Xgboost: prediction different in v1.2.1 and master branch
I am using the released version 1.2.1 for development due to its easy installation in python and I also write a simple c code for prediction using the c_api. If linked to v1.2.1 libxgboost.so, the difference of the predictions between python and c is exactly zero. However, if linked to libxgboost.so from the master branch (commit f3a425398 at Nov. 5, 2020), there is a difference.
I would like to deploy the c code in real system using the master branch since I would like to build a static lib, and now the difference of the predictions between v1.2.1 and master branch hinders me.
Thanks.
 7starsea
7starsea
All 35 comments
Can you post an example program so that we can reproduce the bug?
 hcho3
on 6 Nov 2020
hcho3
on 6 Nov 2020
Also, do you see different predictions from the master version of Python package and the C API?
hcho3
on 6 Nov 2020
There are some optimization done on the CPU predictor, might generate different result by different floating point error. But yeah, do you have a reproducible example?
 trivialfis
on 6 Nov 2020
trivialfis
on 6 Nov 2020
Also, do you see different predictions from the master version of Python package and the C API?
I am comparing the v1.2.1 of python package and the master branch of C API.
7starsea
on 6 Nov 2020
@7starsea Can you also compare the outputs from the Python and C API, both from the master branch? The issue could be the way C API functions are used in your application.
hcho3
on 6 Nov 2020
@7starsea Can you also compare the outputs from the Python and C API, both from the master branch? The issue could be the way C API functions are used in your application.
I compared the python and c api, both from v1.2.1 and the predictions are exactly the same.
7starsea
on 6 Nov 2020
@7starsea Got it. If you post both Python and C programs that predict from the same model, we'd be able to troubleshoot the issue further.
hcho3
on 6 Nov 2020
@hcho3 here is the testing code
7starsea
on 6 Nov 2020
@7starsea I just tried your example and got the following output:
difference: [0. 0. 0. 0.] 0.0 0.0
I used the latest commit of XGBoost (debeae2509d90ec1d3402a3a185fba7a25113ff1).
hcho3
on 12 Nov 2020
@7starsea I just tried your example and got the following output:
difference: [0. 0. 0. 0.] 0.0 0.0I used the latest commit of XGBoost (debeae2).
Interesting, is your python version v1.2.1?
I still have some difference between python-version 1.2.1 and c api linked to XGBoost (debeae2).
7starsea
on 12 Nov 2020
@7starsea No, I compiled XGBoost from the latest source (commit debeae2509d90ec1d3402a3a185fba7a25113ff1), so it's more recent than v1.2.1. My XGBoost Python package prints 1.3.0-SNAPSHOT for xgboost.__version__ field.
hcho3
on 12 Nov 2020
@hcho3 I am wondering should XGBoost keep consistent prediction between different versions (at least consecutive versions) ?
Also expecting the release of v1.3.0.
(seems I need to train the model using the master branch now)
Thanks for your time.
7starsea
on 12 Nov 2020
@7starsea If you load a saved model from a previous version, you should be able to obtain the consistent prediction.
I wasn't able to reproduce the issue using your script. Can you try building a Docker image or a VM image and share it with me?
hcho3
on 12 Nov 2020
@7starsea FYI, I also tried building XGBoost 1.2.1 from the source, as follows:
git clone --recursive https://github.com/dmlc/xgboost -b release_1.2.0 xgb_source
cd xgb_source
mkdir build
cd build
cmake ..
make
cd ../python-package
python setup.py install
The results again show difference: [0. 0. 0. 0.] 0.0 0.0
hcho3
on 12 Nov 2020
To see the difference, you need two versions of XGBoost, v1.2.1 for python and
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest) # # internally using libxgboost.so v1.2.1
and one for cpp
m1 = XgbShannonPredictor(fname)
y2 = m1.predict(rx2) # # internally using libxgboost.so from the master branch (debeae2)
I will try to build a docker image (which is new to me).
7starsea
on 12 Nov 2020
Let me take a look.
trivialfis
on 12 Nov 2020
I will try to build a docker image (which is new to me).
Not necessary.
trivialfis
on 12 Nov 2020
Actually, I managed to reproduce the problem. It turns out that the dev version of XGBoost produces a different prediction than XGBoost 1.2.0. And the problem is simple to reproduce; no need to use the C API.
Reproducible example (EDIT: setting the random seed):
import numpy as np
import xgboost as xgb
rng = np.random.default_rng(seed=2020)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest)
print(xgb.__version__)
print(y1)
Output from 1.2.0:
1.2.0
[ 0.00698659 -0.00211251 0.00180039 -0.00016004 0.00526169 0.00801963
0.00016755 0.00226218 0.00276762 0.00408182 0.00303206 0.00291929
0.01101092 0.0068329 0.00145864 0.00326979 0.00572816 0.01019934
0.00074345 0.00784767 0.00173795 -0.00219297 0.0060181 0.00606489
0.00447372 0.00103396 0.00932363 0.00230178 0.00389203 0.00151157
0.0034163 0.00821933 0.006686 0.00630778 0.00331488 0.00775066
0.00443819 0.01030204 0.00924486 0.00645933 0.00777653 0.00231206
0.00457835 0.00390425 0.00947028 0.00410065 0.00220913 0.00292507
0.00637993 0.00796807 0.00140873 0.00887537 0.00496858 0.01049942
0.00908098 0.00332722 0.00799242 0.00228494 0.00463879 0.00213429
0.00729388 0.01049232 0.00790522 0.01269361 -0.00425893 0.00256333
0.00859573 0.00472835 0.00077197 0.00191873 0.01546788 0.0014475
0.00888193 0.00648022 0.00115797 0.00351191 0.00580138 0.00614035
0.00632426 0.00408354 0.00346044 -0.00034332 0.00599384 0.00302595
0.00657633 0.01086903 0.00625807 0.00096565 0.00061804 0.00038511
0.00523874 0.00633043 0.00379965 0.00302553 -0.00123322 0.00153473
0.00725579 0.00836438 0.01295918 0.00737873]
Note. running the script with XGBoost 1.0.0 and 1.1.0 results in the identical output as 1.2.0.
Output from the dev version (c5645180a6afb9d3d771165e681985fe3522adf6)
1.3.0-SNAPSHOT
[ 0.00698666 -0.00211278 0.00180034 -0.00016027 0.00526194 0.00801962
0.00016758 0.00226211 0.00276773 0.00408198 0.00303223 0.00291933
0.01101091 0.00683288 0.00145871 0.00326988 0.00572827 0.01019943
0.00074329 0.00784767 0.00173803 -0.00219286 0.00601804 0.00606472
0.00447388 0.00103391 0.00932358 0.00230171 0.003892 0.00151177
0.00341637 0.00821943 0.00668607 0.00630774 0.00331502 0.00775074
0.0044381 0.01030211 0.00924495 0.00645958 0.00777672 0.00231205
0.00457842 0.00390424 0.00947046 0.00410091 0.0022092 0.00292498
0.00638005 0.00796804 0.00140869 0.00887531 0.00496863 0.01049942
0.00908096 0.00332738 0.00799218 0.00228496 0.004639 0.00213413
0.00729368 0.01049243 0.00790528 0.01269368 -0.00425872 0.00256319
0.00859569 0.00472848 0.0007721 0.00191874 0.01546813 0.00144742
0.00888212 0.00648021 0.00115819 0.00351191 0.00580168 0.00614044
0.00632418 0.0040833 0.00346038 -0.00034315 0.00599405 0.00302578
0.0065765 0.01086897 0.00625799 0.00096572 0.00061766 0.00038494
0.00523901 0.00633054 0.00379964 0.00302567 -0.00123339 0.00153471
0.00725584 0.00836433 0.01295913 0.00737863]
@hcho3 Do you want to look into it? I can help bisecting if needed.
trivialfis
on 12 Nov 2020
Hold a sec, I forgot to set the random seed in my repro. Silly me.
hcho3
on 12 Nov 2020
I updated my repro with the fixed random seed. The bug still persists. I tried running the updated repro with XGBoost 1.0.0 and 1.1.0, and the predictions agree with the prediction from XGBoost 1.2.0.
In short:
Prediction from 1.0.0
== Prediction from 1.1.0
== Prediction from 1.2.0
!= Prediction from latest master
@trivialfis Yes, your help will be appreciated.
hcho3
on 12 Nov 2020
Marking this as blocking.
hcho3
on 12 Nov 2020
Got it.
trivialfis
on 12 Nov 2020
Traced to a4ce0eae43f7e0e2f91566ef2360830b86b9fdcf . @ShvetsKS Would you like to take a look?
trivialfis
on 12 Nov 2020
Traced to a4ce0ea . @ShvetsKS Would you like to take a look?
Sure. Could you help with training the model from python reproducer :
m2.load_model('xgb.model.bin') # load data
What XGBoost version is used for training and which parameters should be provided exactly?
 ShvetsKS
on 12 Nov 2020
ShvetsKS
on 12 Nov 2020
@ShvetsKS You can obtain the model file xgb.model.bin from https://github.com/7starsea/xgboost-testing. The model was trained with 1.0.0.
hcho3
on 12 Nov 2020
@ShvetsKS You can obtain the model file
xgb.model.binfrom https://github.com/7starsea/xgboost-testing. The model was trained with 1.0.0.
the model was actually trained with 1.2.1 and parameters
param = {'max_depth': 8, 'eta': 0.1, 'min_child_weight': 2, 'gamma': 1e-8, 'subsample': 0.6, 'nthread': 4}
Thanks.
7starsea
on 12 Nov 2020
Seems the small difference is due to changed sequence of floating point operation.
_Exact reason:_
Before a4ce0ea we increment all trees responses into local variable psum (initially equal to zero) and than increment appropriate value from out_preds.
In a4ce0ea we increment out_preds values directly by each tree response.
Fix is prepared: https://github.com/dmlc/xgboost/pull/6384
@7starsea thanks for finding the difference, could you check the fix above?
@hcho3, @trivialfis Do we consider such difference as critical in future? Seems it's a significant restriction not allow change the sequence of floating point operations for inference. But for training stage there is no such requirement as I remember.
ShvetsKS
on 12 Nov 2020
Do we consider such difference as critical in future?
Usually no. Let me take a look into your changes. ;-)
trivialfis
on 12 Nov 2020
@ShvetsKS I just checked and the difference is exactly zero now. Thanks for fixing the predict difference.
7starsea
on 12 Nov 2020
@ShvetsKS
Do we consider such difference as critical in future? Seems it's a significant restriction not allow change the sequence of floating point operations for inference
Indeed, we (@RAMitchell, @trivialfis, and I) agree with you here. Mandating exact reproducibility of prediction will severely hamper our ability to make changes. Floating-point arithmetic is famously non-associative, so the sum of a list of number will be slightly different depending on the order of addition.
I have run an experiment to quantify how much the prediction changes between XGBoost 1.2.0 and the latest master branch:
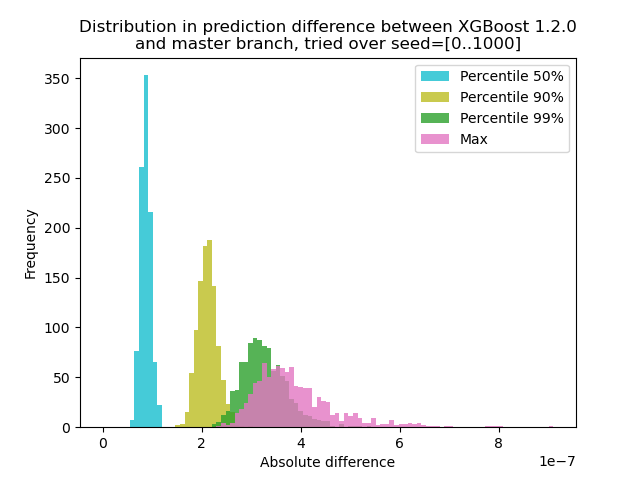
I generated data with 1000 different random seeds and then ran prediction with the 1000 matrices, using both versions 1.2.0 and master. The change in prediction changes between seeds slightly, but the difference is never more than 9.2e-7, so most likely the prediction change was caused by floating-point arithmetic and not a logic error.
Script for experiment
**test.py**: Generate 1000 matrices with different random seeds and run prediction for them.
import numpy as np
import xgboost as xgb
import argparse
def main(args):
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
out = {}
for seed in range(1000):
rng = np.random.default_rng(seed=seed)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
dtest = xgb.DMatrix(rx, missing=0.0)
out[str(seed)] = m2.predict(dtest)
np.savez(args.out_pred, **out)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--out-pred', type=str, required=True)
args = parser.parse_args()
main(args)
import numpy as np
import matplotlib.pyplot as plt
xgb120 = np.load('xgb120.npz')
xgblatest = np.load('xgblatest.npz')
percentile_pts = [50, 90, 99]
colors = ['tab:cyan', 'tab:olive', 'tab:green', 'tab:pink']
percentile = {}
for x in percentile_pts:
percentile[x] = []
percentile['max'] = []
for seed in range(1000):
diff = np.abs(xgb120[str(seed)] - xgblatest[str(seed)])
t = np.percentile(diff, percentile_pts)
for x, y in zip(percentile_pts, t):
percentile[x].append(y)
percentile['max'].append(np.max(diff))
bins = np.linspace(0, np.max(percentile['max']), 100)
idx = 0
for x in percentile_pts:
plt.hist(percentile[x], label=f'Percentile {x}%', bins=bins, alpha=0.8, color=colors[idx])
idx += 1
plt.hist(percentile['max'], label='Max', bins=bins, alpha=0.8, color=colors[idx])
plt.legend(loc='best')
plt.title('Distribution in prediction difference between XGBoost 1.2.0\nand master branch, tried over seed=[0..1000]')
plt.xlabel('Absolute difference')
plt.ylabel('Frequency')
plt.savefig('foobar.png', dpi=100)
Since here the problem is the + with float doesn't form a group, we can test with sum removed: Predict on a single tree. The result should be exactly the same.
trivialfis
on 13 Nov 2020
@trivialfis Indeed, when I added ntree_limit=1 argument to m2.predict(), the difference vanishes to 0.
hcho3
on 13 Nov 2020
Great! So next thing is how do we document it or whether should we document it.
trivialfis
on 13 Nov 2020
Let me sleep on it. For now, suffice to say that this issue is not really a bug.
hcho3
on 13 Nov 2020
Related issues
 uasthana15
·
4Comments
uasthana15
·
4Comments
 yananchen1989
·
3Comments
yananchen1989
·
3Comments
 Str1ker17
·
3Comments
Str1ker17
·
3Comments
 choushishi
·
3Comments
choushishi
·
3Comments
 pplonski
·
3Comments
pplonski
·
3Comments
Most helpful comment
@ShvetsKS
Indeed, we (@RAMitchell, @trivialfis, and I) agree with you here. Mandating exact reproducibility of prediction will severely hamper our ability to make changes. Floating-point arithmetic is famously non-associative, so the sum of a list of number will be slightly different depending on the order of addition.
I have run an experiment to quantify how much the prediction changes between XGBoost 1.2.0 and the latest

masterbranch:I generated data with 1000 different random seeds and then ran prediction with the 1000 matrices, using both versions 1.2.0 and master. The change in prediction changes between seeds slightly, but the difference is never more than 9.2e-7, so most likely the prediction change was caused by floating-point arithmetic and not a logic error.
Script for experiment
**test.py**: Generate 1000 matrices with different random seeds and run prediction for them.
Command: `python test.py --out-pred [out.npz]`. Make sure that your Python env has the correct version of XGBoost. Let us assume that `xgb120.npz` stores the result for XGBoost 1.2.0 and `xgblatest.npz` stores the result for the latest master. **compare.py**: Make a histogram plot for prediction difference