Xgboost: تنبؤات مختلفة في الإصدار 1.2.1 والفرع الرئيسي
أنا أستخدم الإصدار 1.2.1 للتطوير نظرًا لسهولة تثبيته في Python وأكتب أيضًا رمز c بسيطًا للتنبؤ باستخدام c_api. إذا كان مرتبطًا بـ v1.2.1 libxgboost.so ، فإن الفرق في التنبؤات بين Python و c هو صفر تمامًا. ومع ذلك ، إذا كان مرتبطًا بـ libxgboost.so من الفرع الرئيسي (الالتزام f3a425398 في 5 نوفمبر 2020) ، فهناك فرق.
أرغب في نشر كود c في نظام حقيقي باستخدام الفرع الرئيسي لأنني أرغب في إنشاء lib ثابت ، والآن يعوقني اختلاف التنبؤات بين الإصدار 1.2.1 والفرع الرئيسي.
شكرا.
 7starsea
7starsea
ال 35 كومينتر
هل يمكنك نشر برنامج كمثال حتى نتمكن من إعادة إنتاج الخطأ؟
 hcho3
في ٦ نوفمبر ٢٠٢٠
hcho3
في ٦ نوفمبر ٢٠٢٠
أيضًا ، هل ترى تنبؤات مختلفة من الإصدار الرئيسي لحزمة Python و C API؟
hcho3
في ٦ نوفمبر ٢٠٢٠
هناك بعض التحسينات التي تم إجراؤها على توقع وحدة المعالجة المركزية ، قد تؤدي إلى نتائج مختلفة بسبب خطأ نقطة عائمة مختلفة. لكن نعم ، هل لديك مثال قابل للتكرار؟
 trivialfis
في ٦ نوفمبر ٢٠٢٠
trivialfis
في ٦ نوفمبر ٢٠٢٠
أيضًا ، هل ترى تنبؤات مختلفة من الإصدار الرئيسي لحزمة Python و C API؟
أقوم بمقارنة الإصدار 1.2.1 من حزمة Python والفرع الرئيسي لـ C API.
7starsea
في ٦ نوفمبر ٢٠٢٠
@ 7starsea هل يمكنك أيضًا مقارنة مخرجات Python و C API ، وكلاهما من الفرع الرئيسي؟ قد تكون المشكلة طريقة استخدام وظائف C API في تطبيقك.
hcho3
في ٦ نوفمبر ٢٠٢٠
@ 7starsea هل يمكنك أيضًا مقارنة مخرجات Python و C API ، وكلاهما من الفرع الرئيسي؟ قد تكون المشكلة طريقة استخدام وظائف C API في تطبيقك.
لقد قارنت python و c api ، كلاهما من الإصدار 1.2.1 والتنبؤات متطابقة تمامًا.
7starsea
في ٦ نوفمبر ٢٠٢٠
@ 7starsea فهمت ذلك. إذا نشرت كلاً من برامج Python و C التي تتنبأ من نفس النموذج ، فسنكون قادرين على استكشاف المشكلة وإصلاحها بشكل أكبر.
hcho3
في ٦ نوفمبر ٢٠٢٠
@ hcho3 هنا هو رمز الاختبار
7starsea
في ٦ نوفمبر ٢٠٢٠
@ 7starsea لقد جربت للتو
difference: [0. 0. 0. 0.] 0.0 0.0
لقد استخدمت آخر التزام لـ XGBoost (debeae2509d90ec1d3402a3a185fba7a25113ff1).
hcho3
في ١٢ نوفمبر ٢٠٢٠
@ 7starsea لقد جربت للتو
difference: [0. 0. 0. 0.] 0.0 0.0لقد استخدمت آخر التزام لـ XGBoost ( debeae2 ).
مثير للاهتمام ، هل إصدار Python الخاص بك v1.2.1؟
لا يزال لدي بعض الاختلاف بين الإصدار 1.2.1 من python و c api المرتبط بـ XGBoost ( debeae2 ).
7starsea
في ١٢ نوفمبر ٢٠٢٠
@ 7starsea لا ، لقد جمعت XGBoost من أحدث مصدر (الالتزام debeae2509d90ec1d3402a3a185fba7a25113ff1) ، لذا فهو أحدث من الإصدار 1.2.1. تطبع حزمة XGBoost Python الخاصة بي 1.3.0-SNAPSHOT مقابل حقل xgboost.__version__ .
hcho3
في ١٢ نوفمبر ٢٠٢٠
@ hcho3 أتساءل هل يجب أن يحافظ XGBoost على تنبؤ متسق بين الإصدارات المختلفة (على الأقل الإصدارات المتتالية)؟
نتوقع أيضًا إصدار v1.3.0.
(يبدو أنني بحاجة إلى تدريب النموذج باستخدام الفرع الرئيسي الآن)
شكرا على وقتك.
7starsea
في ١٢ نوفمبر ٢٠٢٠
@ 7starsea إذا قمت بتحميل نموذج محفوظ من إصدار سابق ، فيجب أن تكون قادرًا على الحصول على التنبؤ المتسق.
لم أتمكن من إعادة إظهار المشكلة باستخدام البرنامج النصي الخاص بك. هل يمكنك محاولة إنشاء صورة Docker أو صورة VM ومشاركتها معي؟
hcho3
في ١٢ نوفمبر ٢٠٢٠
@ 7starsea FYI ، حاولت أيضًا إنشاء XGBoost 1.2.1 من المصدر ، على النحو التالي:
git clone --recursive https://github.com/dmlc/xgboost -b release_1.2.0 xgb_source
cd xgb_source
mkdir build
cd build
cmake ..
make
cd ../python-package
python setup.py install
تظهر النتائج مرة أخرى difference: [0. 0. 0. 0.] 0.0 0.0
hcho3
في ١٢ نوفمبر ٢٠٢٠
لمعرفة الفرق ، أنت بحاجة إلى إصدارين من XGBoost ، v1.2.1 من أجل python و
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest) # # internally using libxgboost.so v1.2.1
وواحد لـ CPP
m1 = XgbShannonPredictor(fname)
y2 = m1.predict(rx2) # # internally using libxgboost.so from the master branch (debeae2)
سأحاول بناء صورة عامل ميناء (وهو جديد بالنسبة لي).
7starsea
في ١٢ نوفمبر ٢٠٢٠
اسمحوا لي أن ألقي نظرة.
trivialfis
في ١٢ نوفمبر ٢٠٢٠
سأحاول بناء صورة عامل ميناء (وهو جديد بالنسبة لي).
ليس من الضروري.
trivialfis
في ١٢ نوفمبر ٢٠٢٠
في الواقع ، تمكنت من إعادة إنتاج المشكلة. اتضح أن إصدار المطور من XGBoost ينتج تنبؤًا مختلفًا عن XGBoost 1.2.0. والمشكلة سهلة التكاثر. لا حاجة لاستخدام C API.
مثال قابل للتكرار (تحرير: إعداد البذور العشوائية):
import numpy as np
import xgboost as xgb
rng = np.random.default_rng(seed=2020)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest)
print(xgb.__version__)
print(y1)
الناتج من 1.2.0:
1.2.0
[ 0.00698659 -0.00211251 0.00180039 -0.00016004 0.00526169 0.00801963
0.00016755 0.00226218 0.00276762 0.00408182 0.00303206 0.00291929
0.01101092 0.0068329 0.00145864 0.00326979 0.00572816 0.01019934
0.00074345 0.00784767 0.00173795 -0.00219297 0.0060181 0.00606489
0.00447372 0.00103396 0.00932363 0.00230178 0.00389203 0.00151157
0.0034163 0.00821933 0.006686 0.00630778 0.00331488 0.00775066
0.00443819 0.01030204 0.00924486 0.00645933 0.00777653 0.00231206
0.00457835 0.00390425 0.00947028 0.00410065 0.00220913 0.00292507
0.00637993 0.00796807 0.00140873 0.00887537 0.00496858 0.01049942
0.00908098 0.00332722 0.00799242 0.00228494 0.00463879 0.00213429
0.00729388 0.01049232 0.00790522 0.01269361 -0.00425893 0.00256333
0.00859573 0.00472835 0.00077197 0.00191873 0.01546788 0.0014475
0.00888193 0.00648022 0.00115797 0.00351191 0.00580138 0.00614035
0.00632426 0.00408354 0.00346044 -0.00034332 0.00599384 0.00302595
0.00657633 0.01086903 0.00625807 0.00096565 0.00061804 0.00038511
0.00523874 0.00633043 0.00379965 0.00302553 -0.00123322 0.00153473
0.00725579 0.00836438 0.01295918 0.00737873]
ملحوظة. تشغيل البرنامج النصي باستخدام XGBoost 1.0.0 و 1.1.0 ينتج عنه إخراج مماثل مثل 1.2.0.
الإخراج من إصدار مطور البرامج (c5645180a6afb9d3d771165e681985fe3522adf6)
1.3.0-SNAPSHOT
[ 0.00698666 -0.00211278 0.00180034 -0.00016027 0.00526194 0.00801962
0.00016758 0.00226211 0.00276773 0.00408198 0.00303223 0.00291933
0.01101091 0.00683288 0.00145871 0.00326988 0.00572827 0.01019943
0.00074329 0.00784767 0.00173803 -0.00219286 0.00601804 0.00606472
0.00447388 0.00103391 0.00932358 0.00230171 0.003892 0.00151177
0.00341637 0.00821943 0.00668607 0.00630774 0.00331502 0.00775074
0.0044381 0.01030211 0.00924495 0.00645958 0.00777672 0.00231205
0.00457842 0.00390424 0.00947046 0.00410091 0.0022092 0.00292498
0.00638005 0.00796804 0.00140869 0.00887531 0.00496863 0.01049942
0.00908096 0.00332738 0.00799218 0.00228496 0.004639 0.00213413
0.00729368 0.01049243 0.00790528 0.01269368 -0.00425872 0.00256319
0.00859569 0.00472848 0.0007721 0.00191874 0.01546813 0.00144742
0.00888212 0.00648021 0.00115819 0.00351191 0.00580168 0.00614044
0.00632418 0.0040833 0.00346038 -0.00034315 0.00599405 0.00302578
0.0065765 0.01086897 0.00625799 0.00096572 0.00061766 0.00038494
0.00523901 0.00633054 0.00379964 0.00302567 -0.00123339 0.00153471
0.00725584 0.00836433 0.01295913 0.00737863]
@ hcho3 هل تريد النظر فيه؟ يمكنني المساعدة في التنصيف إذا لزم الأمر.
trivialfis
في ١٢ نوفمبر ٢٠٢٠
انتظر لحظة ، لقد نسيت تعيين البذور العشوائية في نسبي. ما أغباني.
hcho3
في ١٢ نوفمبر ٢٠٢٠
لقد قمت بتحديث نسبي مع البذور العشوائية الثابتة. لا يزال الخطأ قائما. حاولت تشغيل repro المحدث باستخدام XGBoost 1.0.0 و 1.1.0 ، وتتفق التوقعات مع التنبؤ من XGBoost 1.2.0.
باختصار:
Prediction from 1.0.0
== Prediction from 1.1.0
== Prediction from 1.2.0
!= Prediction from latest master
@ trivialfis نعم ، سوف نقدر مساعدتك.
hcho3
في ١٢ نوفمبر ٢٠٢٠
وضع علامة على هذا على أنه حظر.
hcho3
في ١٢ نوفمبر ٢٠٢٠
فهمتك.
trivialfis
في ١٢ نوفمبر ٢٠٢٠
تتبع إلى a4ce0eae43f7e0e2f91566ef2360830b86b9fdcf. ShvetsKS هل ترغب في إلقاء نظرة؟
trivialfis
في ١٢ نوفمبر ٢٠٢٠
تتبع ل a4ce0ea . ShvetsKS هل ترغب في إلقاء نظرة؟
بالتأكيد. هل يمكنك المساعدة في تدريب النموذج من ناسخ الثعبان:
m2.load_model('xgb.model.bin') # load data
ما هو إصدار XGBoost المستخدم للتدريب وما هي المعلمات التي يجب توفيرها بالضبط؟
 ShvetsKS
في ١٢ نوفمبر ٢٠٢٠
ShvetsKS
في ١٢ نوفمبر ٢٠٢٠
ShvetsKS يمكنك الحصول على ملف النموذج xgb.model.bin من https://github.com/7starsea/xgboost-testing. تم تدريب النموذج بـ 1.0.0.
hcho3
في ١٢ نوفمبر ٢٠٢٠
ShvetsKS يمكنك الحصول على ملف النموذج
xgb.model.binمن https://github.com/7starsea/xgboost-testing. تم تدريب النموذج بـ 1.0.0.
تم تدريب النموذج بالفعل باستخدام 1.2.1 والمعلمات
param = {'max_depth': 8, 'eta': 0.1, 'min_child_weight': 2, 'gamma': 1e-8, 'subsample': 0.6, 'nthread': 4}
شكرا.
7starsea
في ١٢ نوفمبر ٢٠٢٠
يبدو أن الاختلاف الصغير يرجع إلى تغيير تسلسل عملية النقطة العائمة.
_السبب الدقيق: _
قبل a4ce0ea ، نزيد جميع استجابات الأشجار إلى المتغير المحلي psum (في البداية يساوي الصفر) ثم نزيد القيمة المناسبة من out_preds .
في a4ce0ea ، نزيد قيم out_preds مباشرةً عن طريق كل استجابة شجرة.
تم تجهيز الإصلاح: https://github.com/dmlc/xgboost/pull/6384
@ 7starsea شكرًا لإيجاد الفرق ، هل يمكنك التحقق من الإصلاح أعلاه؟
@ hcho3،trivialfis هل نعتبر هذا الفرق في غاية الأهمية في المستقبل؟ يبدو أنه قيد كبير لا يسمح بتغيير تسلسل عمليات الفاصلة العائمة للاستدلال. لكن بالنسبة لمرحلة التدريب ، لا يوجد شرط من هذا القبيل كما أتذكر.
ShvetsKS
في ١٢ نوفمبر ٢٠٢٠
هل نعتبر هذا الاختلاف أمرًا بالغ الأهمية في المستقبل؟
عادة لا. اسمحوا لي أن ألقي نظرة على التغييرات الخاصة بك. ؛-)
trivialfis
في ١٢ نوفمبر ٢٠٢٠
ShvetsKS لقد راجعت للتو والفرق هو صفر تمامًا الآن. شكرا لضبط توقع الاختلاف.
7starsea
في ١٢ نوفمبر ٢٠٢٠
تضمين التغريدة
هل نعتبر هذا الاختلاف أمرًا بالغ الأهمية في المستقبل؟ يبدو أنه قيد كبير لا يسمح بتغيير تسلسل عمليات الفاصلة العائمة للاستدلال
في الواقع ، نحن ( RAMitchell و @ trivialfis وأنا) نتفق معك هنا. إن فرض إمكانية استنساخ التنبؤ بدقة سيعيق بشدة قدرتنا على إجراء تغييرات. تشتهر عملية حساب الفاصلة العائمة بأنها غير ارتباطية ، لذا فإن مجموع قائمة الأرقام سيكون مختلفًا قليلاً اعتمادًا على ترتيب الجمع.
لقد أجريت تجربة لتحديد مدى تغير التنبؤ بين XGBoost 1.2.0 وآخر فرع master :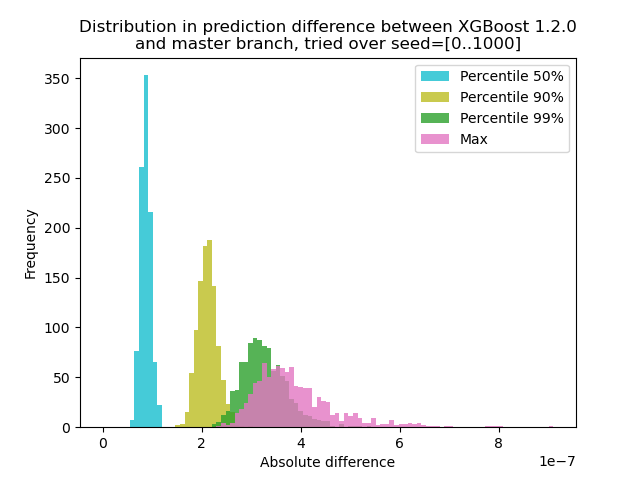
لقد قمت بإنشاء بيانات باستخدام 1000 بذرة عشوائية مختلفة ثم قمت بإجراء التنبؤ باستخدام 1000 مصفوفة ، باستخدام الإصدارين 1.2.0 والإصدار الرئيسي. يتغير التغيير في التنبؤ بين البذور بشكل طفيف ، لكن الفرق لا يزيد أبدًا عن 9.2e-7 ، لذلك على الأرجح أن التغيير في التنبؤ كان بسبب حساب النقطة العائمة وليس خطأ منطقي .
سيناريو للتجربة
** test.py **: قم بتوليد 1000 مصفوفة ببذور عشوائية مختلفة وتشغيل التنبؤ لها.
import numpy as np
import xgboost as xgb
import argparse
def main(args):
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
out = {}
for seed in range(1000):
rng = np.random.default_rng(seed=seed)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
dtest = xgb.DMatrix(rx, missing=0.0)
out[str(seed)] = m2.predict(dtest)
np.savez(args.out_pred, **out)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--out-pred', type=str, required=True)
args = parser.parse_args()
main(args)
import numpy as np
import matplotlib.pyplot as plt
xgb120 = np.load('xgb120.npz')
xgblatest = np.load('xgblatest.npz')
percentile_pts = [50, 90, 99]
colors = ['tab:cyan', 'tab:olive', 'tab:green', 'tab:pink']
percentile = {}
for x in percentile_pts:
percentile[x] = []
percentile['max'] = []
for seed in range(1000):
diff = np.abs(xgb120[str(seed)] - xgblatest[str(seed)])
t = np.percentile(diff, percentile_pts)
for x, y in zip(percentile_pts, t):
percentile[x].append(y)
percentile['max'].append(np.max(diff))
bins = np.linspace(0, np.max(percentile['max']), 100)
idx = 0
for x in percentile_pts:
plt.hist(percentile[x], label=f'Percentile {x}%', bins=bins, alpha=0.8, color=colors[idx])
idx += 1
plt.hist(percentile['max'], label='Max', bins=bins, alpha=0.8, color=colors[idx])
plt.legend(loc='best')
plt.title('Distribution in prediction difference between XGBoost 1.2.0\nand master branch, tried over seed=[0..1000]')
plt.xlabel('Absolute difference')
plt.ylabel('Frequency')
plt.savefig('foobar.png', dpi=100)
نظرًا لأن المشكلة هنا هي أن + مع تعويم لا يشكل مجموعة ، يمكننا اختبار مع إزالة المجموع: توقع على شجرة واحدة. يجب أن تكون النتيجة متطابقة تمامًا.
trivialfis
في ١٣ نوفمبر ٢٠٢٠
trivialfis في الواقع ، عندما أضفت وسيطة ntree_limit=1 إلى m2.predict() ، يتلاشى الفرق إلى 0.
hcho3
في ١٣ نوفمبر ٢٠٢٠
باهر! الشيء التالي هو كيف نوثقها أو ما إذا كان ينبغي علينا توثيقها.
trivialfis
في ١٣ نوفمبر ٢٠٢٠
اسمحوا لي أن أنام على ذلك. في الوقت الحالي ، يكفي أن نقول إن هذه المشكلة ليست مشكلة في الحقيقة.
hcho3
في ١٣ نوفمبر ٢٠٢٠
القضايا ذات الصلة
 yananchen1989
·
3تعليقات
yananchen1989
·
3تعليقات
 mhnamaki
·
3تعليقات
mhnamaki
·
3تعليقات
 XiaoxiaoWang87
·
3تعليقات
XiaoxiaoWang87
·
3تعليقات
 tqchen
·
4تعليقات
tqchen
·
4تعليقات
 hx364
·
3تعليقات
hx364
·
3تعليقات
التعليق الأكثر فائدة
تضمين التغريدة
في الواقع ، نحن ( RAMitchell و @ trivialfis وأنا) نتفق معك هنا. إن فرض إمكانية استنساخ التنبؤ بدقة سيعيق بشدة قدرتنا على إجراء تغييرات. تشتهر عملية حساب الفاصلة العائمة بأنها غير ارتباطية ، لذا فإن مجموع قائمة الأرقام سيكون مختلفًا قليلاً اعتمادًا على ترتيب الجمع.
لقد أجريت تجربة لتحديد مدى تغير التنبؤ بين XGBoost 1.2.0 وآخر فرع

master:لقد قمت بإنشاء بيانات باستخدام 1000 بذرة عشوائية مختلفة ثم قمت بإجراء التنبؤ باستخدام 1000 مصفوفة ، باستخدام الإصدارين 1.2.0 والإصدار الرئيسي. يتغير التغيير في التنبؤ بين البذور بشكل طفيف ، لكن الفرق لا يزيد أبدًا عن 9.2e-7 ، لذلك على الأرجح أن التغيير في التنبؤ كان بسبب حساب النقطة العائمة وليس خطأ منطقي .
سيناريو للتجربة
** test.py **: قم بتوليد 1000 مصفوفة ببذور عشوائية مختلفة وتشغيل التنبؤ لها.
الأمر: `python test.py --out-pred [out.npz]`. تأكد من أن لغة Python الخاصة بك بها الإصدار الصحيح من XGBoost. لنفترض أن "xgb120.npz" يخزن نتيجة XGBoost 1.2.0 وأن "xgblatest.npz" يخزن النتيجة لأحدث نسخة رئيسية. ** Compare.py **: قم بعمل رسم بياني لاختلاف التنبؤ