Pytorch: RuntimeError: CUDA не хватает памяти. Пытался выделить 12,50 МБ (GPU 0; 10,92 ГБ общей емкости; 8,57 МБ уже выделено; 9,28 МБ свободно; 4,68 МБ кэшировано)
Ошибка CUDA Out of Memory, но память CUDA почти пуста
В настоящее время я тренирую легкую модель на очень большом количестве текстовых данных (около 70 ГБ текста).
Для этого я использую машину в кластере ( «grele» кластерной сети grid5000 ).
После 3 часов тренировки я получаю это очень странное сообщение об ошибке CUDA Out of Memory:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
Согласно сообщению, у меня есть необходимое пространство, но оно не выделяет память.
Есть идеи, что может вызвать это?
Для информации, моя предварительная обработка полагается на torch.multiprocessing.Queue и итератор по строкам моих исходных данных для предварительной обработки данных на лету.
Полная трассировка стека
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
Все 91 Комментарий
У меня такая же ошибка времени выполнения:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
27 янв. 2019
OmarBazaraa
27 янв. 2019
@EMarquer @OmarBazaraa Не могли бы вы привести минимальный пример
 yf225
28 янв. 2019
yf225
28 янв. 2019
Я больше не могу воспроизвести проблему, поэтому закрою проблему.
Проблема исчезла, когда я перестал хранить предварительно обработанные данные в ОЗУ.
@OmarBazaraa , я не думаю, что ваша проблема такая же, как моя, например:
- Я пытаюсь выделить 12,50 МБ, из которых 9,28 ГБ свободно
- вы пытаетесь выделить 195,25 МБ, из которых 170,14 МБ свободно
Исходя из моего предыдущего опыта решения этой проблемы, либо вы не освобождаете память CUDA, либо пытаетесь поместить слишком много данных в CUDA.
Не освобождая память CUDA, я имею в виду, что у вас все еще есть ссылки на тензоры в CUDA, которые вы больше не используете. Это предотвратит освобождение выделенной памяти путем удаления тензоров.
EMarquer
28 янв. 2019
Есть какое-нибудь общее решение?
CUDA не хватает памяти. Пытался выделить 196,00 МБ (GPU 0; 2,00 ГБ общей емкости; 359,38 МБ уже выделено; 192,29 МБ свободно; 152,37 МБ кэшировано)
 aniketspurohit
31 янв. 2019
aniketspurohit
31 янв. 2019
@ aniks23, мы работаем над патчем, который, как мне кажется, поможет в этом случае лучше. Будьте на связи
 fmassa
31 янв. 2019
fmassa
31 янв. 2019
Есть ли способ узнать, насколько велика модель или сеть, с которыми может справиться моя система?
не столкнувшись с этой проблемой?
Пт, 1 февраля 2019 г., 3:55, Франсиско Масса [email protected]
написал:
@ aniks23 https://github.com/aniks23 мы работаем над патчем, который я
полагаю, даст лучший опыт в этом случае. Будьте на связи-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
1 февр. 2019
Я тоже получил это сообщение:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Это случилось, когда я пытался запустить Fast.ai урок1 Домашние животные https://course.fast.ai/ (ячейка 31)
 adrianovieira
12 мар. 2019
adrianovieira
12 мар. 2019
Я тоже сталкиваюсь с теми же ошибками. Моя модель раньше работала с точной настройкой, но теперь она выдает эту ошибку после того, как я изменил некоторый, казалось бы, несвязанный код.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
14 мар. 2019
treble-maker123
14 мар. 2019
Я не знаю, связан ли мой сценарий с исходной проблемой, но я решил свою проблему (ошибка OOM в предыдущем сообщении исчезла), разбив слои nn.Sequential в моей модели, например
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
к
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
В моей модели их намного больше (точнее, еще 5). Я использую nn.Sequential right? Или это ошибка? @ yf225 @fmassa
treble-maker123
14 мар. 2019
Я тоже получаю аналогичную ошибку:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@ treble-maker123, смогли ли вы убедительно доказать, что nn. Проблема в последовательном?
 yasheshgaur
17 мар. 2019
yasheshgaur
17 мар. 2019
У меня похожая проблема. Я использую загрузчик данных pytorch. Говорит, что у меня должно быть более 5 ГБ свободного места, но это дает 0 байт бесплатно.
RuntimeError Traceback (последний вызов последним)
22
23 данных, входы = состояния_входы
---> 24 данных, входы = переменная (данные) .float (). To (устройство), Variable (входы) .float (). To (устройство)
25 отпечатков (data.device)
26 enc_out = кодировщик (данные)
RuntimeError: CUDA не хватает памяти. Пытался выделить 11,00 МиБ (GPU 0; 6,00 ГиБ общей емкости; 448,58 МиБ уже выделено; 0 байт свободно; 942,00 КиБ кэшировано)
 ahsteven
3 апр. 2019
ahsteven
3 апр. 2019
Привет, у меня тоже возникла эта ошибка.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
17 апр. 2019
AlbertZhangHIT
17 апр. 2019
К сожалению, я тоже столкнулся с той же проблемой.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
Я обучил свою модель на кластере серверов, и ошибка непредсказуемо произошла на одном из моих серверов. Также такая проводная ошибка случается только в одной из моих тренировочных стратегий. И единственная разница в том, что я изменяю код во время увеличения данных и делаю предварительную обработку данных более сложной, чем другие. Но я не знаю, как решить эту проблему.
 qingyu-wang
25 апр. 2019
qingyu-wang
25 апр. 2019
У меня тоже есть эта проблема. Как это решить ??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
10 мая 2019
nabil2i
10 мая 2019
Та же проблема здесь RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
16 мая 2019
williamluke4
16 мая 2019
@fmassa У вас есть дополнительная информация по этому
williamluke4
18 мая 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
То же самое для меня
Уважаемый, а вы получили решение?
(база) F: \ Suresh \ st-gcn> python main1.py распознавание -c config / st_gcn / ntu-xsub / train.yaml --device 0 --work_dir ./work_dir
C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ cuda__init __. Py: 117: UserWarning:
Обнаружен GPU0 TITAN Xp, имеющий возможности cuda 1.1.
PyTorch больше не поддерживает этот графический процессор, потому что он слишком старый.
warnings.warn (old_gpu_warn% (d, имя, основной предмет, возможность [1]))
[05.22.19 | 12: 02: 41] Параметры:
{'base_lr': 0.1, 'ignore_weights': [], 'model': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0,0001, 'work_dir': './work_dir', 'save_interval ': 10,' model_args ': {' in_channels ': 3,' dropout ': 0.5,' num_class ': 60,' edge_importance_weighting ': True,' graph_args ': {' стратегия ':' пространственный ',' макет ': 'ntu-rgb + d'}}, 'debug': False, 'pavi_log': False, 'save_result': False, 'config': 'config / st_gcn / ntu-xsub / train.yaml', 'optimizer': 'SGD', 'веса': Нет, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'step': [10, 50], 'use_gpu ': True,' phase ':' train ',' print_log ': True,' log_interval ': 100,' feeder ':' feeder.feeder.Feeder ',' start_epoch ': 0,' нестеров ': True,' устройство ': [0],' save_log ': True,' test_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/val_data.npy ',' label_path ':' ./data/NTU- RGB-D / xsub / val_label.pkl '},' train_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/train_data.npy ',' debug ': False,' label_path ':' ./data/NTU-RGB-D/xsub/train_l abel.pkl '},' num_worker ': 4}
[05.22.19 | 12: 02: 41] Эпоха тренировок: 0
Отслеживание (последний вызов последний):
Файл "main1.py", строка 31, в
p.start ()
Файл "F: \ Suresh \ st-gcn \ processor \ processor.py", строка 113, в начале
self.train ()
Файл "F: \ Suresh \ st-gcn \ processor \ распознавание.py", строка 91, в поезде
output = self.model (данные)
Файл "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", строка 489, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "F: \ Suresh \ st-gcn \ net \ st_gcn.py", строка 82, вперед
x, _ = gcn (x, self.A * важность)
Файл "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", строка 489, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "F: \ Suresh \ st-gcn \ net \ st_gcn.py", строка 194, вперед
х, А = self.gcn (х, А)
Файл "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", строка 489, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "F: \ Suresh \ st-gcn \ net \ utils \ tgcn.py", строка 60, вперед
x = self.conv (x)
Файл "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", строка 489, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ conv.py", строка 320, вперед
self.padding, self.dilation, self.groups)
RuntimeError: CUDA не хватает памяти. Пытался выделить 1,37 ГиБ (GPU 0; 12,00 ГиБ общей емкости; 8,28 ГиБ уже выделено; 652,75 МиБ свободно; 664,38 МиБ кэшировано)
 Sureshthommandru
22 мая 2019
Sureshthommandru
22 мая 2019
Это связано с тем, что мини-пакет данных не помещается в память графического процессора. Просто уменьшите размер партии. Когда я установил размер пакета = 256 для набора данных cifar10, я получил ту же ошибку; Потом ставлю размер партии = 128, решается.
 balcilar
1 июн. 2019
balcilar
1 июн. 2019
Да @balcilar прав, я уменьшил размер партии и теперь работает
 EKELE-NNOROM
4 июн. 2019
EKELE-NNOROM
4 июн. 2019
У меня похожая проблема:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
Я использую 8 V100 для обучения модели. Непонятная часть состоит в том, что кэшируется 3,03 ГБ, и его нельзя выделить для 11,88 МБ.
 magic282
10 июн. 2019
magic282
10 июн. 2019
Вы меняли размер партии. Уменьшите размер партии вдвое. Скажите партию
size - 16, попробуйте использовать размер пакета 8 и посмотрите, работает ли он.
Наслаждаться
В понедельник, 10 июня 2019 г., в 2:10 утра magic282 [email protected] написал:
У меня похожая проблема:
RuntimeError: CUDA не хватает памяти. Пытался выделить 11,88 МиБ (GPU 4; 15,75 ГиБ общей емкости; 10,50 ГиБ уже выделено; 1,88 МиБ свободно; 3,03 ГиБ кэшировано)
Я использую 8 V100 для обучения модели. Непонятная часть состоит в том, что есть
по-прежнему кэшировано 3,03 ГБ, и его нельзя выделить для 11,88 МБ.-
Вы получили это, потому что прокомментировали.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFMVREG22HWWWK3TUL52HS4DNVMVR02HWX4DFMVRG02HWX4DFMVR02
или отключить поток
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
10 июн. 2019
Я попытался уменьшить размер партии, и это сработало. Запутывающая часть - это сообщение об ошибке, что кэшированная память больше, чем выделяемая память.
magic282
11 июн. 2019
Я получаю ту же проблему на предварительно обученной модели, когда использую прогнозирование . Так что уменьшить размер партии не получится.
 pvk444
30 июн. 2019
pvk444
30 июн. 2019
Если вы обновитесь до последней версии PyTorch, у вас может быть меньше таких ошибок.
fmassa
30 июн. 2019
Могу я спросить, почему числа в ошибке не сходятся ?!
Я (как и все вы) получаю:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
Для меня это означает, что примерно верно следующее:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
Но это не так. Что я ошибаюсь?
 AzimAhmadzadeh
3 июл. 2019
AzimAhmadzadeh
3 июл. 2019
У меня также возникла проблема, когда я тренировал U-net, кеша достаточно, но он все равно вылетает
 tongpinmo
10 июл. 2019
tongpinmo
10 июл. 2019
У меня такая же ошибка ...
RuntimeError: CUDA не хватает памяти. Пытался выделить 312,00 МБ (GPU 0; 10,91 ГБ общей емкости; 1,07 ГБ уже выделено; 109,62 МБ свободно; 15,21 МБ кэшировано)
 MSKazemi
10 июл. 2019
MSKazemi
10 июл. 2019
попробуйте уменьшить размер (любой размер, который не повлияет на результат), подойдет.
 giangnguyen2412
11 июл. 2019
giangnguyen2412
11 июл. 2019
попробуйте уменьшить размер (любой размер, который не повлияет на результат), подойдет.
Здравствуйте, я меняю batch_size на 1, но это не работает!
 BCWang93
14 июл. 2019
BCWang93
14 июл. 2019
Возможно, вам стоит изменить другой размер.
Vào 21:50, CN, 14 Th7, 2019 Bcw93 [email protected] ã viết:
попробуйте уменьшить размер (любой размер, который не повлияет на результат), подойдет.
Здравствуйте, я меняю batch_size на 1, но это не работает!
-
Вы получили это, потому что прокомментировали.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFMVREG1
или отключить поток
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
15 июл. 2019
Получение этой ошибки:
RuntimeError: CUDA не хватает памяти. Пытался выделить 2,00 МБ (GPU 0; 7,94 ГБ общей емкости; 7,33 ГБ уже выделено; 1,12 МБ свободно; 40,48 МБ кэшировано)
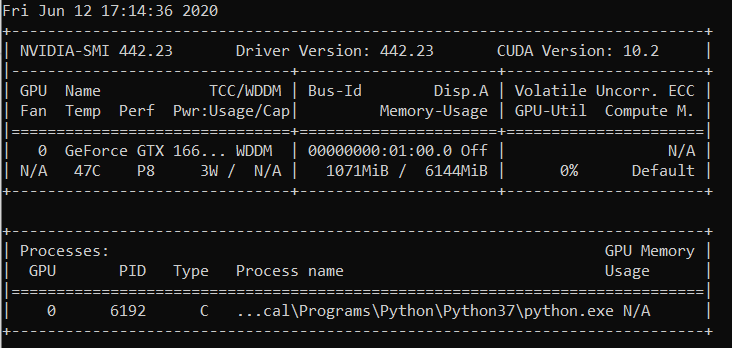
nvidia-smi
Чт 22 августа 21:05:52 2019
+ ------------------------------------------------- ---------------------------- +
| NVIDIA-SMI 430.40 Версия драйвера: 430.40 Версия CUDA: 10.1 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| Имя GPU Persistence-M | Bus-Id Disp.A | Неустойчивый Uncorr. ECC |
| Fan Temp Perf Pwr: Использование / Крышка | Использование памяти | GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 Quadro M4000 выкл. | 00000000: 09: 00.0 Вкл | N / A |
| 46% 37C P8 12 Вт / 120 Вт | 71MiB / 8126MiB | 10% По умолчанию |
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1 GeForce GTX 105 ... Выкл. | 00000000: 41: 00.0 Вкл | N / A |
| 29% 33C P8 N / A / 75W | 262 МБ / 4032 МБ | 0% По умолчанию |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| Процессы: Память GPU |
| Тип PID графического процессора Имя процесса Использование |
| ================================================= ============================ |
| 0 1909 G / usr / lib / xorg / Xorg 50MiB |
| 1 1909 г / usr / lib / xorg / Xorg 128MiB |
| 1 5236 G ... quest-channel-token = 9884100064965360199 130MiB |
+ ------------------------------------------------- ---------------------------- +
ОС: Ubuntu 18.04 bionic
Ядро: x86_64 Linux 4.15.0-58-generic
Время работы: 29 мин.
Пакеты: 2002
Оболочка: bash 4.4.20
Разрешение: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
Тема GTK: Lubuntu по умолчанию [GTK2]
Тема значка: Lubuntu
Шрифт: Ubuntu 11
Процессор: AMD Ryzen Threadripper 2970WX, 24 ядра, 48x 3 ГГц [61,8 ° C]
Графический процессор: Quadro M4000, GeForce GTX 1050 Ti
Оперативная память: 3194 МБ / 64345 МБ
 danindiana
23 авг. 2019
danindiana
23 авг. 2019
Это исправлено? Я уменьшил размер и размер пакета до 1. Я не вижу здесь других решений, но этот билет закрыт. У меня такая же проблема с Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
6 сент. 2019
hughkf
6 сент. 2019
@hughkf Где в коде вы меняете batch_size?
 aidoshacks
6 сент. 2019
aidoshacks
6 сент. 2019
@aidoshacks , это зависит от вашего кода. Но вот один пример. Это один из ноутбуков, который надежно вызывает эту проблему на моем компьютере: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. Я меняю следующую строку,
bs,size = 8,src_size//2 to bs,size = 1,1 но все же у меня проблема с памятью.
hughkf
6 сент. 2019
Для меня изменение batch_size со 128 на 64 сработало, но это не похоже на раскрытое решение для меня, или я чего-то упускаю?
 shalgi
19 сент. 2019
shalgi
19 сент. 2019
Эта проблема решена? У меня такая же проблема. Я ничего не менял в своем коде, но после многократного запуска возникает такая ошибка:
«RuntimeError: CUDA не хватает памяти. Пытался выделить 40,00 МиБ (GPU 0; 15,77 ГиБ общей емкости; 13,97 ГиБ уже выделено; 256,00 КиБ свободно; 824,57 МиБ кэшировано)»
 mengxiangming
26 сент. 2019
mengxiangming
26 сент. 2019
По-прежнему существует эта проблема, было бы хорошо, если бы статус был изменен на нерешенный.
РЕДАКТИРОВАТЬ:
Имеет мало общего с размером пакета, поскольку я получаю его с размером пакета 1. Перезапуск ядра исправил это для меня, и с тех пор этого не происходило.
 just-in-kees
29 сент. 2019
just-in-kees
29 сент. 2019
Итак, каково разрешение в примерах, подобных приведенным ниже (т.е. много свободной памяти и попытка выделить очень мало - что отличается от некоторых примеров в этом потоке, когда на самом деле мало свободной памяти и все в порядке)?
RuntimeError: CUDA не хватает памяти. Пытался выделить 1,33 ГиБ (GPU 1; 31,72 ГиБ общая емкость; 5,68 ГиБ уже выделено; 24,94 ГиБ свободно ; 5,96 МиБ кэшировано)
Я не понимаю, почему проблема перешла в статус 'Closed', поскольку это все еще происходит на последней версии pytorch (1.2) и современном графическом процессоре NVIDIA (V-100).
Спасибо!
 yuribd
3 окт. 2019
yuribd
3 окт. 2019
В большинстве случаев вы получаете это конкретное сообщение об ошибке из пакета fastai из-за того, что вы используете необычно маленький графический процессор. Я исправил эту проблему, перезапустив ядро и используя меньший размер пакета для пути, который вы указываете.
 AurioPinto
5 окт. 2019
AurioPinto
5 окт. 2019
такая же проблема здесь. Когда я использую pytorch0.4.1, размер партии = 4, все в порядке. Но когда я перехожу на pytorch1.3 и даже устанавливаю размер партии равным 1, у меня возникает проблема с oom.
 Sarah20187
21 окт. 2019
Sarah20187
21 окт. 2019
решил это, обновив мой pytorch до последней ... conda update pytorch
 kafura0
21 окт. 2019
kafura0
21 окт. 2019
Это связано с тем, что мини-пакет данных не помещается в память графического процессора. Просто уменьшите размер партии. Когда я установил размер пакета = 256 для набора данных cifar10, я получил ту же ошибку; Потом ставлю размер партии = 128, решается.
спасибо, я исправил ошибку таким образом.
 zhangzibao
25 окт. 2019
zhangzibao
25 окт. 2019
Я уменьшил batch_size до 8, работает нормально. Идея состоит в том, чтобы иметь небольшой размер batch_size
 Asutosh11
30 окт. 2019
Asutosh11
30 окт. 2019
Я думаю, это зависит от общего размера ввода, с которым имеет дело конкретный слой. Например, если пакет из 256 (32x32) изображений проходит через 128 фильтров в слое, общий размер входных данных составляет 256x32x32x128 = 2 ^ 25. Это число должно быть ниже некоторого порога, который, я думаю, зависит от машины. Например, для AWS p3.2xlarge это 2 ^ 26. Поэтому, если вы получаете ошибки памяти CuDA, попробуйте уменьшить размер пакета или количество фильтров или добавить больше понижающей дискретизации, например, шаг или объединение слоев.
 souryadey
1 нояб. 2019
souryadey
1 нояб. 2019
Есть такая же проблема:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
С последней версией pytorch (1.3) и cuda (10.1). Nvidia-smi также показывает полупустой графический процессор, поэтому количество свободной памяти в сообщении об ошибке указано правильно. Пока не могу воспроизвести это простым кодом
 ArgentumWalker
3 нояб. 2019
ArgentumWalker
3 нояб. 2019
Сброс ядра у меня тоже сработал! Не работал даже с размером партии = 1, пока я не сделал это
 kennethjmyers
7 нояб. 2019
kennethjmyers
7 нояб. 2019
Ребята, я решил свою проблему, уменьшив размер партии вдвое.
 faizao
19 нояб. 2019
faizao
19 нояб. 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Исправлено после перезагрузки
 SomeUserName1
22 нояб. 2019
SomeUserName1
22 нояб. 2019
изменил batch_size 64 (rtx2080 ti) на 32 (rtx 2060), проблема решена. но я хочу знать другой способ решить эту проблему.
 sailfish009
3 дек. 2019
sailfish009
3 дек. 2019
Это происходит со мной, когда я делаю предсказания !
Я изменил размер пакета с 1024 на 8 и все еще получаю ошибку, когда оценивается 82% тестового набора.
Когда я добавил with torch.no_grad() проблема была РЕШЕНА.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
17 дек. 2019
smasoudn
17 дек. 2019
Я решил проблему
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
к
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
27 дек. 2019
zhonghaochen
27 дек. 2019
У меня была такая же проблема, и я проверил использование графического процессора на своей машине. Многие из них уже использовались, и оставалось очень мало памяти. Я убил свой ноутбук jupyter и перезапустил его. память освободилась и все заработало. Вы можете использовать ниже:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
27 дек. 2019
prabhatsharma
27 дек. 2019
Я тоже получил это сообщение:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Это случилось, когда я пытался запустить Fast.ai урок1 Домашние животные https://course.fast.ai/ (ячейка 31)
Постарайтесь уменьшить размер пакета (bs) ваших обучающих данных.
Посмотрите, что вам подходит.
 rishi0904
27 дек. 2019
rishi0904
27 дек. 2019
Я нашел эту проблему решаемой, не изменяя размер партии.
Откройте терминал и подсказку Python
import torch
torch.cuda.empty_cache()
Выйдите из интерпретатора Python, повторно запустите исходную команду PyTorch, и она (надеюсь) не должна выдавать ошибку памяти CUDA.
 cpoptic
3 янв. 2020
cpoptic
3 янв. 2020
Я обнаружил, что эта проблема обычно возникает, когда мой компьютер использует слишком много оперативной памяти ЦП. Поэтому, когда нам нужен больший размер пакета, мы можем попытаться уменьшить использование ОЗУ ЦП.
 dhKwang
13 янв. 2020
dhKwang
13 янв. 2020
Была аналогичная проблема.
Уменьшение размера пакета и перезапуск ядра помогли решить проблему.
 kumarnikhil936
19 янв. 2020
kumarnikhil936
19 янв. 2020
В моем случае замена оптимизатора Adam на оптимизатор SGD решила ту же проблему.
 tranvanluan2
23 янв. 2020
tranvanluan2
23 янв. 2020
Ну, в моем случае использовались with torch.no_grad(): (train model) , output.to("cpu") и torch.cuda.empty_cache() и эта проблема решена.
 PlanNoa
30 янв. 2020
PlanNoa
30 янв. 2020
RuntimeError: CUDA не хватает памяти. Пытался выделить 54,00 МиБ (GPU 0; 3,95 ГиБ общей емкости; 2,65 ГиБ уже выделено; 39,00 МиБ свободно; 87,29 МиБ кэшировано)
Я нашел решение и уменьшил значение batch_size.
 sagrawal06
30 янв. 2020
sagrawal06
30 янв. 2020
Я тренирую YOLOv3 с весами Darknet53 на настраиваемом наборе данных. Мой графический процессор - NVIDIA RTX 2080, и я столкнулся с той же проблемой. Это решило изменение размера партии.
 wilderrodrigues
2 февр. 2020
wilderrodrigues
2 февр. 2020
Я получаю эту ошибку во время логического вывода .... я ру
CUDA не хватает памяти. Пытался выделить 102,00 МиБ (GPU 0; 15,78 ГиБ общая емкость; 14,54 ГиБ уже выделено; 48,44 МиБ свободно; 14,67 ГиБ зарезервировано всего PyTorch)
-------------------------------------------------- --------------------------- +
| NVIDIA-SMI 440.59 Версия драйвера: 440.59 Версия CUDA: 10.2 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| Имя GPU Persistence-M | Bus-Id Disp.A | Неустойчивый Uncorr. ECC |
| Fan Temp Perf Pwr: Использование / Крышка | Использование памяти | GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 Tesla V100-SXM2 ... Вкл | 00000000: 00: 1E.0 Выкл. | 0 |
| НЕТ 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% По умолчанию |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| Процессы: Память GPU |
| Тип PID графического процессора Имя процесса Использование |
| ================================================= ============================ |
| 0 13978 C
+ ------------------------------------------------- ---------------------------- +
 tvinith
29 февр. 2020
tvinith
29 февр. 2020
Это связано с тем, что мини-пакет данных не помещается в память графического процессора. Просто уменьшите размер партии. Когда я установил размер пакета = 256 для набора данных cifar10, я получил ту же ошибку; Потом ставлю размер партии = 128, решается.
спасибо, ты прав
 Rxma1805
2 мар. 2020
Rxma1805
2 мар. 2020
Для конкретного случая, когда памяти графического процессора достаточно, но ошибка все равно выдается. В моем случае я решил это, уменьшив количество рабочих в загрузчике данных.
 Yurasyk
14 мар. 2020
Yurasyk
14 мар. 2020
Фон
py36, pytorch1.4, tf2.0, conda
настроить Роберту
Проблема
Проблема такая же, как у pycharm показывает, что у меня все еще достаточно памяти, но не удалось выделить память, из памяти.
Способы, которые я пробовал
- "batch_size = 1" не удалось
- "torch.cuda.empty_cache ()" не удалось
- CUDA_VISIBLE_DEVICES = "0" не удалось выполнить python Run.py
- Поскольку я не использую jupyter, перезапускать ядро не нужно.
Удачный путь
- nvidia-smi


- Правда в том, что то, что показывает pycharm, отличается от того, что показывает "nvidia-smi" (извините, я не сохранил картинку pycharm), на самом деле недостаточно памяти .
- Процессы 6123 и 32644 раньше выполнялись на терминале.
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
17 мар. 2020
FernandoZhuang
17 мар. 2020
Что у меня просто сработало:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
6 апр. 2020
MastafaF
6 апр. 2020
Я нашел эту проблему решаемой, не изменяя размер партии.
Откройте терминал и подсказку Python
import torch torch.cuda.empty_cache()Выйдите из интерпретатора Python, повторно запустите исходную команду PyTorch, и она (надеюсь) не должна выдавать ошибку памяти CUDA.
В моем случае это решает мою проблему.
 LiEAEX
10 апр. 2020
LiEAEX
10 апр. 2020
Убедитесь, что вы используете свой графический процессор в слоте 0 с --device_ids 0
Я знаю, что теряю терминологию, но это сработало. Я предполагаю, что это предполагает, что вы хотите использовать CPU вместо GPU, если вы не выбираете идентификатор.
 aaron387
12 апр. 2020
aaron387
12 апр. 2020
Я получаю ту же ошибку:
RuntimeError: CUDA не хватает памяти. Пытался выделить 4,84 ГиБ (GPU 0; 7,44 ГиБ общей емкости; 5,22 ГиБ уже выделено; 1,75 ГиБ свободно; 18,51 МиБ кэшировано)
Когда я перезапускаю кластер или меняю размер пакета, он работает. Но мне это решение не нравится. Я даже пробовал torch.cuda.empty_cache (), у меня это не работает. Есть ли другой эффективный способ решить эту проблему?
 Tann10
13 апр. 2020
Tann10
13 апр. 2020
Я не знаю, связан ли мой сценарий с исходной проблемой, но я решил свою проблему (ошибка OOM в предыдущем сообщении исчезла), разбив слои nn.Sequential в моей модели, например
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)к
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))В моей модели их намного больше (точнее, еще 5). Я использую nn.Sequential right? Или это ошибка? @ yf225 @fmassa
Кажется, я тоже решаю аналогичную ошибку, но наоборот с вами.
Я меняю все
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)к
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
14 апр. 2020
xml94
14 апр. 2020
Для меня изменение batch_size или какое-либо из заданных решений не помогло. Но оказалось, что в моем .cfg файле у меня были неправильные значения классов и фильтров в одном слое. Так что, если ничего не помогает, дважды проверьте свой .cfg.
 ulaszewskim
1 мая 2020
ulaszewskim
1 мая 2020
Открыть Терминал
Первый тип
nvidia-smi
затем выберите PID, соответствующий пути python или anaconda, и напишите
sudo kill -9 PID
 krypticmouse
4 мая 2020
krypticmouse
4 мая 2020
У меня уже давно есть эта ошибка. Для меня оказывается, что я продолжаю хранить переменную python (то есть тензор факела), которая ссылается на результат модели, и поэтому ее нельзя безопасно выпустить, поскольку код все еще может получить к ней доступ.
Мой код выглядит примерно так:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
Исправление состояло в том, чтобы передать p в список. Итак, код должен выглядеть так:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
Это гарантирует, что predictions хранит значения в основной памяти, а не в тензоре в графическом процессоре.
 abdelrahmanhosny
8 мая 2020
abdelrahmanhosny
8 мая 2020
У меня эта ошибка с использованием модуля fastai.vision, который полагается на pytorch. Я использую CUDA 10.1
 jkomyno
16 мая 2020
jkomyno
16 мая 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
уменьшите per_gpu_train_batch_size с 16 до 8, это решило мою проблему.
 autodataming
3 июн. 2020
autodataming
3 июн. 2020
Если вы обновитесь до последней версии PyTorch, у вас может быть меньше таких ошибок.
правда , почему ты так говоришь
 XinyingZheng
9 июн. 2020
XinyingZheng
9 июн. 2020
Главный вопрос этого выпуска остается открытым. Я получаю то же странное сообщение CUDA о нехватке памяти. Он попытался выделить 2,26 ГиБ в 4,08 ГиБ бесплатно. Вроде бы памяти достаточно, но ее не удается выделить.
Информация о проекте: обучение resnet 10 через набор данных activitynet с размером пакета 4, он терпит неудачу в финале первой эпохи.
EDITED: некоторые мнения: если я очищаю свою оперативную память и сохраняю только работающий код python, ошибка не возникает. Возможно, в графическом процессоре достаточно памяти, но оперативная память не может обрабатывать все остальные этапы обработки.
Информация о компьютере: Dell G5 - i7 9th - GTX 1660Ti 6 ГБ - 16 ГБ ОЗУ
EDITED2: я использовал "_MultiProcessingDataLoaderIter" с 4 рабочими, и он вызывает сообщение о нехватке памяти в прямом вызове. Если я уменьшу количество рабочих до 1, это не вызовет никаких ошибок. С 1 рабочим объемом оперативной памяти остается 11/16 ГБ, с 4 - повышается до 14,5 / 16 ГБ. Фактически, имея всего 1 работника, я могу увеличить размер пакета до 32, увеличив объем памяти графического процессора до 3,5 ГБ / 6 ГБ.
RuntimeError: CUDA не хватает памяти. Пытался выделить 2,26 ГиБ (GPU 0; 6,00 ГиБ общая емкость; 209,63 МиБ уже выделено; 4,08 ГиБ свободно; 246,00 МиБ зарезервировано всего PyTorch)
Полное сообщение об ошибке
Отслеживание (последний вызов последний):
Файл "main.py", строка 450, в
если опт. распределено:
Файл main.py, строка 409, в main_worker
opt.device, current_lr, train_logger,
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ training.py", строка 37, в train_epoch
выходы = модель (входы)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", строка 532, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nnparallel \ data_parallel.py", строка 150, вперед
вернуть self.module ( входы [0], * kwargs [0])
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", строка 532, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py", строка 205, впереди
x = self.layer3 (x)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", строка 532, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ container.py", строка 100, вперед
вход = модуль (вход)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", строка 532, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py", строка 51, впереди
out = self.conv2 (выход)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", строка 532, в __call__
результат = self.forward ( ввод, * kwargs)
Файл "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ conv.py", строка 480, вперед
self.padding, self.dilation, self.groups)
RuntimeError: CUDA не хватает памяти. Пытался выделить 2,26 ГиБ (GPU 0; 6,00 ГиБ общая емкость; 209,63 МиБ уже выделено; 4,08 ГиБ свободно; 246,00 МиБ зарезервировано
всего PyTorch)
 guilhermesurek
12 июн. 2020
guilhermesurek
12 июн. 2020
маленький размер партии, это работает
 cuge1995
15 июн. 2020
cuge1995
15 июн. 2020
У меня уже давно есть эта ошибка. Для меня оказывается, что я продолжаю хранить переменную python (то есть тензор факела), которая ссылается на результат модели, и поэтому ее нельзя безопасно выпустить, поскольку код все еще может получить к ней доступ.
Мой код выглядит примерно так:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Исправление состояло в том, чтобы передать
pв список. Итак, код должен выглядеть так:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Это гарантирует, что
predictionsхранит значения в основной памяти, а не в тензоре в графическом процессоре.
@abdelrahmanhosny Спасибо, что указали на это. Я столкнулся с той же проблемой в PyTorch 1.5.0 и не имел проблем с OOM во время обучения, однако во время вывода я также продолжал хранить переменную python (то есть тензор факела), которая ссылается на результат модели в памяти, что привело к тому, что GPU исчерпал память после определенного количества партий.
Однако в моем случае передача прогнозов в список не сработала, поскольку я генерирую изображения в своей сети, поэтому мне пришлось сделать следующее:
predictions.append(p.detach().cpu().numpy())
Это решило проблему!
 samkellerhals
19 июн. 2020
samkellerhals
19 июн. 2020
Есть какое-нибудь общее решение?
CUDA не хватает памяти. Пытался выделить 196,00 МБ (GPU 0; 2,00 ГБ общей емкости; 359,38 МБ уже выделено; 192,29 МБ свободно; 152,37 МБ кэшировано)
Есть какое-нибудь общее решение?
CUDA не хватает памяти. Пытался выделить 196,00 МБ (GPU 0; 2,00 ГБ общей емкости; 359,38 МБ уже выделено; 192,29 МБ свободно; 152,37 МБ кэшировано)
 manavkhadka0
24 июн. 2020
manavkhadka0
24 июн. 2020
У меня уже давно есть эта ошибка. Для меня оказывается, что я продолжаю хранить переменную python (то есть тензор факела), которая ссылается на результат модели, и поэтому ее нельзя безопасно выпустить, поскольку код все еще может получить к ней доступ.
Мой код выглядит примерно так:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Исправление состояло в том, чтобы передать
pв список. Итак, код должен выглядеть так:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Это гарантирует, что
predictionsхранит значения в основной памяти, а не в тензоре в графическом процессоре.@abdelrahmanhosny Спасибо, что указали на это. Я столкнулся с той же проблемой в PyTorch 1.5.0 и не имел проблем с OOM во время обучения, однако во время вывода я также продолжал хранить переменную python (то есть тензор факела), которая ссылается на результат модели в памяти, что привело к тому, что GPU исчерпал память после определенного количества партий.
Однако в моем случае передача прогнозов в список не сработала, поскольку я генерирую изображения в своей сети, поэтому мне пришлось сделать следующее:
predictions.append(p.detach().cpu().numpy())Это решило проблему!
У меня такая же проблема в модели ParrallelWaveGAN, и я использовал решения из # 16417, но у меня они не работают.
y = self.model_gan (* x) .view (-1) .detach (). cpu (). numpy ()
gc.collect ()
torch.cuda.empty_cache ()
 tuong-olli
25 июн. 2020
tuong-olli
25 июн. 2020
Была такая же проблема во время тренировки.
Сбор мусора и очистка памяти cuda после каждой эпохи решили проблему для меня.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
5 авг. 2020
IsakWesterlundBitville
5 авг. 2020
Что у меня просто сработало:
import gc # Your code with pytorch using GPU gc.collect()
Спасибо!! У меня возникли проблемы с запуском примера с кошками и собаками, и это сработало для меня.
 Michelpayan
5 авг. 2020
Michelpayan
5 авг. 2020
Была такая же проблема во время тренировки.
Сбор мусора и очистка памяти cuda после каждой эпохи решили проблему для меня.gc.collect() torch.cuda.empty_cache()
Мне то же
 AleksandrTulenkov
6 авг. 2020
AleksandrTulenkov
6 авг. 2020
уменьшите размер партии и увеличьте эпохи. вот как я это решил.
 oyekamal
18 сент. 2020
oyekamal
18 сент. 2020
@areebsyed Проверьте оперативную память, у меня была эта проблема при параллельной установке множества рабочих.
guilhermesurek
29 сент. 2020
Я также получаю ту же ошибку при точной настройке предварительно обученного bert2bert EncoderDecoderModel в pytorch в Colab, даже не завершив ни одной эпохи.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
6 окт. 2020
Aakash12980
6 окт. 2020
@ Aakash12980 вы пробовали уменьшить размер партии? Также входные изображения, которые вы хотите обучить, могут попытаться изменить их размер.
 areebsyed
6 окт. 2020
areebsyed
6 окт. 2020
@areebsyed Да, я уменьшил размер партии до 4, и это сработало.
Aakash12980
6 окт. 2020
тем же
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
7 окт. 2020
monajalal
7 окт. 2020
тем же
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal попробуйте уменьшить размер пакета или размер входного размера.
Aakash12980
7 окт. 2020
Итак, каково разрешение в примерах, подобных приведенным ниже (т.е. много _ свободной_ памяти и попытка выделить очень мало - что отличается от _ некоторых_ примеров в этом потоке, когда на самом деле мало свободной памяти и все в порядке)?
RuntimeError: CUDA не хватает памяти. Пытался выделить _ 1,33 ГиБ _ (GPU 1; 31,72 ГиБ общая емкость; 5,68 ГиБ уже выделено; _ 24,94 ГиБ свободно _; 5,96 МиБ кэшировано)
Я не понимаю, почему проблема перешла в статус 'Closed', поскольку это все еще происходит на последней версии pytorch (1.2) и современном графическом процессоре NVIDIA (V-100).
Спасибо!
Да, я чувствую, что большинство людей не понимают, что проблема не просто в OOM, а в том, что существует OOM, в то время как ошибка говорит, что достаточно свободного места. Я тоже сталкиваюсь с этой проблемой в Windows, вы нашли какое-либо решение?
 YoadTew
6 нояб. 2020
YoadTew
6 нояб. 2020
Смежные вопросы
 mishraswapnil
·
3Комментарии
mishraswapnil
·
3Комментарии
 soumith
·
3Комментарии
soumith
·
3Комментарии
soumith
·
3Комментарии
soumith
·
3Комментарии
 rajarshd
·
3Комментарии
rajarshd
·
3Комментарии
 dablyo
·
3Комментарии
dablyo
·
3Комментарии
Самый полезный комментарий
Это связано с тем, что мини-пакет данных не помещается в память графического процессора. Просто уменьшите размер партии. Когда я установил размер пакета = 256 для набора данных cifar10, я получил ту же ошибку; Потом ставлю размер партии = 128, решается.