Xgboost: предсказание отличается в v1.2.1 и основной ветке
Я использую выпущенную версию 1.2.1 для разработки из-за ее простой установки на python, а также пишу простой код c для прогнозирования с использованием c_api. Если он связан с libxgboost.so v1.2.1, разница прогнозов между python и c равна нулю. Однако, если он связан с libxgboost.so из главной ветки (фиксация f3a425398 5 ноября 2020 г.), разница будет.
Я хотел бы развернуть код c в реальной системе, используя главную ветвь, так как я хотел бы создать статическую библиотеку, и теперь мне мешает разница в прогнозах между v1.2.1 и основной веткой.
Спасибо.
 7starsea
7starsea
Все 35 Комментарий
Можете ли вы опубликовать пример программы, чтобы мы могли воспроизвести ошибку?
 hcho3
6 нояб. 2020
hcho3
6 нояб. 2020
Кроме того, вы видите разные прогнозы от основной версии пакета Python и C API?
hcho3
6 нояб. 2020
Есть некоторая оптимизация, сделанная на предсказателе ЦП, может дать другой результат из-за другой ошибки с плавающей запятой. Но да, у вас есть воспроизводимый пример?
 trivialfis
6 нояб. 2020
trivialfis
6 нояб. 2020
Кроме того, вы видите разные прогнозы от основной версии пакета Python и C API?
Я сравниваю версию 1.2.1 пакета python и основную ветку C API.
7starsea
6 нояб. 2020
@ 7starsea Можете ли вы также сравнить результаты работы Python и C API, как из основной ветки? Проблема может заключаться в том, как функции C API используются в вашем приложении.
hcho3
6 нояб. 2020
@ 7starsea Можете ли вы также сравнить результаты работы Python и C API, как из основной ветки? Проблема может заключаться в том, как функции C API используются в вашем приложении.
Я сравнил python и c api, оба из v1.2.1, и прогнозы точно такие же.
7starsea
6 нояб. 2020
@ 7starsea Понятно . Если вы опубликуете программы Python и C, которые прогнозируют на основе одной и той же модели, мы сможем устранить проблему дальше.
hcho3
6 нояб. 2020
@ hcho3 вот тестовый код
7starsea
6 нояб. 2020
@ 7starsea Я только что попробовал ваш пример и получил следующий результат:
difference: [0. 0. 0. 0.] 0.0 0.0
Я использовал последний коммит XGBoost (debeae2509d90ec1d3402a3a185fba7a25113ff1).
hcho3
12 нояб. 2020
@ 7starsea Я только что попробовал ваш пример и получил следующий результат:
difference: [0. 0. 0. 0.] 0.0 0.0Я использовал последний коммит XGBoost ( debeae2 ).
Интересно, а у вас версия python v1.2.1?
У меня все еще есть разница между python-версией 1.2.1 и c api, связанными с XGBoost ( debeae2 ).
7starsea
12 нояб. 2020
@ 7starsea Нет, я скомпилировал XGBoost из последнего источника (commit debeae2509d90ec1d3402a3a185fba7a25113ff1), поэтому он более свежий, чем v1.2.1. Мой пакет XGBoost Python печатает 1.3.0-SNAPSHOT для поля xgboost.__version__ .
hcho3
12 нояб. 2020
@ hcho3 Мне интересно, должен ли XGBoost сохранять согласованное предсказание между разными версиями (по крайней мере, последовательными версиями)?
Также ожидаем релиза v1.3.0.
(кажется, мне сейчас нужно обучить модель, используя главную ветку)
Спасибо за ваше время.
7starsea
12 нояб. 2020
@ 7starsea Если вы загрузите сохраненную модель из предыдущей версии, вы сможете получить согласованный прогноз.
Мне не удалось воспроизвести проблему с помощью вашего скрипта. Можете ли вы попробовать создать образ Docker или образ виртуальной машины и поделиться им со мной?
hcho3
12 нояб. 2020
@ 7starsea FYI, я также пробовал собрать XGBoost 1.2.1 из исходного кода следующим образом:
git clone --recursive https://github.com/dmlc/xgboost -b release_1.2.0 xgb_source
cd xgb_source
mkdir build
cd build
cmake ..
make
cd ../python-package
python setup.py install
В результатах снова отображается difference: [0. 0. 0. 0.] 0.0 0.0
hcho3
12 нояб. 2020
Чтобы увидеть разницу, вам понадобятся две версии XGBoost: v1.2.1 для python и
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest) # # internally using libxgboost.so v1.2.1
и один для cpp
m1 = XgbShannonPredictor(fname)
y2 = m1.predict(rx2) # # internally using libxgboost.so from the master branch (debeae2)
Я попытаюсь создать образ докера (что для меня в новинку).
7starsea
12 нояб. 2020
Дай взглянуть.
trivialfis
12 нояб. 2020
Я попытаюсь создать образ докера (что для меня в новинку).
Не обязательно.
trivialfis
12 нояб. 2020
Собственно, мне удалось воспроизвести проблему. Оказывается, версия XGBoost для разработчиков дает другое предсказание, чем XGBoost 1.2.0. И эту проблему просто воспроизвести; нет необходимости использовать C API.
Воспроизводимый пример (EDIT: установка случайного числа):
import numpy as np
import xgboost as xgb
rng = np.random.default_rng(seed=2020)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
dtest = xgb.DMatrix(rx, missing=0.0)
y1 = m2.predict(dtest)
print(xgb.__version__)
print(y1)
Выход из 1.2.0:
1.2.0
[ 0.00698659 -0.00211251 0.00180039 -0.00016004 0.00526169 0.00801963
0.00016755 0.00226218 0.00276762 0.00408182 0.00303206 0.00291929
0.01101092 0.0068329 0.00145864 0.00326979 0.00572816 0.01019934
0.00074345 0.00784767 0.00173795 -0.00219297 0.0060181 0.00606489
0.00447372 0.00103396 0.00932363 0.00230178 0.00389203 0.00151157
0.0034163 0.00821933 0.006686 0.00630778 0.00331488 0.00775066
0.00443819 0.01030204 0.00924486 0.00645933 0.00777653 0.00231206
0.00457835 0.00390425 0.00947028 0.00410065 0.00220913 0.00292507
0.00637993 0.00796807 0.00140873 0.00887537 0.00496858 0.01049942
0.00908098 0.00332722 0.00799242 0.00228494 0.00463879 0.00213429
0.00729388 0.01049232 0.00790522 0.01269361 -0.00425893 0.00256333
0.00859573 0.00472835 0.00077197 0.00191873 0.01546788 0.0014475
0.00888193 0.00648022 0.00115797 0.00351191 0.00580138 0.00614035
0.00632426 0.00408354 0.00346044 -0.00034332 0.00599384 0.00302595
0.00657633 0.01086903 0.00625807 0.00096565 0.00061804 0.00038511
0.00523874 0.00633043 0.00379965 0.00302553 -0.00123322 0.00153473
0.00725579 0.00836438 0.01295918 0.00737873]
Примечание. запуск сценария с XGBoost 1.0.0 и 1.1.0 приводит к тому же результату, что и 1.2.0.
Вывод из версии для разработчиков (c5645180a6afb9d3d771165e681985fe3522adf6)
1.3.0-SNAPSHOT
[ 0.00698666 -0.00211278 0.00180034 -0.00016027 0.00526194 0.00801962
0.00016758 0.00226211 0.00276773 0.00408198 0.00303223 0.00291933
0.01101091 0.00683288 0.00145871 0.00326988 0.00572827 0.01019943
0.00074329 0.00784767 0.00173803 -0.00219286 0.00601804 0.00606472
0.00447388 0.00103391 0.00932358 0.00230171 0.003892 0.00151177
0.00341637 0.00821943 0.00668607 0.00630774 0.00331502 0.00775074
0.0044381 0.01030211 0.00924495 0.00645958 0.00777672 0.00231205
0.00457842 0.00390424 0.00947046 0.00410091 0.0022092 0.00292498
0.00638005 0.00796804 0.00140869 0.00887531 0.00496863 0.01049942
0.00908096 0.00332738 0.00799218 0.00228496 0.004639 0.00213413
0.00729368 0.01049243 0.00790528 0.01269368 -0.00425872 0.00256319
0.00859569 0.00472848 0.0007721 0.00191874 0.01546813 0.00144742
0.00888212 0.00648021 0.00115819 0.00351191 0.00580168 0.00614044
0.00632418 0.0040833 0.00346038 -0.00034315 0.00599405 0.00302578
0.0065765 0.01086897 0.00625799 0.00096572 0.00061766 0.00038494
0.00523901 0.00633054 0.00379964 0.00302567 -0.00123339 0.00153471
0.00725584 0.00836433 0.01295913 0.00737863]
@ hcho3 Хотите разобраться? Если нужно, могу помочь разделить пополам.
trivialfis
12 нояб. 2020
Подождите секунду, я забыл установить случайное семя в моем репро. Я такой глупый.
hcho3
12 нояб. 2020
Я обновил свою репродукцию с фиксированным случайным семенем. Ошибка все еще сохраняется. Я попытался запустить обновленное воспроизведение с XGBoost 1.0.0 и 1.1.0, и прогнозы совпадают с прогнозом XGBoost 1.2.0.
Короче:
Prediction from 1.0.0
== Prediction from 1.1.0
== Prediction from 1.2.0
!= Prediction from latest master
@trivialfis Да, мы будем благодарны за вашу помощь.
hcho3
12 нояб. 2020
Пометить это как блокирующее.
hcho3
12 нояб. 2020
Понятно.
trivialfis
12 нояб. 2020
Прослежено до a4ce0eae43f7e0e2f91566ef2360830b86b9fdcf. @ShvetsKS Хотите взглянуть?
trivialfis
12 нояб. 2020
Прослежено до a4ce0ea . @ShvetsKS Хотите взглянуть?
Конечно. Не могли бы вы помочь с обучением модели из репродуктора python:
m2.load_model('xgb.model.bin') # load data
Какая версия XGBoost используется для обучения и какие именно параметры нужно указывать?
 ShvetsKS
12 нояб. 2020
ShvetsKS
12 нояб. 2020
@ShvetsKS Вы можете получить файл модели xgb.model.bin по адресу https://github.com/7starsea/xgboost-testing. Модель обучалась с 1.0.0.
hcho3
12 нояб. 2020
@ShvetsKS Вы можете получить файл модели
xgb.model.binпо адресу https://github.com/7starsea/xgboost-testing. Модель обучалась с 1.0.0.
модель была фактически обучена с 1.2.1 и параметрами
param = {'max_depth': 8, 'eta': 0.1, 'min_child_weight': 2, 'gamma': 1e-8, 'subsample': 0.6, 'nthread': 4}
Спасибо.
7starsea
12 нояб. 2020
Кажется, небольшая разница связана с изменением последовательности операций с плавающей запятой.
_Точная причина: _
Перед a4ce0ea мы увеличиваем все ответы деревьев в локальную переменную psum (изначально равную нулю), а затем увеличиваем соответствующее значение с out_preds .
В a4ce0ea мы увеличиваем значения out_preds непосредственно на каждый ответ дерева.
Исправление подготовлено: https://github.com/dmlc/xgboost/pull/6384
@ 7starsea, спасибо, что нашли разницу, не могли бы вы проверить исправление выше?
@ hcho3 , @trivialfis Считаем ли мы такую разницу критической в будущем? Кажется, это существенное ограничение, не позволяющее изменять последовательность операций с плавающей запятой для вывода. А вот для тренировочного этапа, насколько я помню, такого требования нет.
ShvetsKS
12 нояб. 2020
Считаем ли мы такую разницу критической в будущем?
Обычно нет. Позвольте мне взглянуть на ваши изменения. ;-)
trivialfis
12 нояб. 2020
@ShvetsKS Я только что проверил, разница сейчас ровно нулевая. Спасибо, что исправили разницу в прогнозе.
7starsea
12 нояб. 2020
@ShvetsKS
Считаем ли мы такую разницу критической в будущем? Кажется, это существенное ограничение, не позволяющее изменять последовательность операций с плавающей запятой для вывода.
Действительно, мы ( @RAMitchell , @trivialfis и я) согласны с вами здесь. Требование точной воспроизводимости прогнозов серьезно ограничит нашу способность вносить изменения. Арифметика с плавающей запятой, как известно, неассоциативна, поэтому сумма списка чисел будет немного отличаться в зависимости от порядка добавления.
Я провел эксперимент, чтобы количественно оценить, насколько меняется прогноз между XGBoost 1.2.0 и последней веткой master :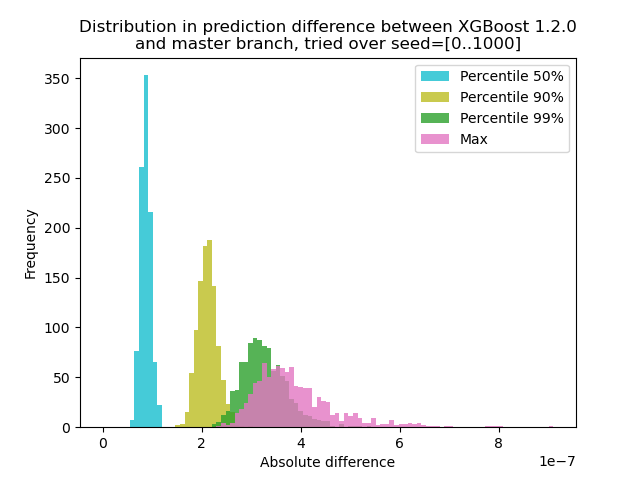
Я сгенерировал данные с 1000 различными случайными начальными числами, а затем выполнил прогноз с использованием 1000 матриц, используя обе версии 1.2.0 и master. Изменение прогноза между начальными числами изменяется незначительно, но
Скрипт для эксперимента
** test.py **: сгенерируйте 1000 матриц с разными случайными начальными числами и выполните прогноз для них.
import numpy as np
import xgboost as xgb
import argparse
def main(args):
m2 = xgb.Booster({'nthread': '4'}) # init model
m2.load_model('xgb.model.bin') # load data
out = {}
for seed in range(1000):
rng = np.random.default_rng(seed=seed)
rx = rng.standard_normal(size=(100, 127 + 7 + 1))
rx = rx.astype(np.float32, order='C')
dtest = xgb.DMatrix(rx, missing=0.0)
out[str(seed)] = m2.predict(dtest)
np.savez(args.out_pred, **out)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--out-pred', type=str, required=True)
args = parser.parse_args()
main(args)
import numpy as np
import matplotlib.pyplot as plt
xgb120 = np.load('xgb120.npz')
xgblatest = np.load('xgblatest.npz')
percentile_pts = [50, 90, 99]
colors = ['tab:cyan', 'tab:olive', 'tab:green', 'tab:pink']
percentile = {}
for x in percentile_pts:
percentile[x] = []
percentile['max'] = []
for seed in range(1000):
diff = np.abs(xgb120[str(seed)] - xgblatest[str(seed)])
t = np.percentile(diff, percentile_pts)
for x, y in zip(percentile_pts, t):
percentile[x].append(y)
percentile['max'].append(np.max(diff))
bins = np.linspace(0, np.max(percentile['max']), 100)
idx = 0
for x in percentile_pts:
plt.hist(percentile[x], label=f'Percentile {x}%', bins=bins, alpha=0.8, color=colors[idx])
idx += 1
plt.hist(percentile['max'], label='Max', bins=bins, alpha=0.8, color=colors[idx])
plt.legend(loc='best')
plt.title('Distribution in prediction difference between XGBoost 1.2.0\nand master branch, tried over seed=[0..1000]')
plt.xlabel('Absolute difference')
plt.ylabel('Frequency')
plt.savefig('foobar.png', dpi=100)
Поскольку здесь проблема в том, что + с float не образует группу, мы можем протестировать с удаленной суммой: Прогнозирование на одном дереве. Результат должен быть точно таким же.
trivialfis
13 нояб. 2020
@trivialfis Действительно, когда я добавил ntree_limit=1 аргумент к m2.predict() , разница исчезла до 0.
hcho3
13 нояб. 2020
Здорово! Итак, следующий вопрос - как мы это документируем или должны ли мы это задокументировать.
trivialfis
13 нояб. 2020
Дай мне поспать на нем. А пока достаточно сказать, что эта проблема на самом деле не является ошибкой.
hcho3
13 нояб. 2020
Смежные вопросы
 hx364
·
3Комментарии
hx364
·
3Комментарии
 matthewmav
·
3Комментарии
matthewmav
·
3Комментарии
 tqchen
·
4Комментарии
tqchen
·
4Комментарии
 pplonski
·
3Комментарии
pplonski
·
3Комментарии
 wenbo5565
·
3Комментарии
wenbo5565
·
3Комментарии
Самый полезный комментарий
@ShvetsKS
Действительно, мы ( @RAMitchell , @trivialfis и я) согласны с вами здесь. Требование точной воспроизводимости прогнозов серьезно ограничит нашу способность вносить изменения. Арифметика с плавающей запятой, как известно, неассоциативна, поэтому сумма списка чисел будет немного отличаться в зависимости от порядка добавления.
Я провел эксперимент, чтобы количественно оценить, насколько меняется прогноз между XGBoost 1.2.0 и последней веткой

master:Я сгенерировал данные с 1000 различными случайными начальными числами, а затем выполнил прогноз с использованием 1000 матриц, используя обе версии 1.2.0 и master. Изменение прогноза между начальными числами изменяется незначительно, но
Скрипт для эксперимента
** test.py **: сгенерируйте 1000 матриц с разными случайными начальными числами и выполните прогноз для них.
Команда: `python test.py --out-pred [out.npz]`. Убедитесь, что ваш Python env имеет правильную версию XGBoost. Предположим, что xgb120.npz хранит результат для XGBoost 1.2.0, а xgblatest.npz хранит результат для последнего мастера. ** compare.py **: построение гистограммы для разницы в прогнозе.