 Nov 2020
Masalah terkait
 XiaoxiaoWang87
·
3Komentar
XiaoxiaoWang87
·
3Komentar
 matthewmav
·
3Komentar
matthewmav
·
3Komentar
 RanaivosonHerimanitra
·
3Komentar
trivialfis
·
3Komentar
RanaivosonHerimanitra
·
3Komentar
trivialfis
·
3Komentar
 nnorton24
·
3Komentar
nnorton24
·
3Komentar
Komentar yang paling membantu
@ShvetsKS
Memang, kami ( @RAMitchell , @trivialfis , dan saya) setuju dengan Anda di sini. Mengamanatkan reproduktifitas prediksi yang tepat akan sangat menghambat kemampuan kita untuk membuat perubahan. Aritmatika titik-mengambang terkenal non-asosiatif, sehingga jumlah daftar angka akan sedikit berbeda tergantung pada urutan penambahan.
Saya telah menjalankan eksperimen untuk mengukur seberapa besar perubahan prediksi antara XGBoost 1.2.0 dan cabang

master:Saya menghasilkan data dengan 1000 biji acak yang berbeda dan kemudian menjalankan prediksi dengan 1000 matriks, menggunakan versi 1.2.0 dan master. Perubahan prediksi sedikit berubah di antara benih, tetapi perbedaannya tidak pernah lebih dari 9.2e-7, jadi kemungkinan besar perubahan prediksi disebabkan oleh aritmatika titik-mengambang dan bukan kesalahan logika .
Skrip untuk percobaan
**test.py**: Hasilkan 1000 matriks dengan seed acak yang berbeda dan jalankan prediksi untuknya.
Perintah: `python test.py --out-pred [out.npz]`. Pastikan env Python Anda memiliki versi XGBoost yang benar. Mari kita asumsikan bahwa `xgb120.npz` menyimpan hasil untuk XGBoost 1.2.0 dan `xgblatest.npz` menyimpan hasil untuk master terbaru. **compare.py**: Buat plot histogram untuk perbedaan prediksi