Pytorch: RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 12,50 MiB zuzuweisen (GPU 0; 10,92 GiB Gesamtkapazität; 8,57 MiB bereits zugewiesen; 9,28 GiB frei; 4,68 MiB zwischengespeichert)
CUDA Out of Memory-Fehler, aber CUDA-Speicher ist fast leer
Ich trainiere derzeit ein leichtgewichtiges Modell mit sehr großen Textdatenmengen (ca. 70 GiB Text).
Dafür verwende ich eine Maschine in einem Cluster ( 'grele' des grid5000-Cluster-Netzwerks ).
Ich erhalte nach 3 Stunden Training diese sehr seltsame CUDA-Fehlermeldung "Out of Memory":
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
Laut Meldung habe ich den benötigten Speicherplatz, aber der Speicher wird nicht zugewiesen.
Irgendeine Idee, was das verursachen könnte?
Zur Information, meine Vorverarbeitung basiert auf torch.multiprocessing.Queue und einem Iterator über die Zeilen meiner Quelldaten, um die Daten im laufenden Betrieb vorzuverarbeiten.
Vollständiger Stacktrace
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
Alle 91 Kommentare
Ich habe den gleichen Laufzeitfehler:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
am 27. Jan. 2019
OmarBazaraa
am 27. Jan. 2019
@EMarquer @OmarBazaraa Könnten Sie ein minimales Repro-Beispiel geben, das wir ausführen können?
 yf225
am 28. Jan. 2019
yf225
am 28. Jan. 2019
Ich kann das Problem nicht mehr reproduzieren, daher schließe ich das Problem.
Das Problem verschwand, als ich aufhörte, die vorverarbeiteten Daten im RAM zu speichern.
@OmarBazaraa , ich glaube nicht, dass dein Problem das gleiche ist wie
- Ich versuche, 12,50 MiB zuzuweisen, mit 9,28 GiB frei
- Sie versuchen, 195,25 MiB zuzuweisen, wobei 170,14 MiB frei sind
Nach meiner bisherigen Erfahrung mit diesem Problem geben Sie entweder den CUDA-Speicher nicht frei oder Sie versuchen, zu viele Daten auf CUDA zu speichern.
Indem Sie den CUDA-Speicher nicht freigeben, meine ich, dass Sie möglicherweise immer noch Verweise auf Tensoren in CUDA haben, die Sie nicht mehr verwenden. Diese würden verhindern, dass der zugewiesene Speicher durch das Löschen der Tensoren freigegeben wird.
EMarquer
am 28. Jan. 2019
Gibt es eine allgemeine Lösung?
CUDA hat keinen Speicher mehr. Versuch, 196,00 MiB zuzuweisen (GPU 0; 2,00 GiB Gesamtkapazität; 359,38 MiB bereits zugewiesen; 192,29 MiB frei; 152,37 MiB zwischengespeichert)
 aniketspurohit
am 31. Jan. 2019
aniketspurohit
am 31. Jan. 2019
@aniks23 wir arbeiten an einem Patch, von dem ich glaube, dass er in diesem Fall eine bessere Erfahrung
 fmassa
am 31. Jan. 2019
fmassa
am 31. Jan. 2019
Gibt es eine Möglichkeit zu wissen, wie groß ein Modell oder ein Netzwerk mein System verarbeiten kann?
ohne auf dieses Problem zu stoßen?
Am Freitag, 1. Februar 2019 um 03:55 Uhr Francisco Massa [email protected]
schrieb:
@aniks23 https://github.com/aniks23 wir arbeiten an einem Patch, den ich
glauben wird in diesem Fall bessere Erfahrungen geben. Bleiben Sie dran—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
am 1. Feb. 2019
Ich habe auch diese Nachricht bekommen:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Es ist passiert, als ich versucht habe, die Fast.ai-Lektion zu starten1 Haustiere https://course.fast.ai/ (Zelle 31)
 adrianovieira
am 12. März 2019
adrianovieira
am 12. März 2019
Auch ich laufe in die gleichen Fehler. Mein Modell hat früher mit dem genauen Setup funktioniert, aber jetzt gibt es diesen Fehler, nachdem ich einen scheinbar nicht zusammenhängenden Code geändert habe.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
am 14. März 2019
treble-maker123
am 14. März 2019
Ich weiß nicht, ob mein Szenario mit dem ursprünglichen Problem in Verbindung steht, aber ich habe mein Problem (der OOM-Fehler in der vorherigen Nachricht ging weg) gelöst, indem ich die nn.Sequential-Ebenen in meinem Modell aufgebrochen habe, z
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
zu
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
Mein Modell hat viel mehr davon (5 mehr um genau zu sein). Benutze ich nn.Sequential richtig? Oder ist das ein Bug? @yf225 @fmassa
treble-maker123
am 14. März 2019
Ich bekomme auch einen ähnlichen Fehler:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@treble-maker123, konnten Sie schlüssig beweisen, dass nn.Sequential das Problem ist?
 yasheshgaur
am 17. März 2019
yasheshgaur
am 17. März 2019
Ich habe ein ähnliches Problem. Ich verwende den pytorch-Dataloader. SaysI sollte über 5 GB frei haben, aber es gibt 0 Bytes frei.
RuntimeError Traceback (letzter Aufruf zuletzt)
22
23 Daten, Eingänge = Zustände_Eingänge
---> 24 Daten, Eingänge = Variable(data).float().to(device), Variable(inputs).float().to(device)
25 drucken (data.device)
26 enc_out = Encoder (Daten)
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 11,00 MiB zuzuweisen (GPU 0; 6,00 GiB Gesamtkapazität; 448,58 MiB bereits zugewiesen; 0 Byte frei; 942,00 KiB zwischengespeichert)
 ahsteven
am 3. Apr. 2019
ahsteven
am 3. Apr. 2019
Hallo, ich habe auch diesen Fehler.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
am 17. Apr. 2019
AlbertZhangHIT
am 17. Apr. 2019
Leider bin ich auch auf das gleiche Problem gestoßen.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
Ich habe mein Modell in einem Cluster von Servern trainiert und der Fehler ist unvorhersehbar bei einem meiner Server aufgetreten. Auch solche kabelgebundenen Fehler treten nur in einer meiner Trainingsstrategien auf. Und der einzige Unterschied besteht darin, dass ich den Code während der Datenerweiterung ändere und die Datenvorverarbeitung komplizierter mache als andere. Aber ich bin mir nicht sicher, wie ich dieses Problem lösen soll.
 qingyu-wang
am 25. Apr. 2019
qingyu-wang
am 25. Apr. 2019
Dieses Problem habe ich auch. Wie man es löst??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
am 10. Mai 2019
nabil2i
am 10. Mai 2019
Gleiches Problem hier RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
am 16. Mai 2019
williamluke4
am 16. Mai 2019
@fmassa Hast du mehr Infos dazu?
williamluke4
am 18. Mai 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
Bei mir das gleiche Problem
Lieber, hast du die Lösung?
(Basis) F:\Suresh\st-gcn>python main1.py Erkennung -c config/st_gcn/ntu-xsub/train.yaml --device 0 --work_dir ./work_dir
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117: UserWarning:
GPU0 TITAN Xp gefunden, das die Cuda-Fähigkeit 1.1 hat.
PyTorch unterstützt diese GPU nicht mehr, da sie zu alt ist.
warnings.warn(old_gpu_warn % (d, name, major, Capability[1]))
[22.05.19|12:02:41] Parameter:
{'base_lr': 0.1, 'ignore_weights': [], 'model': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0.0001, 'work_dir': './work_dir', 'save_interval ': 10, 'model_args': {'in_channels': 3, 'dropout': 0.5, 'num_class': 60, 'edge_importance_weighting': True, 'graph_args': {'strategy': 'spatial', 'layout': 'ntu-rgb+d'}}, 'debug': False, 'pavi_log': False, 'save_result': False, 'config': 'config/st_gcn/ntu-xsub/train.yaml', 'optimizer': 'SGD', 'weights': Keine, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'step': [10, 50], 'use_gpu ': True, 'phase': 'train', 'print_log': True, 'log_interval': 100, 'feeder': 'feeder.feeder.Feeder', 'start_epoch': 0, 'nesterov': True, 'device ': [0], 'save_log': True, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU- RGB-D/xsub/val_label.pkl'}, 'train_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/train_data.npy', 'debug': False, 'label_path': ' ./data/NTU-RGB-D/xsub/train_l abel.pkl'}, 'num_worker': 4}
[22.05.19|12:02:41] Trainingsepoche: 0
Traceback (letzter Anruf zuletzt):
Datei "main1.py", Zeile 31, in
p.start()
Datei "F:\Suresh\st-gcn\processor\processor.py", Zeile 113, in start
self.train()
Datei "F:\Suresh\st-gcn\processor\recognition.py", Zeile 91, in Zug
Ausgabe = self.model (Daten)
Datei "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", Zeile 489, in __call__
result = self.forward( input, * kwargs)
Datei "F:\Suresh\st-gcn\net\st_gcn.py", Zeile 82, in Vorwärtsrichtung
x, _ = gcn(x, self.A * Wichtigkeit)
Datei "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", Zeile 489, in __call__
result = self.forward( input, * kwargs)
Datei "F:\Suresh\st-gcn\net\st_gcn.py", Zeile 194, in Vorwärtsrichtung
x, A = self.gcn(x, A)
Datei "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", Zeile 489, in __call__
result = self.forward( input, * kwargs)
Datei "F:\Suresh\st-gcn\net\utils\tgcn.py", Zeile 60, in Vorwärtsrichtung
x = self.conv(x)
Datei "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", Zeile 489, in __call__
result = self.forward( input, * kwargs)
Datei "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py", Zeile 320, vorwärts
Selbstauffüllung, Selbstdilatation, Selbstgruppen)
RuntimeError: CUDA zu wenig Speicher. Versuch, 1,37 GiB zuzuweisen (GPU 0; 12,00 GiB Gesamtkapazität; 8,28 GiB bereits zugewiesen; 652,75 MiB frei; 664,38 MiB zwischengespeichert)
 Sureshthommandru
am 22. Mai 2019
Sureshthommandru
am 22. Mai 2019
Dies liegt daran, dass der Mini-Batch von Daten nicht auf den GPU-Speicher passt. Verringern Sie einfach die Batchgröße. Wenn ich die Batchgröße = 256 für den cifar10-Datensatz setze, erhalte ich den gleichen Fehler; Dann setze ich die Batchgröße = 128, es ist gelöst.
 balcilar
am 1. Juni 2019
balcilar
am 1. Juni 2019
Ja @balcilar hat recht, ich habe die Batchgröße reduziert und jetzt funktioniert es
 EKELE-NNOROM
am 4. Juni 2019
EKELE-NNOROM
am 4. Juni 2019
Ich habe ein ähnliches Problem:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
Ich verwende 8 V100, um das Modell zu trainieren. Der verwirrende Teil ist, dass immer noch 3,03 GB zwischengespeichert sind und diese nicht für 11,88 MB zugewiesen werden können.
 magic282
am 10. Juni 2019
magic282
am 10. Juni 2019
Hast du die Batchgröße geändert? Reduzieren Sie die Batchgröße um die Hälfte. Sag die Charge
size ist 16 zu implementieren, versuchen Sie es mit einer Batchgröße von 8 und sehen Sie, ob es funktioniert.
Genießen
Am Mo, 10.06.2019 um 02:10 Uhr schrieb magic282 [email protected] :
Ich habe ein ähnliches Problem:
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 11,88 MiB zuzuweisen (GPU 4; 15,75 GiB Gesamtkapazität; 10,50 GiB bereits zugewiesen; 1,88 MiB frei; 3,03 GiB zwischengespeichert)
Ich verwende 8 V100, um das Modell zu trainieren. Der verwirrende Teil ist, dass es
immer noch 3,03 GB zwischengespeichert und es können nicht 11,88 MB zugewiesen werden.—
Sie erhalten dies, weil Sie einen Kommentar abgegeben haben.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63KTLNWW2HJLKTLNMVXGO
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
am 10. Juni 2019
Ich habe versucht, die Batchgröße zu reduzieren und es hat funktioniert. Der verwirrende Teil ist die Fehlermeldung, dass der zwischengespeicherte Speicher größer ist als der zuzuweisende Speicher.
magic282
am 11. Juni 2019
Das gleiche Problem tritt bei einem vortrainierten Modell auf, wenn ich vorhersagen verwende . Das Verringern der Batchgröße wird also nicht funktionieren.
 pvk444
am 30. Juni 2019
pvk444
am 30. Juni 2019
Wenn Sie auf die neueste Version von PyTorch aktualisieren, haben Sie möglicherweise weniger solche Fehler
fmassa
am 30. Juni 2019
Darf ich fragen, warum die Zahlen im Fehler nicht zusammenpassen?!
Ich (wie Sie alle) bekomme:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
Für mich bedeutet das, dass folgendes in etwa zutreffen sollte:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
Aber es ist nicht. Was mache ich falsch?
 AzimAhmadzadeh
am 3. Juli 2019
AzimAhmadzadeh
am 3. Juli 2019
Ich habe auch das Problem, als ich das U-Netz trainiert habe, der Cache reicht, aber es stürzt immer noch ab
 tongpinmo
am 10. Juli 2019
tongpinmo
am 10. Juli 2019
Ich habe den gleichen Fehler...
RuntimeError: CUDA zu wenig Speicher. Versuch, 312,00 MiB zuzuweisen (GPU 0; 10,91 GiB Gesamtkapazität; 1,07 GiB bereits zugewiesen; 109,62 MiB frei; 15,21 MiB zwischengespeichert)
 MSKazemi
am 10. Juli 2019
MSKazemi
am 10. Juli 2019
Versuchen Sie, die Größe zu reduzieren (jede Größe, die das Ergebnis nicht ändert), wird funktionieren.
 giangnguyen2412
am 11. Juli 2019
giangnguyen2412
am 11. Juli 2019
Versuchen Sie, die Größe zu reduzieren (jede Größe, die das Ergebnis nicht ändert), wird funktionieren.
Hallo, ich ändere die batch_size auf 1, aber es funktioniert nicht!
 BCWang93
am 14. Juli 2019
BCWang93
am 14. Juli 2019
Vielleicht sollten Sie eine andere Größe ändern.
Vào 21:50, CN, 14 Th7, 2019 Bcw93 [email protected] ã viết:
Versuchen Sie, die Größe zu reduzieren (jede Größe, die das Ergebnis nicht ändert), wird funktionieren.
Hallo, ich ändere die batch_size auf 1, aber es funktioniert nicht!
—
Sie erhalten dies, weil Sie einen Kommentar abgegeben haben.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBWLOKTDN5WSW2HJment4EWVBW63LNMVXHJM4
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
am 15. Juli 2019
Bekomme diesen Fehler:
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 2,00 MiB zuzuweisen (GPU 0; 7,94 GiB Gesamtkapazität; 7,33 GiB bereits zugewiesen; 1,12 MiB frei; 40,48 MiB zwischengespeichert)
nvidia-smi
Do 22. August 21:05:52 2019
+---------------------------------------------------------------- ----------------------------------------+
| NVIDIA-SMI 430.40 Treiberversion: 430.40 CUDA-Version: 10.1 |
|-------------------------------+----------------- -----+------------------------+
| GPU-Name Persistenz-M| Bus-Id Disp.A | Flüchtige Unkorr. ECC |
| Lüftertemp. Perf.
|===============================+================= =====+======================|
| 0 Quadro M4000 Aus | 00000000:09:00.0 Ein | Nicht zutreffend |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% Standard |
+------------------------------------------+----------------- -----+------------------------+
| 1 GeForce GTX 105... Aus | 00000000:41:00.0 Ein | Nicht zutreffend |
| 29% 33C P8 N/A / 75W | 262MiB / 4032MiB | 0% Standard |
+------------------------------------------+----------------- -----+------------+
+---------------------------------------------------------------- ----------------------------+
| Prozesse: GPU-Speicher |
| GPU PID-Typ Prozessname Verwendung |
|================================================ ============================|
| 0 1909 G /usr/lib/xorg/Xorg 50MiB |
| 1 1909 G /usr/lib/xorg/Xorg 128MiB |
| 1 5236 G ...quest-channel-token=9884100064965360199 130MiB |
+---------------------------------------------------------------- ----------------------------------------+
Betriebssystem: Ubuntu 18.04 bionic
Kernel: x86_64 Linux 4.15.0-58-generic
Betriebszeit: 29m
Pakete: 2002
Shell: bash 4.4.20
Auflösung: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
GTK-Theme: Lubuntu-Standard [GTK2]
Symbolthema: Lubuntu
Schriftart: Ubuntu 11
CPU: AMD Ryzen Threadripper 2970WX 24-Core @ 48x 3GHz [61,8°C]
GPU: Quadro M4000, GeForce GTX 1050 Ti
Arbeitsspeicher: 3194 MiB / 64345 MiB
 danindiana
am 23. Aug. 2019
danindiana
am 23. Aug. 2019
Ist das behoben? Ich habe sowohl die Größe als auch die Batchgröße auf 1 verringert. Ich sehe hier keine anderen Lösungen, aber dieses Ticket ist geschlossen. Ich habe das gleiche Problem mit Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
am 6. Sept. 2019
hughkf
am 6. Sept. 2019
@hughkf Wo im Code ändern Sie batch_size?
 aidoshacks
am 6. Sept. 2019
aidoshacks
am 6. Sept. 2019
@aidoshacks , Es hängt von Ihrem Code ab. Aber hier ist ein Beispiel. Dies ist eines der Notebooks, die dieses Problem zuverlässig auf meinem Computer verursachen: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. Ich ändere die folgende Zeile,
bs,size = 8,src_size//2 zu bs,size = 1,1 aber immer noch bekomme ich dieses Problem mit dem Speicher.
hughkf
am 6. Sept. 2019
Für mich hat das Ändern der batch_size von 128 auf 64 funktioniert, aber das scheint mir keine offengelegte Lösung zu sein, oder übersehe ich etwas?
 shalgi
am 19. Sept. 2019
shalgi
am 19. Sept. 2019
Hat sich dieses Problem gelöst? Ich habe auch das gleiche Problem. Ich habe nichts an meinem Code geändert, aber nach mehrmaliger Ausführung tritt dieser Fehler auf:
"RuntimeError: CUDA out of memory. Versuch, 40,00 MiB zuzuweisen (GPU 0; 15,77 GiB Gesamtkapazität; 13,97 GiB bereits zugewiesen; 256,00 KiB frei; 824,57 MiB zwischengespeichert)"
 mengxiangming
am 26. Sept. 2019
mengxiangming
am 26. Sept. 2019
Wenn das Problem weiterhin besteht, wäre es schön, wenn der Status auf ungelöst geändert würde.
BEARBEITEN:
Hatte wenig mit der Batch-Größe zu tun, da ich es mit Batch-Größe 1 hinbekomme. Ein Neustart des Kernels hat es für mich behoben und seitdem ist es nicht mehr passiert.
 just-in-kees
am 29. Sept. 2019
just-in-kees
am 29. Sept. 2019
Wie ist also die Auflösung bei Beispielen wie unten (dh viel freier Speicher und der Versuch, sehr wenig zuzuweisen - was sich von einigen Beispielen in diesem Thread unterscheidet, wenn tatsächlich wenig freie Speicherkapazität vorhanden ist und nichts falsch ist)?
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 1,33 GiB zuzuweisen (GPU 1; 31,72 GiB Gesamtkapazität; 5,68 GiB bereits zugewiesen; 24,94 GiB frei ; 5,96 MiB zwischengespeichert)
Ich verstehe nicht, warum das Problem in den Status "Geschlossen" übergegangen ist, da es immer noch auf der neuesten Pytorch-Version (1.2) und der modernen NVIDIA-GPU (V-100) auftritt.
Vielen Dank!
 yuribd
am 3. Okt. 2019
yuribd
am 3. Okt. 2019
Meistens erhalten Sie diese spezielle Fehlermeldung vom Fastai-Paket, weil Sie eine ungewöhnlich kleine GPU verwenden. Ich habe dieses Problem behoben, indem ich meinen Kernel neu gestartet und eine kleinere Stapelgröße für den von Ihnen angegebenen Pfad verwendet habe.
 AurioPinto
am 5. Okt. 2019
AurioPinto
am 5. Okt. 2019
selbes Problem hier. Wenn ich pytorch0.4.1 verwende, Batchgröße=4, ist es in Ordnung. Aber wenn ich zu pytorch1.3 wechsle und sogar die Batchgröße auf 1 setze, habe ich das Oom-Problem.
 Sarah20187
am 21. Okt. 2019
Sarah20187
am 21. Okt. 2019
habe es gelöst, indem ich meine pytorch auf den neuesten Stand gebracht habe ... conda update pytorch
 kafura0
am 21. Okt. 2019
kafura0
am 21. Okt. 2019
Dies liegt daran, dass der Mini-Batch von Daten nicht auf den GPU-Speicher passt. Verringern Sie einfach die Batchgröße. Wenn ich die Batchgröße = 256 für den cifar10-Datensatz setze, erhalte ich den gleichen Fehler; Dann setze ich die Batchgröße = 128, es ist gelöst.
Danke, ich habe den Fehler auf diese Weise behoben.
 zhangzibao
am 25. Okt. 2019
zhangzibao
am 25. Okt. 2019
Ich habe die batch_size auf 8 verringert, es funktioniert gut. Die Idee ist, eine kleine Batch_Größe zu haben
 Asutosh11
am 30. Okt. 2019
Asutosh11
am 30. Okt. 2019
Ich denke, es hängt von der Gesamteingabegröße ab, mit der eine bestimmte Ebene zu tun hat. Wenn beispielsweise ein Stapel von 256 (32 x 32) Bildern 128 Filter in einer Ebene durchläuft, beträgt die Gesamteingabegröße 256 x 32 x 32 x 128 = 2^25. Diese Zahl sollte unter einem bestimmten Schwellenwert liegen, der meiner Meinung nach maschinenspezifisch ist. Für AWS p3.2xlarge zum Beispiel ist es 2^26. Wenn Sie also CuDA-Speicherfehler erhalten, versuchen Sie, die Batchgröße oder die Anzahl der Filter zu reduzieren oder mehr Downsampling wie Stride- oder Pooling-Layer zu verwenden
 souryadey
am 1. Nov. 2019
souryadey
am 1. Nov. 2019
Habe das gleiche Problem:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
Mit der neuesten pytorch (1.3) und cuda (10.1) Version. Nvidia-smi zeigt auch eine halbleere GPU an, so dass die Menge an freiem Speicher in der Fehlermeldung korrekt ist. Kann es noch nicht mit einfachem Code reproduzieren
 ArgentumWalker
am 3. Nov. 2019
ArgentumWalker
am 3. Nov. 2019
Das Zurücksetzen des Kernels hat bei mir auch funktioniert! Hat nicht einmal mit Batchgröße = 1 funktioniert, bis ich das gemacht habe
 kennethjmyers
am 7. Nov. 2019
kennethjmyers
am 7. Nov. 2019
Leute, ich habe mein Problem gelöst, indem ich meine Batchgröße um die Hälfte reduziert habe.
 faizao
am 19. Nov. 2019
faizao
am 19. Nov. 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Nach Neustart behoben
 SomeUserName1
am 22. Nov. 2019
SomeUserName1
am 22. Nov. 2019
Batch_size 64(rtx2080 ti) auf 32(rtx 2060) geändert, Problem behoben. aber ich möchte einen anderen Weg kennen, um diese Art von Problem zu lösen.
 sailfish009
am 3. Dez. 2019
sailfish009
am 3. Dez. 2019
Das passiert mir, wenn ich die Vorhersage mache!
Ich habe die Batchgröße von 1024 auf 8 geändert und bekomme immer noch Fehler, wenn 82% des Testsatzes ausgewertet werden.
Als ich with torch.no_grad() hinzufügte, war das Problem BEHOBEN.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
am 17. Dez. 2019
smasoudn
am 17. Dez. 2019
ich habe das Problem gelöst
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
zu
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
am 27. Dez. 2019
zhonghaochen
am 27. Dez. 2019
Ich hatte das gleiche Problem und habe die GPU-Auslastung auf meinem Computer überprüft. Es wurde viel davon bereits verwendet und es war nur noch sehr wenig Speicher übrig. Ich habe mein Jupyter-Notebook gelöscht und neu gestartet. Speicher wurde frei und die Dinge begannen zu funktionieren. Sie können unten verwenden:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
am 27. Dez. 2019
prabhatsharma
am 27. Dez. 2019
Ich habe auch diese Nachricht bekommen:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Es ist passiert, als ich versucht habe, die Fast.ai-Lektion zu starten1 Haustiere https://course.fast.ai/ (Zelle 31)
Versuchen Sie, die Batchgröße (bs) Ihrer Trainingsdaten zu reduzieren.
Sehen Sie, was für Sie funktioniert.
 rishi0904
am 27. Dez. 2019
rishi0904
am 27. Dez. 2019
Ich fand dieses Problem lösbar, ohne die Batch-Größe anzupassen.
Öffnen Sie das Terminal und eine Python-Eingabeaufforderung
import torch
torch.cuda.empty_cache()
Beenden Sie den Python-Interpreter, führen Sie Ihren ursprünglichen PyTorch-Befehl erneut aus und er sollte (hoffentlich) nicht den CUDA-Speicherfehler ergeben.
 cpoptic
am 3. Jan. 2020
cpoptic
am 3. Jan. 2020
Ich habe herausgefunden, dass dieses Problem normalerweise auftritt, wenn mein Computer zu viel CPU-RAM verwendet. Wenn wir also eine größere Batchgröße wünschen, können wir versuchen, die Auslastung des CPU-RAM zu reduzieren.
 dhKwang
am 13. Jan. 2020
dhKwang
am 13. Jan. 2020
Hatte ein ähnliches Problem.
Das Verringern der Stapelgröße und das Neustarten des Kernels halfen, das Problem zu beheben.
 kumarnikhil936
am 19. Jan. 2020
kumarnikhil936
am 19. Jan. 2020
In meinem Fall löste das Ersetzen des Adam-Optimierers durch den SGD-Optimierer das gleiche Problem.
 tranvanluan2
am 23. Jan. 2020
tranvanluan2
am 23. Jan. 2020
Nun, in meinem Fall habe ich with torch.no_grad(): (train model) , output.to("cpu") und torch.cuda.empty_cache() und dieses Problem gelöst.
 PlanNoa
am 30. Jan. 2020
PlanNoa
am 30. Jan. 2020
RuntimeError: CUDA zu wenig Speicher. Versucht, 54,00 MiB zuzuweisen (GPU 0; 3,95 GiB Gesamtkapazität; 2,65 GiB bereits zugewiesen; 39,00 MiB frei; 87,29 MiB zwischengespeichert)
Ich habe die Lösung gefunden und den Wert von batch_size verringert.
 sagrawal06
am 30. Jan. 2020
sagrawal06
am 30. Jan. 2020
Ich trainiere einen YOLOv3 mit Darknet53-Gewichten auf einem benutzerdefinierten Datensatz. Meine GPU ist eine NVIDIA RTX 2080 und ich hatte das gleiche Problem. Das Ändern der Batchgröße hat das Problem gelöst.
 wilderrodrigues
am 2. Feb. 2020
wilderrodrigues
am 2. Feb. 2020
Ich erhalte diesen Fehler während der Inferenzzeit .... ich bin ru
CUDA hat keinen Speicher mehr. Versuch, 102,00 MiB zuzuweisen (GPU 0; 15,78 GiB Gesamtkapazität; 14,54 GiB bereits zugewiesen; 48,44 MiB frei; 14,67 GiB insgesamt von PyTorch reserviert)
-------------------------------------------------- ---------------------------+
| NVIDIA-SMI 440.59 Treiberversion: 440.59 CUDA-Version: 10.2 |
|-------------------------------+----------------- -----+------------------------+
| GPU-Name Persistenz-M| Bus-Id Disp.A | Flüchtige Unkorr. ECC |
| Lüftertemp. Perf.
|===============================+================= =====+======================|
| 0 Tesla V100-SXM2... Ein | 00000000:00:1E.0 Aus | 0 |
| N/A 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% Standard |
+------------------------------------------+----------------- -----+------------+
+---------------------------------------------------------------- ----------------------------------------+
| Prozesse: GPU-Speicher |
| GPU PID-Typ Prozessname Verwendung |
|================================================ ============================|
| 0 13978 C /.conda/envs/ /bin/python 16101MiB |
+---------------------------------------------------------------- ----------------------------------------+
 tvinith
am 29. Feb. 2020
tvinith
am 29. Feb. 2020
Dies liegt daran, dass der Mini-Batch von Daten nicht auf den GPU-Speicher passt. Verringern Sie einfach die Batchgröße. Wenn ich die Batchgröße = 256 für den cifar10-Datensatz setze, erhalte ich den gleichen Fehler; Dann setze ich die Batchgröße = 128, es ist gelöst.
danke, du hast recht
 Rxma1805
am 2. März 2020
Rxma1805
am 2. März 2020
Für den speziellen Fall, in dem genügend GPU-Speicher vorhanden ist, aber trotzdem ein Fehler ausgegeben wird. In meinem Fall habe ich es gelöst, indem ich die Anzahl der Arbeiter im Dataloader reduziert habe.
 Yurasyk
am 14. März 2020
Yurasyk
am 14. März 2020
Hintergrund
py36, pytorch1.4, tf2.0, conda
Feinabstimmung der Roberta
Problem
Das gleiche Problem wie bei @EMarquer : pycharm zeigt, dass ich noch genügend Arbeitsspeicher habe, weist jedoch fehlgeschlagenen Arbeitsspeicher zu.
Wege, die ich versucht habe
- "batch_size = 1" ist fehlgeschlagen
- "torch.cuda.empty_cache()" ist fehlgeschlagen
- CUDA_VISIBLE_DEVICES="0" Python Run.py fehlgeschlagen
- Da ich kein Jupyter verwende, muss der Kernel nicht neu gestartet werden
Erfolgreicher Weg
- nvidia-smi


- Die Wahrheit ist, dass sich das, was pycharm zeigt, von dem unterscheidet, was "nvidia-smi" zeigt (sorry, ich habe das Bild von pycharm nicht gespeichert), eigentlich nicht genug Speicher .
- Die Prozesse 6123 und 32644 laufen zuvor auf dem Terminal.
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
am 17. März 2020
FernandoZhuang
am 17. März 2020
Was bei mir einfach funktioniert hat:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
am 6. Apr. 2020
MastafaF
am 6. Apr. 2020
Ich fand dieses Problem lösbar, ohne die Batch-Größe anzupassen.
Öffnen Sie das Terminal und eine Python-Eingabeaufforderung
import torch torch.cuda.empty_cache()Beenden Sie den Python-Interpreter, führen Sie Ihren ursprünglichen PyTorch-Befehl erneut aus und er sollte (hoffentlich) nicht den CUDA-Speicherfehler ergeben.
In meinem Fall löst es mein Problem.
 LiEAEX
am 10. Apr. 2020
LiEAEX
am 10. Apr. 2020
Stellen Sie sicher, dass Sie Ihre GPU auf Steckplatz 0 mit --device_ids 0 verwenden
Ich weiß, dass ich die Terminologie schlachte, aber es hat funktioniert. Ich denke, es wird davon ausgegangen, dass Sie die CPU anstelle der GPU verwenden möchten, wenn Sie keine ID auswählen.
 aaron387
am 12. Apr. 2020
aaron387
am 12. Apr. 2020
Ich bekomme den gleichen Fehler:
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 4,84 GiB zuzuweisen (GPU 0; 7,44 GiB Gesamtkapazität; 5,22 GiB bereits zugewiesen; 1,75 GiB frei; 18,51 MiB zwischengespeichert)
Wenn ich den Cluster neu starte oder die Batchgröße ändere, funktioniert es. Aber diese Lösung gefällt mir nicht. Ich habe es sogar probiert (torch.cuda.empty_cache() ), das funktioniert bei mir nicht. Gibt es eine andere effiziente Möglichkeit, dies zu lösen?
 Tann10
am 13. Apr. 2020
Tann10
am 13. Apr. 2020
Ich weiß nicht, ob mein Szenario mit dem ursprünglichen Problem in Verbindung steht, aber ich habe mein Problem (der OOM-Fehler in der vorherigen Nachricht ging weg) gelöst, indem ich die nn.Sequential-Ebenen in meinem Modell aufgebrochen habe, z
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)zu
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))Mein Modell hat viel mehr davon (5 mehr um genau zu sein). Benutze ich nn.Sequential richtig? Oder ist das ein Bug? @yf225 @fmassa
Es scheint, dass ich den ähnlichen Fehler auch umgekehrt löse, aber bei dir.
Ich ändere alles
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)zu
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
am 14. Apr. 2020
xml94
am 14. Apr. 2020
Für mich hat das Ändern von batch_size oder einer der angegebenen Lösungen nicht geholfen. Aber es stellte sich heraus, dass ich in meiner .cfg-Datei falsche Werte für Klassen und Filter in einer Ebene hatte. Wenn also nichts hilft, überprüfen Sie Ihre .cfg.
 ulaszewskim
am 1. Mai 2020
ulaszewskim
am 1. Mai 2020
Terminal öffnen
Erster Typ
nvidia-smi
Wählen Sie dann die PID aus, die dem Python- oder Anaconda-Pfad entspricht, und schreiben Sie
sudo kill -9 PID
 krypticmouse
am 4. Mai 2020
krypticmouse
am 4. Mai 2020
Ich habe diesen Fehler seit einiger Zeit. Für mich stellt sich heraus, dass ich weiterhin eine Python-Variable (dh Fackeltensor) halte, die auf das Modellergebnis verweist, und kann daher nicht sicher freigegeben werden, da der Code weiterhin darauf zugreifen kann.
Mein Code sieht ungefähr so aus:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
Die Lösung hierfür bestand darin, p in eine Liste zu übertragen. Der Code sollte also so aussehen:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
Dadurch wird sichergestellt, dass predictions Werte im Hauptspeicher hält, kein Tensor in der GPU.
 abdelrahmanhosny
am 8. Mai 2020
abdelrahmanhosny
am 8. Mai 2020
Ich habe diesen Fehler mit dem fastai.vision-Modul, das auf pytorch basiert. Ich verwende CUDA 10.1
 jkomyno
am 16. Mai 2020
jkomyno
am 16. Mai 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
reduziere die per_gpu_train_batch_size von 16 auf 8, es hat mein Problem gelöst.
 autodataming
am 3. Juni 2020
autodataming
am 3. Juni 2020
Wenn Sie auf die neueste Version von PyTorch aktualisieren, haben Sie möglicherweise weniger solche Fehler
wirklich, warum sagst du das
 XinyingZheng
am 9. Juni 2020
XinyingZheng
am 9. Juni 2020
Die Hauptfrage dieses Problems ist immer noch ein offenes Problem. Ich erhalte dieselbe seltsame CUDA-Meldung aus dem Speicher. Es wurde versucht, 2,26 GiB in 4,08 GiB frei zuzuweisen. Anscheinend ist genügend Speicher vorhanden, aber es kann nicht zugewiesen werden.
Projektinfo: Das Training eines Resnet 10 über ein Activitynet-Dataset mit Batch-Größe 4 schlägt im Finale der ersten Epoche fehl.
BEARBEITET: Einige Wahrnehmungen: Wenn ich meinen RAM-Speicher bereinige und nur den Python-Code laufen lasse, wird der Fehler nicht ausgelöst. Vielleicht ist genug Speicher in der GPU vorhanden, aber der RAM-Speicher ist nicht in der Lage, alle anderen Verarbeitungsschritte zu bewältigen.
Computerinformationen: Dell G5 - i7 9th - GTX 1660Ti 6GB - 16 GB RAM
BEARBEITET2: Ich habe "_MultiProcessingDataLoaderIter" mit 4 Arbeitern verwendet und es wird die Meldung "Nicht genügend Arbeitsspeicher" im Weiterleitungsaufruf ausgelöst. Wenn ich die Anzahl der Arbeiter auf 1 reduziere, gibt es keinen Fehler. Bei 1 Worker bleibt der RAM-Speicherverbrauch 11/16 GB, bei 4 steigt er auf 14,5/16 GB. Und mit nur einem Arbeiter kann ich die Batch-Größe auf 32 erhöhen und den GPU-Speicher auf 3,5 GB / 6 GB erhöhen.
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 2,26 GiB zuzuweisen (GPU 0; 6,00 GiB Gesamtkapazität; 209,63 MiB bereits zugewiesen; 4,08 GiB frei; 246,00 MiB insgesamt von PyTorch reserviert)
Ganze Fehlermeldung
Traceback (letzter Anruf zuletzt):
Datei "main.py", Zeile 450, in
falls opt.verteilt:
Datei "main.py", Zeile 409, in main_worker
opt.device, current_lr, train_logger,
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\training.py", Zeile 37, in train_epoch
Ausgänge = Modell (Eingänge)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", Zeile 532, in __call__
result = self.forward( input, * kwargs)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py", Zeile 150, weiter vorne
return self.module( input [0], * kwargs[0])
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", Zeile 532, in __call__
result = self.forward( input, * kwargs)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", Zeile 205, weiter vorne
x = self.layer3(x)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", Zeile 532, in __call__
result = self.forward( input, * kwargs)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py", Zeile 100, weiter vorne
Eingang = Modul (Eingang)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", Zeile 532, in __call__
result = self.forward( input, * kwargs)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", Zeile 51, weiter vorne
out = self.conv2(out)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", Zeile 532, in __call__
result = self.forward( input, * kwargs)
Datei "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py", Zeile 480, vorwärts
Selbstauffüllung, Selbstdilatation, Selbstgruppen)
RuntimeError: CUDA zu wenig Speicher. Es wurde versucht, 2,26 GiB zuzuweisen (GPU 0; 6,00 GiB Gesamtkapazität; 209,63 MiB bereits zugewiesen; 4,08 GiB frei; 246,00 MiB reserviert
insgesamt von PyTorch)
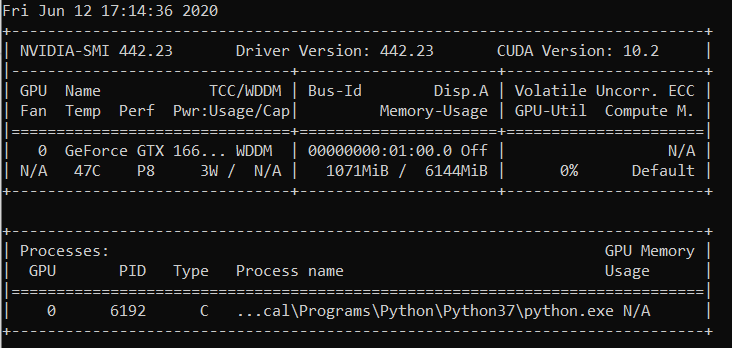
 guilhermesurek
am 12. Juni 2020
guilhermesurek
am 12. Juni 2020
klein die chargengröße, es funktioniert
 cuge1995
am 15. Juni 2020
cuge1995
am 15. Juni 2020
Ich habe diesen Fehler seit einiger Zeit. Für mich stellt sich heraus, dass ich weiterhin eine Python-Variable (dh Fackeltensor) halte, die auf das Modellergebnis verweist, und kann daher nicht sicher freigegeben werden, da der Code weiterhin darauf zugreifen kann.
Mein Code sieht ungefähr so aus:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Die Lösung hierfür bestand darin,
pin eine Liste zu übertragen. Der Code sollte also so aussehen:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Dadurch wird sichergestellt, dass
predictionsWerte im Hauptspeicher hält, kein Tensor in der GPU.
@abdelrahmanhosny Danke für den Hinweis. Ich hatte genau das gleiche Problem in PyTorch 1.5.0 und hatte keine OOM-Probleme während des Trainings, aber während der Inferenz hielt ich auch eine Python-Variable (dh Fackel-Tensor), die auf das Modellergebnis im Speicher verweist, was dazu führte, dass der GPU der Speicher ausging nach einer bestimmten Anzahl von Chargen.
In meinem Fall hat das Übertragen der Vorhersagen in die Liste jedoch nicht funktioniert, da ich mit meinem Netzwerk Bilder erzeuge, daher musste ich Folgendes tun:
predictions.append(p.detach().cpu().numpy())
Damit war das Problem dann gelöst!
 samkellerhals
am 19. Juni 2020
samkellerhals
am 19. Juni 2020
Gibt es eine allgemeine Lösung?
CUDA hat keinen Speicher mehr. Versuch, 196,00 MiB zuzuweisen (GPU 0; 2,00 GiB Gesamtkapazität; 359,38 MiB bereits zugewiesen; 192,29 MiB frei; 152,37 MiB zwischengespeichert)
Gibt es eine allgemeine Lösung?
CUDA hat keinen Speicher mehr. Versuch, 196,00 MiB zuzuweisen (GPU 0; 2,00 GiB Gesamtkapazität; 359,38 MiB bereits zugewiesen; 192,29 MiB frei; 152,37 MiB zwischengespeichert)
 manavkhadka0
am 24. Juni 2020
manavkhadka0
am 24. Juni 2020
Ich habe diesen Fehler seit einiger Zeit. Für mich stellt sich heraus, dass ich weiterhin eine Python-Variable (dh Fackeltensor) halte, die auf das Modellergebnis verweist, und kann daher nicht sicher freigegeben werden, da der Code weiterhin darauf zugreifen kann.
Mein Code sieht ungefähr so aus:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Die Lösung hierfür bestand darin,
pin eine Liste zu übertragen. Der Code sollte also so aussehen:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Dadurch wird sichergestellt, dass
predictionsWerte im Hauptspeicher hält, kein Tensor in der GPU.@abdelrahmanhosny Danke für den Hinweis. Ich hatte genau das gleiche Problem in PyTorch 1.5.0 und hatte keine OOM-Probleme während des Trainings, aber während der Inferenz hielt ich auch eine Python-Variable (dh Fackel-Tensor), die auf das Modellergebnis im Speicher verweist, was dazu führte, dass der GPU der Speicher ausging nach einer bestimmten Anzahl von Chargen.
In meinem Fall hat das Übertragen der Vorhersagen in die Liste jedoch nicht funktioniert, da ich mit meinem Netzwerk Bilder erzeuge, daher musste ich Folgendes tun:
predictions.append(p.detach().cpu().numpy())Damit war das Problem dann gelöst!
Ich habe das gleiche Problem im ParrallelWaveGAN-Modell und habe die Lösungen in # 16417 verwendet, aber es funktioniert nicht für mich
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
gc.collect()
fackel.cuda.empty_cache()
 tuong-olli
am 25. Juni 2020
tuong-olli
am 25. Juni 2020
Hatte das gleiche Problem beim Training.
Das Sammeln von Müll und das Leeren des Cuda-Speichers nach jeder Epoche löste das Problem für mich.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
am 5. Aug. 2020
IsakWesterlundBitville
am 5. Aug. 2020
Was bei mir einfach funktioniert hat:
import gc # Your code with pytorch using GPU gc.collect()
Dankeschön!! Ich hatte Probleme, das Beispiel für Katzen und Hunde auszuführen, und das hat bei mir funktioniert.
 Michelpayan
am 5. Aug. 2020
Michelpayan
am 5. Aug. 2020
Hatte das gleiche Problem beim Training.
Das Sammeln von Müll und das Leeren des Cuda-Speichers nach jeder Epoche löste das Problem für mich.gc.collect() torch.cuda.empty_cache()
Gleiche für mich
 AleksandrTulenkov
am 6. Aug. 2020
AleksandrTulenkov
am 6. Aug. 2020
Verringern Sie die Chargengröße und erhöhen Sie die Epochen. so habe ich es gelöst.
 oyekamal
am 18. Sept. 2020
oyekamal
am 18. Sept. 2020
@areebsyed Überprüfen Sie den RAM-Speicher, ich hatte dieses Problem, als viele Arbeiter parallel eingestellt wurden.
guilhermesurek
am 29. Sept. 2020
Ich erhalte auch den gleichen Fehler beim Finetuning des vortrainierten bert2bert EncoderDecoderModel in pytorch in Colab, ohne auch nur eine einzige Epoche abzuschließen.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
am 6. Okt. 2020
Aakash12980
am 6. Okt. 2020
@Aakash12980 haben Sie versucht, die Batchgröße zu reduzieren? Versuchen Sie auch, die Eingabebilder, die Sie trainieren möchten, in der Größe zu ändern
 areebsyed
am 6. Okt. 2020
areebsyed
am 6. Okt. 2020
@areebsyed Ja, ich habe die Batchgröße auf 4 reduziert und es hat funktioniert.
Aakash12980
am 6. Okt. 2020
gleich
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
am 7. Okt. 2020
monajalal
am 7. Okt. 2020
gleich
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal Versuchen Sie, die Batchgröße oder die Eingabedimensionsgröße zu reduzieren.
Aakash12980
am 7. Okt. 2020
Was ist also die Auflösung bei Beispielen wie unten (dh viel _freier_ Speicher und der Versuch, sehr wenig zuzuweisen - was sich von _einigen_ Beispielen in diesem Thread unterscheidet, wenn tatsächlich wenig freie Speicherkapazität vorhanden ist und nichts falsch ist)?
RuntimeError: CUDA zu wenig Speicher. Versuch, _ 1,33 GiB _ zuzuweisen (GPU 1; 31,72 GiB Gesamtkapazität; 5,68 GiB bereits zugewiesen; _ 24,94 GiB frei _; 5,96 MiB zwischengespeichert)
Ich verstehe nicht, warum das Problem in den Status "Geschlossen" übergegangen ist, da es immer noch auf der neuesten Pytorch-Version (1.2) und der modernen NVIDIA-GPU (V-100) auftritt.
Vielen Dank!
Ja, ich habe das Gefühl, dass die meisten Leute nicht erkennen, dass das Problem nicht nur OOM ist, sondern dass es OOM gibt, während der Fehler besagt, dass genügend freier Speicherplatz vorhanden ist. Ich habe dieses Problem auch unter Windows, hast du eine Lösung gefunden?
 YoadTew
am 6. Nov. 2020
YoadTew
am 6. Nov. 2020
Verwandte Themen
 szagoruyko
·
3Kommentare
szagoruyko
·
3Kommentare
 bartvm
·
3Kommentare
bartvm
·
3Kommentare
 keskarnitish
·
3Kommentare
keskarnitish
·
3Kommentare
 mishraswapnil
·
3Kommentare
mishraswapnil
·
3Kommentare
 negrinho
·
3Kommentare
negrinho
·
3Kommentare
Hilfreichster Kommentar
Dies liegt daran, dass der Mini-Batch von Daten nicht auf den GPU-Speicher passt. Verringern Sie einfach die Batchgröße. Wenn ich die Batchgröße = 256 für den cifar10-Datensatz setze, erhalte ich den gleichen Fehler; Dann setze ich die Batchgröße = 128, es ist gelöst.