Pythonに簡単にインストールできるため、リリースされたバージョン1.2.1を開発に使用しています。また、c_apiを使用して予測用の単純なcコードを記述しています。 v1.2.1 libxgboost.soにリンクされている場合、pythonとcの予測の差は正確にゼロです。 ただし、マスターブランチからlibxgboost.soにリンクされている場合(2020年11月5日にf3a425398をコミット)、違いがあります。
静的ライブラリを構築したいので、マスターブランチを使用して実際のシステムにcコードをデプロイしたいと思います。現在、v1.2.1とマスターブランチの予測の違いが妨げになっています。
ありがとう。
 7starsea
7starsea
全てのコメント35件
バグを再現できるように、サンプルプログラムを投稿していただけますか?
 hcho3
2020年11月06日
hcho3
2020年11月06日
また、PythonパッケージのマスターバージョンとC APIとは異なる予測が見られますか?
hcho3
2020年11月06日
CPU予測子で行われるいくつかの最適化があり、異なる浮動小数点エラーによって異なる結果を生成する可能性があります。 しかし、ええ、再現可能な例はありますか?
 trivialfis
2020年11月06日
trivialfis
2020年11月06日
また、PythonパッケージのマスターバージョンとC APIとは異なる予測が見られますか?
Pythonパッケージのv1.2.1とCAPIのマスターブランチを比較しています。
7starsea
2020年11月06日
@ 7starseaまた、マスターブランチからのPythonとC APIからの出力を比較できますか? 問題は、アプリケーションでのCAPI関数の使用方法にある可能性があります。
hcho3
2020年11月06日
@ 7starseaまた、マスターブランチからのPythonとC APIからの出力を比較できますか? 問題は、アプリケーションでのCAPI関数の使用方法にある可能性があります。
pythonとcapiを比較しましたが、どちらもv1.2.1からのものであり、予測はまったく同じです。
7starsea
2020年11月06日
@ 7starsea了解しました。 同じモデルから予測するPythonプログラムとCプログラムの両方を投稿すると、問題をさらにトラブルシューティングできるようになります。
hcho3
2020年11月06日
@ hcho3はここにテストコードです
7starsea
2020年11月06日
@ 7starsea私はあなたの例を試したところ、次の出力が得られました。
difference: [0. 0. 0. 0.] 0.0 0.0
XGBoostの最新のコミット(debeae2509d90ec1d3402a3a185fba7a25113ff1)を使用しました。
hcho3
2020年11月12日
@ 7starsea私はあなたの例を試したところ、次の出力が得られました。
difference: [0. 0. 0. 0.] 0.0 0.0XGBoost( debeae2 )の最新のコミットを使用しました。
興味深いことに、Pythonバージョンv1.2.1はありますか?
python- version1.2.1とXGBoost( capiの間にはまだいくつかの違いがあります。
7starsea
2020年11月12日
@ 7starseaいいえ、最新のソース(commit debeae2509d90ec1d3402a3a185fba7a25113ff1)からXGBoostをコンパイルしたので、v1.2.1よりも新しいです。 私のXGBoostPythonパッケージ1.3.0-SNAPSHOT 、 xgboost.__version__フィールドに1.3.0-SNAPSHOTを出力します。
hcho3
2020年11月12日
@ hcho3 XGBoostは異なるバージョン(少なくとも連続したバージョン)間で一貫した予測を維持する必要があるのでしょうか?
また、v1.3.0のリリースを期待しています。
(マスターブランチを使用してモデルをトレーニングする必要があるようです)
御時間ありがとうございます。
7starsea
2020年11月12日
@ 7starsea以前のバージョンから保存されたモデルをロードすると、一貫した予測を取得できるはずです。
スクリプトを使用して問題を再現できませんでした。 DockerイメージまたはVMイメージを作成して、それを私と共有してみてください。
hcho3
2020年11月12日
@ 7starsea参考までに、次のように、ソースから
git clone --recursive https://github.com/dmlc/xgboost -b release_1.2.0 xgb_source
cd xgb_source
mkdir build
cd build
cmake ..
make
cd ../python-package
python setup.py install
結果は再びdifference: [0. 0. 0. 0.] 0.0 0.0
hcho3
2020年11月12日
違いを確認するには、XGBoostの2つのバージョン、Python用のv1.2.1と
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest) # # internally using libxgboost.so v1.2.1
1つはcpp用です
m1 = XgbShannonPredictor(fname)
y2 = m1.predict(rx2) # # internally using libxgboost.so from the master branch (debeae2)
Dockerイメージを作成しようとします(これは私にとっては新しいことです)。
7starsea
2020年11月12日
見せてください。
trivialfis
2020年11月12日
Dockerイメージを作成しようとします(これは私にとっては新しいことです)。
必要はありません。
trivialfis
2020年11月12日
実際、私はなんとか問題を再現することができました。 XGBoostの開発バージョンはXGBoost1.2.0とは異なる予測を生成することがわかりました。 そして、問題は簡単に再現できます。 CAPIを使用する必要はありません。
再現可能な例(編集:ランダムシードの設定):
import numpy as np
import xgboost as xgb
rng = np.random.default_rng(seed=2020)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest)
print(xgb.__version__)
print(y1)
1.2.0からの出力:
1.2.0
[ 0.00698659 -0.00211251 0.00180039 -0.00016004 0.00526169 0.00801963
0.00016755 0.00226218 0.00276762 0.00408182 0.00303206 0.00291929
0.01101092 0.0068329 0.00145864 0.00326979 0.00572816 0.01019934
0.00074345 0.00784767 0.00173795 -0.00219297 0.0060181 0.00606489
0.00447372 0.00103396 0.00932363 0.00230178 0.00389203 0.00151157
0.0034163 0.00821933 0.006686 0.00630778 0.00331488 0.00775066
0.00443819 0.01030204 0.00924486 0.00645933 0.00777653 0.00231206
0.00457835 0.00390425 0.00947028 0.00410065 0.00220913 0.00292507
0.00637993 0.00796807 0.00140873 0.00887537 0.00496858 0.01049942
0.00908098 0.00332722 0.00799242 0.00228494 0.00463879 0.00213429
0.00729388 0.01049232 0.00790522 0.01269361 -0.00425893 0.00256333
0.00859573 0.00472835 0.00077197 0.00191873 0.01546788 0.0014475
0.00888193 0.00648022 0.00115797 0.00351191 0.00580138 0.00614035
0.00632426 0.00408354 0.00346044 -0.00034332 0.00599384 0.00302595
0.00657633 0.01086903 0.00625807 0.00096565 0.00061804 0.00038511
0.00523874 0.00633043 0.00379965 0.00302553 -0.00123322 0.00153473
0.00725579 0.00836438 0.01295918 0.00737873]
ノート。 XGBoost 1.0.0および1.1.0でスクリプトを実行すると、1.2.0と同じ出力になります。
開発バージョンからの出力(c5645180a6afb9d3d771165e681985fe3522adf6)
1.3.0-SNAPSHOT
[ 0.00698666 -0.00211278 0.00180034 -0.00016027 0.00526194 0.00801962
0.00016758 0.00226211 0.00276773 0.00408198 0.00303223 0.00291933
0.01101091 0.00683288 0.00145871 0.00326988 0.00572827 0.01019943
0.00074329 0.00784767 0.00173803 -0.00219286 0.00601804 0.00606472
0.00447388 0.00103391 0.00932358 0.00230171 0.003892 0.00151177
0.00341637 0.00821943 0.00668607 0.00630774 0.00331502 0.00775074
0.0044381 0.01030211 0.00924495 0.00645958 0.00777672 0.00231205
0.00457842 0.00390424 0.00947046 0.00410091 0.0022092 0.00292498
0.00638005 0.00796804 0.00140869 0.00887531 0.00496863 0.01049942
0.00908096 0.00332738 0.00799218 0.00228496 0.004639 0.00213413
0.00729368 0.01049243 0.00790528 0.01269368 -0.00425872 0.00256319
0.00859569 0.00472848 0.0007721 0.00191874 0.01546813 0.00144742
0.00888212 0.00648021 0.00115819 0.00351191 0.00580168 0.00614044
0.00632418 0.0040833 0.00346038 -0.00034315 0.00599405 0.00302578
0.0065765 0.01086897 0.00625799 0.00096572 0.00061766 0.00038494
0.00523901 0.00633054 0.00379964 0.00302567 -0.00123339 0.00153471
0.00725584 0.00836433 0.01295913 0.00737863]
@ hcho3調べてみませんか? 必要に応じて二等分するのを手伝うことができます。
trivialfis
2020年11月12日
ちょっと待ってください、私は私の再現でランダムシードを設定するのを忘れました。 愚かな私。
hcho3
2020年11月12日
固定のランダムシードで再現を更新しました。 バグはまだ残っています。 更新された再現をXGBoost1.0.0および1.1.0で実行してみましたが、予測はXGBoost1.2.0からの予測と一致しています。
要するに:
Prediction from 1.0.0
== Prediction from 1.1.0
== Prediction from 1.2.0
!= Prediction from latest master
@trivialfisはい、あなたの助けを
hcho3
2020年11月12日
これをブロッキングとしてマークします。
hcho3
2020年11月12日
とった。
trivialfis
2020年11月12日
a4ce0eae43f7e0e2f91566ef2360830b86b9fdcfにトレースされます。 @ShvetsKS見てみませんか?
trivialfis
2020年11月12日
a4ce0eaにトレースされ@ShvetsKS見てみませんか?
もちろん。 Pythonリプロデューサーからモデルをトレーニングするのを手伝ってもらえますか?
m2.load_model('xgb.model.bin') # load data
トレーニングに使用されるXGBoostのバージョンと、正確に提供する必要のあるパラメーターはどれですか?
 ShvetsKS
2020年11月12日
ShvetsKS
2020年11月12日
@ShvetsKSモデルファイルxgb.model.binはhttps://github.com/7starsea/xgboost-testingから入手でき
hcho3
2020年11月12日
@ShvetsKSモデルファイル
xgb.model.binはhttps://github.com/7starsea/xgboost-testingから入手でき
モデルは実際に1.2.1とパラメータでトレーニングされました
param = {'max_depth': 8, 'eta': 0.1, 'min_child_weight': 2, 'gamma': 1e-8, 'subsample': 0.6, 'nthread': 4}
ありがとう。
7starsea
2020年11月12日
わずかな違いは、浮動小数点演算のシーケンスの変更によるものと思われます。
_正確な理由:_
a4ce0eaの前に、すべてのツリー応答をローカル変数psum (最初はゼロに等しい)にインクリメントし、次にout_predsから適切な値をインクリメントします。
a4ce0eaでは、ツリーの応答ごとにout_preds値を直接インクリメントします。
修正が準備されています: https :
@ 7starsea違いを見つけてくれてありがとう、上記の修正を確認できますか?
@ hcho3、@trivialfisは、我々は将来的に重要なこのような違いを考慮していますか? 推論のために浮動小数点演算のシーケンスを変更できないという重大な制限のようです。 しかし、トレーニング段階では、私が覚えているような要件はありません。
ShvetsKS
2020年11月12日
今後、そのような違いは重大だと思いますか?
通常はありません。 あなたの変化を見てみましょう。 ;-)
trivialfis
2020年11月12日
@ShvetsKSチェックしたところ、違いはまったくゼロになりました。 予測の違いを修正していただきありがとうございます。
7starsea
2020年11月12日
@ShvetsKS
今後、そのような違いは重大だと思いますか? 推論のための浮動小数点演算のシーケンスを変更できないという重大な制限のようです
確かに、私たち( @ RAMitchell 、 @ trivialfis 、および私)はここであなたに同意します。 予測の正確な再現性を義務付けると、変更を加える能力が大幅に妨げられます。 浮動小数点演算は結合法則がないことで有名なため、数値のリストの合計は、加算の順序によってわずかに異なります。
XGBoost 1.2.0と最新のmasterブランチの間で予測がどの程度変化するかを定量化するための実験を実行しました。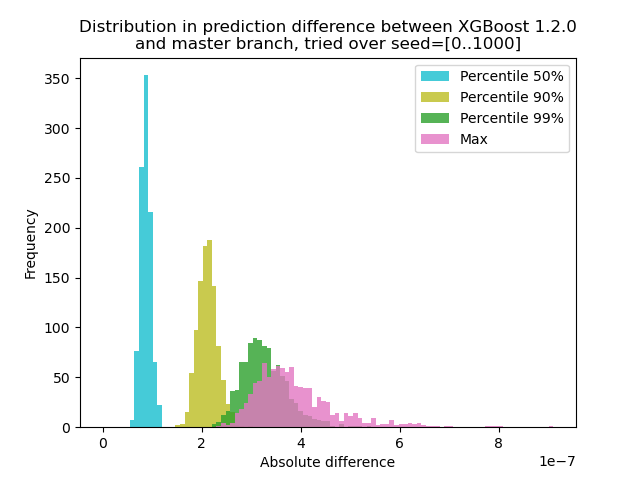
1000の異なるランダムシードを使用してデータを生成し、バージョン1.2.0とマスターの両方を使用して1000の行列を使用して予測を実行しました。 予測の変化はシード間でわずかに変化しますが、その差が9.2e-7を超えることはないため、予測の変化は、論理エラーではなく浮動小数点演算によって引き起こされた可能性があります。
実験用スクリプト
** test.py **:さまざまなランダムシードを使用して1000個の行列を生成し、それらの予測を実行します。
import numpy as np
import xgboost as xgb
import argparse
def main(args):
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
out = {}
for seed in range(1000):
rng = np.random.default_rng(seed=seed)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
dtest = xgb.DMatrix(rx, missing=0.0)
out[str(seed)] = m2.predict(dtest)
np.savez(args.out_pred, **out)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--out-pred', type=str, required=True)
args = parser.parse_args()
main(args)
import numpy as np
import matplotlib.pyplot as plt
xgb120 = np.load('xgb120.npz')
xgblatest = np.load('xgblatest.npz')
percentile_pts = [50, 90, 99]
colors = ['tab:cyan', 'tab:olive', 'tab:green', 'tab:pink']
percentile = {}
for x in percentile_pts:
percentile[x] = []
percentile['max'] = []
for seed in range(1000):
diff = np.abs(xgb120[str(seed)] - xgblatest[str(seed)])
t = np.percentile(diff, percentile_pts)
for x, y in zip(percentile_pts, t):
percentile[x].append(y)
percentile['max'].append(np.max(diff))
bins = np.linspace(0, np.max(percentile['max']), 100)
idx = 0
for x in percentile_pts:
plt.hist(percentile[x], label=f'Percentile {x}%', bins=bins, alpha=0.8, color=colors[idx])
idx += 1
plt.hist(percentile['max'], label='Max', bins=bins, alpha=0.8, color=colors[idx])
plt.legend(loc='best')
plt.title('Distribution in prediction difference between XGBoost 1.2.0\nand master branch, tried over seed=[0..1000]')
plt.xlabel('Absolute difference')
plt.ylabel('Frequency')
plt.savefig('foobar.png', dpi=100)
ここでの問題は、floatを使用した+がグループを形成しないことであるため、合計を削除してテストできます。単一のツリーで予測します。 結果はまったく同じになるはずです。
trivialfis
2020年11月13日
@trivialfis確かに、 ntree_limit=1引数をm2.predict()に追加すると、差は0になります。
hcho3
2020年11月13日
素晴らしい! 次は、どのように文書化するか、または文書化する必要があるかどうかです。
trivialfis
2020年11月13日
その上で眠らせてください。 今のところ、この問題は実際にはバグではないと言えば十分です。
hcho3
2020年11月13日
関連する問題
 Str1ker17
·
3コメント
Str1ker17
·
3コメント
 lizsz
·
3コメント
lizsz
·
3コメント
 wenbo5565
·
3コメント
wenbo5565
·
3コメント
 choushishi
·
3コメント
choushishi
·
3コメント
 mhnamaki
·
3コメント
mhnamaki
·
3コメント
最も参考になるコメント
@ShvetsKS
確かに、私たち( @ RAMitchell 、 @ trivialfis 、および私)はここであなたに同意します。 予測の正確な再現性を義務付けると、変更を加える能力が大幅に妨げられます。 浮動小数点演算は結合法則がないことで有名なため、数値のリストの合計は、加算の順序によってわずかに異なります。
XGBoost 1.2.0と最新の

masterブランチの間で予測がどの程度変化するかを定量化するための実験を実行しました。1000の異なるランダムシードを使用してデータを生成し、バージョン1.2.0とマスターの両方を使用して1000の行列を使用して予測を実行しました。 予測の変化はシード間でわずかに変化しますが、その差が9.2e-7を超えることはないため、予測の変化は、論理エラーではなく浮動小数点演算によって引き起こされた可能性があります。
実験用スクリプト
** test.py **:さまざまなランダムシードを使用して1000個の行列を生成し、それらの予測を実行します。
コマンド: `python test.py --out-pred [out.npz]`。 Python環境に正しいバージョンのXGBoostが含まれていることを確認してください。 `xgb120.npz`がXGBoost1.2.0の結果を保存し、` xgblatest.npz`が最新のマスターの結果を保存すると仮定します。 ** compare.py **:予測差のヒストグラムプロットを作成します