Pytorch: RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 12,50 MiB (GPU 0; 10,92 GiB total kapasitas; 8,57 MiB sudah dialokasikan; 9,28 GiB gratis; 4,68 MiB di-cache)
CUDA Out of Memory error tetapi memori CUDA hampir kosong
Saat ini saya sedang melatih model ringan pada jumlah data tekstual yang sangat besar (sekitar 70GiB teks).
Untuk itu saya menggunakan mesin pada sebuah cluster ( 'grele' dari jaringan cluster grid5000 ).
Saya mendapatkan setelah 3 jam melatih pesan kesalahan CUDA Out of Memory yang sangat aneh ini:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
Menurut pesan, saya memiliki ruang yang diperlukan tetapi tidak mengalokasikan memori.
Tahu apa yang mungkin menyebabkan ini?
Sebagai informasi, prapemrosesan saya bergantung pada torch.multiprocessing.Queue dan iterator di atas baris data sumber saya untuk melakukan praproses data dengan cepat.
Pelacakan tumpukan penuh
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
Semua 91 komentar
Saya memiliki kesalahan runtime yang sama:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
pada 27 Jan 2019
OmarBazaraa
pada 27 Jan 2019
@EMarquer @OmarBazaraa Bisakah Anda memberikan contoh repro minimal yang dapat kami jalankan?
 yf225
pada 28 Jan 2019
yf225
pada 28 Jan 2019
Saya tidak dapat mereproduksi masalah lagi, jadi saya akan menutup masalah.
Masalahnya hilang ketika saya berhenti menyimpan data yang telah diproses sebelumnya di RAM.
@OmarBazaraa , saya rasa masalah Anda tidak sama dengan masalah saya, seperti:
- Saya mencoba mengalokasikan 12,50 MiB, dengan 9,28 GiB gratis
- Anda mencoba mengalokasikan 195,25 MiB, dengan 170,14 MiB gratis
Dari pengalaman saya sebelumnya dengan masalah ini, apakah Anda tidak mengosongkan memori CUDA atau Anda mencoba memasukkan terlalu banyak data ke CUDA.
Dengan tidak mengosongkan memori CUDA, maksud saya Anda berpotensi masih memiliki referensi ke tensor di CUDA yang tidak Anda gunakan lagi. Itu akan mencegah memori yang dialokasikan agar tidak dibebaskan dengan menghapus tensor.
EMarquer
pada 28 Jan 2019
Apakah ada solusi umum?
CUDA kehabisan memori. Mencoba mengalokasikan 196,00 MiB (GPU 0; total kapasitas 2,00 GiB; 359,38 MiB sudah dialokasikan; 192,29 MiB gratis; 152,37 MiB di-cache)
 aniketspurohit
pada 31 Jan 2019
aniketspurohit
pada 31 Jan 2019
@aniks23 kami sedang mengerjakan tambalan yang saya yakini akan memberikan pengalaman yang lebih baik dalam kasus ini. Pantau terus
 fmassa
pada 31 Jan 2019
fmassa
pada 31 Jan 2019
Apakah ada cara untuk mengetahui seberapa besar model atau jaringan yang dapat ditangani oleh sistem saya?
tanpa mengalami masalah ini?
Pada Jumat, 1 Februari 2019 pukul 3:55 Francisco Massa [email protected]
menulis:
@aniks23 https://github.com/aniks23 kami sedang mengerjakan tambalan yang saya
percaya akan memberikan pengalaman yang lebih baik dalam hal ini. Pantau terus—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
pada 1 Feb 2019
Saya juga mendapat pesan ini:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Itu terjadi ketika saya mencoba menjalankan Fast.ai Lesson1 Pets https://course.fast.ai/ (sel 31)
 adrianovieira
pada 12 Mar 2019
adrianovieira
pada 12 Mar 2019
Saya juga mengalami kesalahan yang sama. Model saya bekerja sebelumnya dengan pengaturan yang tepat, tetapi sekarang memberikan kesalahan ini setelah saya memodifikasi beberapa kode yang tampaknya tidak terkait.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
pada 14 Mar 2019
treble-maker123
pada 14 Mar 2019
Saya tidak tahu apakah skenario saya terkait dengan masalah aslinya, tetapi saya menyelesaikan masalah saya (kesalahan OOM dalam pesan sebelumnya hilang) dengan memecah lapisan nn.Sequential dalam model saya, misalnya
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
ke
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
Model saya memiliki lebih banyak dari ini (5 lebih tepatnya). Apakah saya menggunakan nn.Sequential kan? Atau ini bug? @yf225 @fmassa
treble-maker123
pada 14 Mar 2019
Saya juga mendapatkan kesalahan serupa:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@treble-maker123 , apakah Anda dapat membuktikan secara meyakinkan bahwa nn.Sequential adalah masalahnya?
 yasheshgaur
pada 17 Mar 2019
yasheshgaur
pada 17 Mar 2019
Saya mengalami masalah serupa. Saya menggunakan pemuat data pytorch. SaysI seharusnya memiliki lebih dari 5 Gb gratis tetapi memberikan 0 byte gratis.
RuntimeError Traceback (panggilan terakhir terakhir)
22
23 data, input = status_input
---> 24 data, input = Variabel(data).float().to(perangkat), Variabel(input).float().to(perangkat)
25 cetak(data.perangkat)
26 enc_out = pembuat enkode(data)
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 11.00 MiB (GPU 0; 6.00 GiB total kapasitas; 448.58 MiB sudah dialokasikan; 0 byte gratis; 942.00 KiB di-cache)
 ahsteven
pada 3 Apr 2019
ahsteven
pada 3 Apr 2019
Hai, saya juga mendapatkan kesalahan ini.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
pada 17 Apr 2019
AlbertZhangHIT
pada 17 Apr 2019
Sayangnya, saya juga menemui masalah yang sama.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
Saya telah melatih model saya di sekelompok server dan kesalahan tak terduga terjadi pada salah satu server saya. Juga kesalahan kabel seperti itu hanya terjadi di salah satu strategi pelatihan saya. Dan satu-satunya perbedaan adalah saya memodifikasi kode selama augmentasi data , dan membuat praproses data lebih rumit daripada yang lain. Tapi saya tidak yakin bagaimana menyelesaikan masalah ini.
 qingyu-wang
pada 25 Apr 2019
qingyu-wang
pada 25 Apr 2019
Saya juga mengalami masalah ini. Bagaimana mengatasinya??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
pada 10 Mei 2019
nabil2i
pada 10 Mei 2019
Masalah yang sama di sini RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
pada 16 Mei 2019
williamluke4
pada 16 Mei 2019
@fmassa Apakah Anda punya info lebih lanjut tentang ini?
williamluke4
pada 18 Mei 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
Masalah yang sama dengan saya
Sayang, apakah Anda mendapatkan solusinya?
(basis) F:\Suresh\st-gcn>python main1.py recognition -c config/st_gcn/ntu-xsub/train.yaml --device 0 --work_dir ./work_dir
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117: UserWarning:
Ditemukan GPU0 TITAN Xp yang memiliki kemampuan cuda 1.1.
PyTorch tidak lagi mendukung GPU ini karena sudah terlalu tua.
warnings.warn(old_gpu_warn % (d, nama, jurusan, kemampuan[1]))
[05.22.19|12:02:41] Parameter:
{'base_lr': 0.1, 'ignore_weights': [], 'model': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0,0001, 'work_dir': './work_dir', 'save_interval ': 10, 'model_args': {'in_channels': 3, 'dropout': 0.5, 'num_class': 60, 'edge_importance_weighting': Benar, 'graph_args': {'strategy': 'spatial', 'layout': 'ntu-rgb+d'}}, 'debug': Salah, 'pavi_log': Salah, 'save_result': Salah, 'config': 'config/st_gcn/ntu-xsub/train.yaml', 'optimizer': 'SGD', 'bobot': Tidak ada, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'step': [10, 50], 'use_gpu ': Benar, 'fase': 'train', 'print_log': Benar, 'log_interval': 100, 'feeder': 'feeder.feeder.Feeder', 'start_epoch': 0, 'nesterov': Benar, 'device ': [0], 'save_log': Benar, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU- RGB-D/xsub/val_label.pkl'}, 'train_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/train_data.npy', 'debug': Salah, 'label_path': ' ./data/NTU-RGB-D/xsub/train_l abel.pkl'}, 'num_worker': 4}
[05.22.19|12:02:41] Periode pelatihan: 0
Traceback (panggilan terakhir terakhir):
File "main1.py", baris 31, di
p.mulai()
File "F:\Suresh\st-gcn\processor\processor.py", baris 113, di awal
mandiri.kereta()
File "F:\Suresh\st-gcn\processor\recognition.py", baris 91, di kereta
keluaran = self.model(data)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", baris 489, di __call__
hasil = self.forward( input, * kwargs)
File "F:\Suresh\st-gcn\net\st_gcn.py", baris 82, di depan
x, _ = gcn(x, self.A * kepentingan)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", baris 489, di __call__
hasil = self.forward( input, * kwargs)
File "F:\Suresh\st-gcn\net\st_gcn.py", baris 194, di depan
x, A = diri.gcn(x, A)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", baris 489, di __call__
hasil = self.forward( input, * kwargs)
File "F:\Suresh\st-gcn\net\utils\tgcn.py", baris 60, di depan
x = self.conv(x)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", baris 489, di __call__
hasil = self.forward( input, * kwargs)
File "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py", baris 320, di depan
self.padding, self.dilatasi, self.groups)
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 1,37 GiB (GPU 0; 12,00 GiB total kapasitas; 8,28 GiB sudah dialokasikan; 652,75 MiB gratis; 664,38 MiB di-cache)
 Sureshthommandru
pada 22 Mei 2019
Sureshthommandru
pada 22 Mei 2019
Itu karena data mini-batch tidak muat ke memori GPU. Hanya mengurangi ukuran batch. Ketika saya mengatur ukuran batch = 256 untuk dataset cifar10 saya mendapatkan kesalahan yang sama; Kemudian saya mengatur ukuran batch = 128, itu terpecahkan.
 balcilar
pada 1 Jun 2019
balcilar
pada 1 Jun 2019
Ya @balcilar benar, saya mengurangi ukuran batch dan sekarang berfungsi
 EKELE-NNOROM
pada 4 Jun 2019
EKELE-NNOROM
pada 4 Jun 2019
Saya memiliki masalah serupa:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
Saya menggunakan 8 V100 untuk melatih model. Bagian yang membingungkan adalah masih ada cache 3,03GB dan tidak dapat dialokasikan untuk 11,88MB.
 magic282
pada 10 Jun 2019
magic282
pada 10 Jun 2019
Apakah Anda mengubah ukuran batch. Kurangi ukuran batch hingga setengahnya. Ucapkan batch
size adalah 16 untuk diterapkan, coba gunakan ukuran batch 8 dan lihat apakah itu berfungsi.
Menikmati
Pada Senin, 10 Juni 2019 pukul 02:10 magic282 [email protected] menulis:
Saya memiliki masalah serupa:
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 11,88 MiB (GPU 4; 15,75 GiB total kapasitas; 10,50 GiB sudah dialokasikan; 1,88 MiB gratis; 3,03 GiB di-cache)
Saya menggunakan 8 V100 untuk melatih model. Bagian yang membingungkan adalah ada
masih 3,03GB di-cache dan tidak dapat dialokasikan untuk 11,88MB.—
Anda menerima ini karena Anda berkomentar.
Balas email ini secara langsung, lihat di GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBQZ2DJORK5WSQZ2DXJORK5WQZJ63LNMVXH
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
pada 10 Jun 2019
Saya mencoba mengurangi ukuran batch dan berhasil. Bagian yang membingungkan adalah pesan kesalahan bahwa memori yang di-cache lebih besar dari memori yang akan dialokasikan.
magic282
pada 11 Jun 2019
Saya mendapatkan masalah yang sama pada model yang sudah terlatih, ketika saya menggunakan predict . Jadi mengurangi ukuran batch tidak akan berhasil.
 pvk444
pada 30 Jun 2019
pvk444
pada 30 Jun 2019
Jika Anda memperbarui ke versi terbaru PyTorch, Anda mungkin memiliki lebih sedikit kesalahan seperti itu
fmassa
pada 30 Jun 2019
Bolehkah saya bertanya mengapa angka-angka dalam kesalahan tidak bertambah?!
Saya (seperti Anda semua) mendapatkan:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
Bagi saya itu berarti yang berikut ini kira-kira benar:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
Tapi tidak. Apa yang saya salah?
 AzimAhmadzadeh
pada 3 Jul 2019
AzimAhmadzadeh
pada 3 Jul 2019
Saya juga punya masalah ketika saya melatih U-net, cache cukup, tetapi masih crash
 tongpinmo
pada 10 Jul 2019
tongpinmo
pada 10 Jul 2019
Saya mempunyai kesalahan yang sama...
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 312,00 MiB (GPU 0; 10,91 GiB total kapasitas; 1,07 GiB sudah dialokasikan; 109,62 MiB gratis; 15,21 MiB di-cache)
 MSKazemi
pada 10 Jul 2019
MSKazemi
pada 10 Jul 2019
coba kurangi ukuran (ukuran apa pun yang tidak akan mengubah hasilnya) akan berfungsi.
 giangnguyen2412
pada 11 Jul 2019
giangnguyen2412
pada 11 Jul 2019
coba kurangi ukuran (ukuran apa pun yang tidak akan mengubah hasilnya) akan berfungsi.
Halo, saya mengubah batch_size menjadi 1, tetapi tidak berhasil!
 BCWang93
pada 14 Jul 2019
BCWang93
pada 14 Jul 2019
Mungkin Anda harus mengubah ukuran lain.
Vao 21:50, CN, 14 TH7 2019 Bcw93 [email protected] DJA Viet:
coba kurangi ukuran (ukuran apa pun yang tidak akan mengubah hasilnya) akan berfungsi.
Halo, saya mengubah batch_size menjadi 1, tetapi tidak berhasil!
—
Anda menerima ini karena Anda berkomentar.
Balas email ini secara langsung, lihat di GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMWZW2000DORP-5WZWZW63LNMVXHJKT37issue
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
pada 15 Jul 2019
Mendapatkan kesalahan ini:
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 2,00 MiB (GPU 0; 7,94 GiB total kapasitas; 7,33 GiB sudah dialokasikan; 1,12 MiB gratis; 40,48 MiB di-cache)
nvidia-smi
Kamis 22 Agustus 21:05:52 2019
+------------------------------------------------- ----------------------------+
| NVIDIA-SMI 430.40 Versi Driver: 430.40 Versi CUDA: 10.1 |
|----------------------------+------------------ -----+----------------------+
| Nama GPU Kegigihan-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Penggunaan/Cap | Penggunaan Memori | GPU-Util Compute M. |
|==================================================== =====+========================|
| 0 Quadro M4000 Mati | 00000000:09:00.0 Aktif | T/A |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% Default |
+-------------------------------+----------------- -----+----------------------+
| 1 GeForce GTX 105... Mati | 00000000:41:00.0 Aktif | T/A |
| 29% 33C P8 T/A / 75W | 262MiB / 4032MiB | 0% Bawaan |
+-------------------------------+----------------- -----+----------------------+
+------------------------------------------------- ----------------------------+
| Proses: Memori GPU |
| Jenis PID GPU Nama proses Penggunaan |
|================================================== ==============================|
| 0 1909 G /usr/lib/xorg/Xorg 50MiB |
| 1 1909 G /usr/lib/xorg/Xorg 128MiB |
| 1 5236 G ...quest-channel-token=9884100064965360199 130MiB |
+-------------------------------------------------- ----------------------------+
OS: Ubuntu 18.04 bionik
Kernel: x86_64 Linux 4.15.0-58-generik
Waktu beroperasi: 29m
Paket: 2002
Shell: bash 4.4.20
Resolusi: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
Tema GTK: Lubuntu-default [GTK2]
Tema Ikon: Lubuntu
Font: Ubuntu 11
CPU: AMD Ryzen Threadripper 2970WX 24-Core @ 48x 3GHz [61,8°C]
GPU: Quadro M4000, GeForce GTX 1050 Ti
RAM: 3194MiB / 64345MiB
 danindiana
pada 23 Agu 2019
danindiana
pada 23 Agu 2019
Apakah ini tetap? Saya telah mengurangi ukuran dan ukuran batch keduanya menjadi 1. Saya tidak melihat solusi lain di sini, tetapi tiket ini ditutup. Saya mengalami masalah yang sama dengan Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
pada 6 Sep 2019
hughkf
pada 6 Sep 2019
@hughkf Di mana dalam kode Anda mengubah batch_size?
 aidoshacks
pada 6 Sep 2019
aidoshacks
pada 6 Sep 2019
@aidoshacks , Itu tergantung pada kode Anda. Tapi ini salah satu contohnya. Ini adalah salah satu notebook yang andal menyebabkan masalah ini pada mesin saya: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. Saya mengubah baris berikut,
bs,size = 8,src_size//2 ke bs,size = 1,1 tapi saya masih mendapatkan ini dari masalah memori.
hughkf
pada 6 Sep 2019
Bagi saya mengubah batch_size dari 128 menjadi 64 berhasil tetapi itu sepertinya bukan solusi yang diungkapkan untuk saya, atau apakah saya melewatkan sesuatu?
 shalgi
pada 19 Sep 2019
shalgi
pada 19 Sep 2019
Apakah masalah ini sudah terpecahkan? Saya juga mendapat masalah yang sama. Saya tidak mengubah apa pun dari kode saya, tetapi setelah dijalankan berkali-kali, kesalahan ini terjadi:
"RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 40,00 MiB (GPU 0; 15,77 GiB total kapasitas; 13,97 GiB sudah dialokasikan; 256,00 KiB gratis; 824,57 MiB di-cache)"
 mengxiangming
pada 26 Sep 2019
mengxiangming
pada 26 Sep 2019
Masih mengalami masalah ini, alangkah baiknya jika statusnya diubah menjadi unresolved.
EDIT:
Tidak ada hubungannya dengan ukuran batch mengingat saya mendapatkannya dengan ukuran batch 1. Restart kernel memperbaikinya untuk saya dan itu tidak terjadi sejak itu.
 just-in-kees
pada 29 Sep 2019
just-in-kees
pada 29 Sep 2019
Jadi apa resolusi pada contoh seperti di bawah ini (yaitu banyak memori bebas dan mencoba mengalokasikan sangat sedikit - yang berbeda dari beberapa contoh di utas ini ketika sebenarnya ada sedikit jumlah mem bebas dan tidak ada yang salah)?
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 1,33 GiB (GPU 1; 31,72 GiB total kapasitas; 5,68 GiB sudah dialokasikan; 24,94 GiB gratis ; 5,96 MiB di-cache)
Saya tidak mengerti mengapa masalah beralih ke status 'Tertutup', karena masih terjadi pada pytorch ver (1.2) terbaru dan GPU NVIDIA modern (V-100)
Terima kasih!
 yuribd
pada 3 Okt 2019
yuribd
pada 3 Okt 2019
Sebagian besar waktu Anda mendapatkan pesan kesalahan khusus ini dari paket fastai adalah karena Anda menggunakan GPU yang sangat kecil. Saya memperbaiki masalah ini dengan me-restart kernel saya dan dengan menggunakan ukuran batch yang lebih kecil untuk jalur yang Anda berikan.
 AurioPinto
pada 5 Okt 2019
AurioPinto
pada 5 Okt 2019
Masalah yang sama disini. Ketika saya menggunakan pytorch0.4.1, ukuran batch=4, tidak apa-apa. Tetapi ketika saya mengubah ke pytorch1.3 dan bahkan mengatur ukuran batch ke 1, saya memiliki masalah oom.
 Sarah20187
pada 21 Okt 2019
Sarah20187
pada 21 Okt 2019
menyelesaikannya dengan memperbarui pytorch saya ke yang terbaru ... conda update pytorch
 kafura0
pada 21 Okt 2019
kafura0
pada 21 Okt 2019
Itu karena data mini-batch tidak muat ke memori GPU. Hanya mengurangi ukuran batch. Ketika saya mengatur ukuran batch = 256 untuk dataset cifar10 saya mendapatkan kesalahan yang sama; Kemudian saya mengatur ukuran batch = 128, itu terpecahkan.
terima kasih, saya mengatasi kesalahan melalui cara ini.
 zhangzibao
pada 25 Okt 2019
zhangzibao
pada 25 Okt 2019
Saya menurunkan batch_size menjadi 8, itu berfungsi dengan baik. Idenya adalah memiliki batch_size kecil
 Asutosh11
pada 30 Okt 2019
Asutosh11
pada 30 Okt 2019
Saya pikir itu tergantung pada ukuran input total yang dihadapi lapisan tertentu. Misalnya, jika sekumpulan 256 (32x32) gambar melewati 128 filter dalam satu lapisan, ukuran input totalnya adalah 256x32x32x128 = 2^25. Jumlah ini harus di bawah beberapa ambang batas, yang saya kira khusus untuk mesin. Untuk AWS p3.2xlarge misalnya, itu adalah 2^26. Jadi, jika Anda mendapatkan kesalahan memori CuDA, coba kurangi ukuran batch atau jumlah filter atau lakukan lebih banyak downsampling seperti stride atau pooling layers
 souryadey
pada 1 Nov 2019
souryadey
pada 1 Nov 2019
Memiliki masalah yang sama:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
Dengan versi terbaru pytorch (1.3) dan cuda (10.1). Nvidia-smi juga menunjukkan GPU setengah kosong, jadi jumlah memori kosong dalam pesan kesalahan sudah benar. Belum dapat mereproduksinya dengan kode sederhana
 ArgentumWalker
pada 3 Nov 2019
ArgentumWalker
pada 3 Nov 2019
Menyetel ulang kernel juga berhasil untuk saya! Tidak berfungsi bahkan dengan ukuran batch = 1 sampai saya melakukan itu
 kennethjmyers
pada 7 Nov 2019
kennethjmyers
pada 7 Nov 2019
Kawan, saya menyelesaikan masalah saya dengan mengurangi ukuran batch saya hingga setengahnya.
 faizao
pada 19 Nov 2019
faizao
pada 19 Nov 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Diperbaiki setelah reboot
 SomeUserName1
pada 22 Nov 2019
SomeUserName1
pada 22 Nov 2019
mengubah batch_size 64(rtx2080 ti) menjadi 32(rtx 2060), masalah terpecahkan. tetapi saya ingin tahu cara lain untuk menyelesaikan masalah seperti ini.
 sailfish009
pada 3 Des 2019
sailfish009
pada 3 Des 2019
Ini terjadi pada saya ketika saya melakukan prediksi !
Saya mengubah ukuran batch dari 1024 menjadi 8 dan masih mendapatkan kesalahan ketika 82% dari set tes dievaluasi.
Ketika saya menambahkan with torch.no_grad() masalahnya TERSELESAIKAN.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
pada 17 Des 2019
smasoudn
pada 17 Des 2019
Saya memecahkan masalah
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
ke
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
pada 27 Des 2019
zhonghaochen
pada 27 Des 2019
Saya memiliki masalah yang sama dan saya memeriksa penggunaan GPU di mesin saya. Ada banyak yang sudah digunakan dan jumlah memori yang tersisa sangat sedikit. Saya membunuh notebook jupyter saya dan memulai kembali. memori menjadi bebas dan hal-hal mulai bekerja. Anda dapat menggunakan di bawah ini:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
pada 27 Des 2019
prabhatsharma
pada 27 Des 2019
Saya juga mendapat pesan ini:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Itu terjadi ketika saya mencoba menjalankan Fast.ai Lesson1 Pets https://course.fast.ai/ (sel 31)
Cobalah untuk mengurangi ukuran batch (bs) dari data pelatihan Anda.
Lihat apa yang berhasil untuk Anda.
 rishi0904
pada 27 Des 2019
rishi0904
pada 27 Des 2019
Saya menemukan masalah ini dapat dipecahkan tanpa menyesuaikan ukuran batch Anda.
Buka terminal dan prompt python
import torch
torch.cuda.empty_cache()
Keluar dari juru bahasa Python, jalankan kembali perintah PyTorch asli Anda dan itu (semoga) tidak menghasilkan kesalahan memori CUDA.
 cpoptic
pada 3 Jan 2020
cpoptic
pada 3 Jan 2020
Saya menemukan bahwa ketika komputer saya menggunakan terlalu banyak RAM CPU, masalah ini biasanya muncul. Jadi ketika kita menginginkan ukuran batch yang lebih besar, kita bisa mencoba mengurangi penggunaan RAM CPU.
 dhKwang
pada 13 Jan 2020
dhKwang
pada 13 Jan 2020
Punya masalah serupa.
Mengurangi ukuran batch dan memulai ulang kernel membantu menyelesaikan masalah.
 kumarnikhil936
pada 19 Jan 2020
kumarnikhil936
pada 19 Jan 2020
Dalam kasus saya, mengganti pengoptimal Adam dengan pengoptimal SGD memecahkan masalah yang sama.
 tranvanluan2
pada 23 Jan 2020
tranvanluan2
pada 23 Jan 2020
Nah, dalam kasus saya, digunakan with torch.no_grad(): (train model) , output.to("cpu") dan torch.cuda.empty_cache() dan masalah ini terpecahkan.
 PlanNoa
pada 30 Jan 2020
PlanNoa
pada 30 Jan 2020
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 54,00 MiB (GPU 0; 3,95 GiB total kapasitas; 2,65 GiB sudah dialokasikan; 39,00 MiB gratis; 87,29 MiB di-cache)
saya menemukan solusinya dan saya mengurangi nilai batch_size.
 sagrawal06
pada 30 Jan 2020
sagrawal06
pada 30 Jan 2020
Saya melatih YOLOv3 dengan bobot Darknet53 pada kumpulan data khusus. GPU saya adalah NVIDIA RTX 2080 dan saya menghadapi masalah yang sama. Mengubah ukuran batch menyelesaikannya.
 wilderrodrigues
pada 2 Feb 2020
wilderrodrigues
pada 2 Feb 2020
Saya mendapatkan kesalahan ini selama waktu inferensi .... saya ru
CUDA kehabisan memori. Mencoba mengalokasikan 102,00 MiB (GPU 0; 15,78 GiB total kapasitas; 14,54 GiB sudah dialokasikan; 48,44 MiB gratis; 14,67 GiB dicadangkan total oleh PyTorch)
-------------------------------------------------- ----------------------------+
| NVIDIA-SMI 440.59 Versi Driver: 440.59 Versi CUDA: 10.2 |
|----------------------------+------------------ -----+----------------------+
| Nama GPU Kegigihan-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Penggunaan/Cap | Penggunaan Memori | GPU-Util Compute M. |
|==================================================== =====+========================|
| 0 Tesla V100-SXM2... Aktif | 00000000:00:1E.0 Mati | 0 |
| T/A 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% Bawaan |
+-------------------------------+----------------- -----+----------------------+
+-------------------------------------------------- ----------------------------+
| Proses: Memori GPU |
| Jenis PID GPU Nama proses Penggunaan |
|================================================== ==============================|
| 0 13978 C /.conda/envs/ /bin/python 16101MiB |
+-------------------------------------------------- ----------------------------+
 tvinith
pada 29 Feb 2020
tvinith
pada 29 Feb 2020
Itu karena data mini-batch tidak muat ke memori GPU. Hanya mengurangi ukuran batch. Ketika saya mengatur ukuran batch = 256 untuk dataset cifar10 saya mendapatkan kesalahan yang sama; Kemudian saya mengatur ukuran batch = 128, itu terpecahkan.
terima kasih, kamu benar
 Rxma1805
pada 2 Mar 2020
Rxma1805
pada 2 Mar 2020
Untuk kasus tertentu, di mana ada cukup memori GPU, tetapi kesalahan masih terjadi. Dalam kasus saya, saya MEMECAHkannya dengan mengurangi jumlah pekerja di dataloader.
 Yurasyk
pada 14 Mar 2020
Yurasyk
pada 14 Mar 2020
Latar belakang
py36, pytorch1.4, tf2.0, conda
menyempurnakan Roberta
Isu
Masalah yang sama dengan @EMarquer : pycharm menunjukkan bahwa saya masih memiliki cukup memori, namun mengalokasikan memori gagal, kehabisan memori.
Cara saya mencoba
- "batch_size = 1" gagal
- "torch.cuda.empty_cache()" gagal
- CUDA_VISIBLE_DEVICES="0" python Run.py gagal
- Karena saya tidak menggunakan jupyter, tidak perlu me-restart kernel
cara yang sukses
- nvidia-smi


- Sebenarnya apa yang ditunjukkan pycharm berbeda dengan apa yang ditunjukkan "nvidia-smi" (maaf saya tidak menyimpan gambar pycharm), sebenarnya tidak ada cukup memori .
- Proses 6123 dan 32644 berjalan di terminal sebelumnya.
- sudo bunuh -9 6123
- sudo kill -9 32644
 FernandoZhuang
pada 17 Mar 2020
FernandoZhuang
pada 17 Mar 2020
Apa yang berhasil untuk saya:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
pada 6 Apr 2020
MastafaF
pada 6 Apr 2020
Saya menemukan masalah ini dapat dipecahkan tanpa menyesuaikan ukuran batch Anda.
Buka terminal dan prompt python
import torch torch.cuda.empty_cache()Keluar dari juru bahasa Python, jalankan kembali perintah PyTorch asli Anda dan itu (semoga) tidak menghasilkan kesalahan memori CUDA.
Dalam kasus saya, itu memecahkan masalah saya.
 LiEAEX
pada 10 Apr 2020
LiEAEX
pada 10 Apr 2020
Pastikan Anda menggunakan GPU Anda di slot 0 dengan --device_ids 0
Saya tahu saya membantai terminologi tetapi itu berhasil. Saya kira itu mengasumsikan Anda ingin menggunakan CPU daripada GPU jika Anda tidak memilih id.
 aaron387
pada 12 Apr 2020
aaron387
pada 12 Apr 2020
Saya mendapatkan kesalahan yang sama:
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 4,84 GiB (GPU 0; 7,44 GiB total kapasitas; 5,22 GiB sudah dialokasikan; 1,75 GiB gratis; 18,51 MiB di-cache)
Ketika saya me-restart cluster atau mengubah ukuran batch, itu berfungsi. Tapi saya tidak suka solusi ini. Saya bahkan mencoba torch.cuda.empty_cache() , ini tidak berhasil untuk saya. Apakah ada cara lain yang efisien untuk menyelesaikan ini?
 Tann10
pada 13 Apr 2020
Tann10
pada 13 Apr 2020
Saya tidak tahu apakah skenario saya terkait dengan masalah aslinya, tetapi saya menyelesaikan masalah saya (kesalahan OOM dalam pesan sebelumnya hilang) dengan memecah lapisan nn.Sequential dalam model saya, misalnya
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)ke
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))Model saya memiliki lebih banyak dari ini (5 lebih tepatnya). Apakah saya menggunakan nn.Sequential kan? Atau ini bug? @yf225 @fmassa
Sepertinya saya juga memecahkan kesalahan serupa tetapi sebaliknya dengan Anda.
Saya mengubah semua
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)ke
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
pada 14 Apr 2020
xml94
pada 14 Apr 2020
Bagi saya mengubah batch_size atau solusi apa pun yang diberikan tidak membantu. Tetapi ternyata dalam file .cfg saya, saya memiliki nilai kelas dan filter yang salah dalam satu lapisan. Jadi jika tidak ada yang membantu, periksa kembali .cfg Anda.
 ulaszewskim
pada 1 Mei 2020
ulaszewskim
pada 1 Mei 2020
Buka Terminal
Tipe pertama
nvidia-smi
lalu pilih PID yang sesuai dengan jalur python atau anaconda dan tulis
sudo bunuh -9 PID
 krypticmouse
pada 4 Mei 2020
krypticmouse
pada 4 Mei 2020
Saya telah mengalami bug ini selama beberapa waktu. Bagi saya, ternyata saya tetap memegang variabel python (yaitu torch tensor) yang mereferensikan hasil model, sehingga tidak dapat dilepaskan dengan aman karena kode masih dapat mengaksesnya.
Kode saya terlihat seperti:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
Perbaikan untuk ini adalah mentransfer p ke daftar. Jadi, kodenya akan terlihat seperti:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
Ini memastikan bahwa predictions menyimpan nilai di memori utama, bukan tensor di GPU.
 abdelrahmanhosny
pada 8 Mei 2020
abdelrahmanhosny
pada 8 Mei 2020
Saya mengalami bug ini menggunakan modul fastai.vision, yang bergantung pada pytorch. Saya menggunakan CUDA 10.1
 jkomyno
pada 16 Mei 2020
jkomyno
pada 16 Mei 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
kurangi per_gpu_train_batch_size dari 16 menjadi 8, ini menyelesaikan masalah saya.
 autodataming
pada 3 Jun 2020
autodataming
pada 3 Jun 2020
Jika Anda memperbarui ke versi terbaru PyTorch, Anda mungkin memiliki lebih sedikit kesalahan seperti itu
benar-benar, mengapa kamu mengatakan itu?
 XinyingZheng
pada 9 Jun 2020
XinyingZheng
pada 9 Jun 2020
Pertanyaan utama dari masalah ini masih merupakan masalah terbuka. Saya mendapatkan CUDA aneh yang sama dari pesan memori. Ia mencoba mengalokasikan 2,26 GiB dalam 4,08 GiB gratis. Tampaknya ada cukup memori tetapi gagal untuk mengalokasikan.
Info proyek: melatih resnet 10 melalui dataset activitynet dengan ukuran batch 4, gagal di akhir zaman pertama.
DIEDIT: Beberapa persepsi: Jika saya membersihkan memori RAM saya dan hanya menjalankan kode python, kesalahan tidak akan muncul. Mungkin ada cukup memori di GPU, tetapi memori RAM tidak dapat menangani semua langkah pemrosesan lainnya.
Info komputer: Dell G5 - i7 9th - GTX 1660Ti 6GB - RAM 16 GB
EDITED2: Saya menggunakan "_MultiProcessingDataLoaderIter" dengan 4 pekerja dan itu menimbulkan pesan kehabisan memori dalam panggilan penerusan. Jika saya mengurangi jumlah pekerja menjadi 1, itu tidak menimbulkan kesalahan apa pun. Dengan 1 pekerja, penggunaan memori ram tetap 11/16GB, dengan 4 meningkat menjadi 14.5/16GB. Dan hanya dengan 1 pekerja, sebenarnya, saya dapat meningkatkan ukuran batch menjadi 32 meningkatkan memori GPU menjadi 3,5GB/6GB.
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 2,26 GiB (GPU 0; total kapasitas 6,00 GiB; 209,63 MiB sudah dialokasikan; 4,08 GiB gratis; total 246.00 MiB dipesan oleh PyTorch)
Seluruh pesan kesalahan
Traceback (panggilan terakhir terakhir):
File "main.py", baris 450, di
jika opt.distributed:
File "main.py", baris 409, di main_worker
opt.device, current_lr, train_logger,
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\training.py", baris 37, di train_epoch
keluaran = model(masukan)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", baris 532, di __call__
hasil = self.forward( input, * kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py", baris 150, di depan
kembalikan self.module( inputs[0], * kwargs[0])
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", baris 532, di __call__
hasil = self.forward( input, * kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", baris 205, di depan
x = self.layer3(x)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", baris 532, di __call__
hasil = self.forward( input, * kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py", baris 100, di depan
masukan = modul (masukan)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", baris 532, di __call__
hasil = self.forward( input, * kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", baris 51, di depan
keluar = self.conv2(keluar)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", baris 532, di __call__
hasil = self.forward( input, * kwargs)
File "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py", baris 480, di depan
self.padding, self.dilatasi, self.groups)
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan 2,26 GiB (GPU 0; total kapasitas 6,00 GiB; 209,63 MiB sudah dialokasikan; 4,08 GiB gratis; 246.00 MiB dipesan
secara total oleh PyTorch)
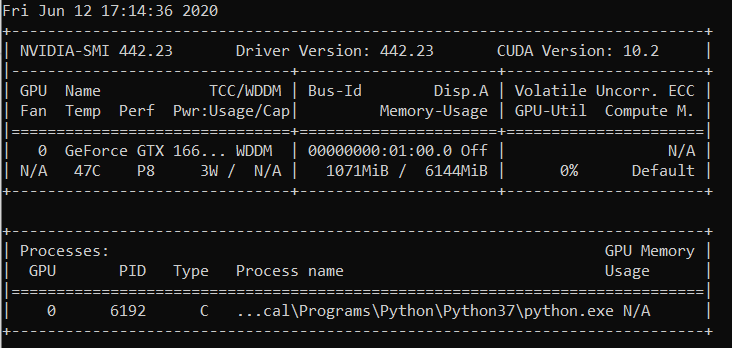
 guilhermesurek
pada 12 Jun 2020
guilhermesurek
pada 12 Jun 2020
kecil ukuran batch, itu berfungsi
 cuge1995
pada 15 Jun 2020
cuge1995
pada 15 Jun 2020
Saya telah mengalami bug ini selama beberapa waktu. Bagi saya, ternyata saya tetap memegang variabel python (yaitu torch tensor) yang mereferensikan hasil model, sehingga tidak dapat dilepaskan dengan aman karena kode masih dapat mengaksesnya.
Kode saya terlihat seperti:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Perbaikan untuk ini adalah mentransfer
pke daftar. Jadi, kodenya akan terlihat seperti:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Ini memastikan bahwa
predictionsmenyimpan nilai di memori utama, bukan tensor di GPU.
@abdelrahmanhosny Terima kasih telah menunjukkan ini. Saya menghadapi masalah yang sama persis di PyTorch 1.5.0, dan tidak memiliki masalah OOM selama pelatihan namun selama inferensi saya juga terus memegang variabel python (yaitu tensor obor) yang mereferensikan hasil model dalam memori yang mengakibatkan GPU kehabisan memori setelah sejumlah batch tertentu.
Namun dalam kasus saya, mentransfer prediksi ke daftar tidak berfungsi karena saya menghasilkan gambar dengan jaringan saya, oleh karena itu saya harus melakukan hal berikut:
predictions.append(p.detach().cpu().numpy())
Ini kemudian memecahkan masalah!
 samkellerhals
pada 19 Jun 2020
samkellerhals
pada 19 Jun 2020
Apakah ada solusi umum?
CUDA kehabisan memori. Mencoba mengalokasikan 196,00 MiB (GPU 0; total kapasitas 2,00 GiB; 359,38 MiB sudah dialokasikan; 192,29 MiB gratis; 152,37 MiB di-cache)
Apakah ada solusi umum?
CUDA kehabisan memori. Mencoba mengalokasikan 196,00 MiB (GPU 0; total kapasitas 2,00 GiB; 359,38 MiB sudah dialokasikan; 192,29 MiB gratis; 152,37 MiB di-cache)
 manavkhadka0
pada 24 Jun 2020
manavkhadka0
pada 24 Jun 2020
Saya telah mengalami bug ini selama beberapa waktu. Bagi saya, ternyata saya tetap memegang variabel python (yaitu torch tensor) yang mereferensikan hasil model, sehingga tidak dapat dilepaskan dengan aman karena kode masih dapat mengaksesnya.
Kode saya terlihat seperti:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)Perbaikan untuk ini adalah mentransfer
pke daftar. Jadi, kodenya akan terlihat seperti:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Ini memastikan bahwa
predictionsmenyimpan nilai di memori utama, bukan tensor di GPU.@abdelrahmanhosny Terima kasih telah menunjukkan ini. Saya menghadapi masalah yang sama persis di PyTorch 1.5.0, dan tidak memiliki masalah OOM selama pelatihan namun selama inferensi saya juga terus memegang variabel python (yaitu tensor obor) yang mereferensikan hasil model dalam memori yang mengakibatkan GPU kehabisan memori setelah sejumlah batch tertentu.
Namun dalam kasus saya, mentransfer prediksi ke daftar tidak berfungsi karena saya menghasilkan gambar dengan jaringan saya, oleh karena itu saya harus melakukan hal berikut:
predictions.append(p.detach().cpu().numpy())Ini kemudian memecahkan masalah!
Saya memiliki masalah yang sama dalam model ParrallelWaveGAN dan saya menggunakan solusi di #16417 tetapi tidak berhasil untuk saya
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
gc.koleksi()
obor.cuda.empty_cache()
 tuong-olli
pada 25 Jun 2020
tuong-olli
pada 25 Jun 2020
Punya masalah yang sama selama pelatihan.
Mengumpulkan sampah dan mengosongkan memori cuda setelah setiap zaman memecahkan masalah bagi saya.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
pada 5 Agu 2020
IsakWesterlundBitville
pada 5 Agu 2020
Apa yang berhasil untuk saya:
import gc # Your code with pytorch using GPU gc.collect()
Terima kasih!! Saya mengalami kesulitan menjalankan contoh Kucing dan anjing dan ini berhasil untuk saya.
 Michelpayan
pada 5 Agu 2020
Michelpayan
pada 5 Agu 2020
Punya masalah yang sama selama pelatihan.
Mengumpulkan sampah dan mengosongkan memori cuda setelah setiap zaman memecahkan masalah bagi saya.gc.collect() torch.cuda.empty_cache()
Sama untuk ku
 AleksandrTulenkov
pada 6 Agu 2020
AleksandrTulenkov
pada 6 Agu 2020
mengurangi ukuran batch dan meningkatkan epoch. begitulah cara saya menyelesaikannya.
 oyekamal
pada 18 Sep 2020
oyekamal
pada 18 Sep 2020
@areebsyed Periksa memori ram, saya mengalami masalah ini ketika mengatur banyak pekerja secara paralel.
guilhermesurek
pada 29 Sep 2020
Saya juga mendapatkan kesalahan yang sama saat menyempurnakan bert2bert EncoderDecoderModel yang telah dilatih sebelumnya di pytorch di Colab bahkan tanpa menyelesaikan satu zaman pun.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
pada 6 Okt 2020
Aakash12980
pada 6 Okt 2020
@Aakash12980 apakah Anda mencoba dan mengurangi ukuran batch? Juga gambar input yang ingin Anda latih mungkin coba ubah ukurannya
 areebsyed
pada 6 Okt 2020
areebsyed
pada 6 Okt 2020
@areebsyed Ya saya mengurangi ukuran batch menjadi 4 dan berhasil.
Aakash12980
pada 6 Okt 2020
sama
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
pada 7 Okt 2020
monajalal
pada 7 Okt 2020
sama
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal coba kurangi ukuran batch atau ukuran dimensi input.
Aakash12980
pada 7 Okt 2020
Jadi apa resolusi pada contoh seperti di bawah ini (yaitu banyak _free_ memori dan mencoba untuk mengalokasikan sangat sedikit - yang berbeda dari _some_ contoh di utas ini ketika sebenarnya ada sedikit jumlah mem bebas dan tidak ada yang salah)?
RuntimeError: CUDA kehabisan memori. Mencoba mengalokasikan _ 1,33 GiB _ (GPU 1; 31,72 GiB total kapasitas; 5,68 GiB sudah dialokasikan; _ 24,94 GiB gratis _; 5,96 MiB di-cache)
Saya tidak mengerti mengapa masalah beralih ke status 'Tertutup', karena masih terjadi pada pytorch ver (1.2) terbaru dan GPU NVIDIA modern (V-100)
Terima kasih!
Ya, saya merasa sebagian besar orang tidak menyadari bahwa masalahnya bukan hanya OOM, tetapi ada OOM sementara kesalahannya mengatakan ada cukup ruang kosong. Saya menghadapi masalah ini juga di windows, apakah Anda menemukan solusi?
 YoadTew
pada 6 Nov 2020
YoadTew
pada 6 Nov 2020
Masalah terkait
 keskarnitish
·
3Komentar
keskarnitish
·
3Komentar
 negrinho
·
3Komentar
negrinho
·
3Komentar
 NgPDat
·
3Komentar
NgPDat
·
3Komentar
 soumith
·
3Komentar
soumith
·
3Komentar
 rajarshd
·
3Komentar
rajarshd
·
3Komentar
Komentar yang paling membantu
Itu karena data mini-batch tidak muat ke memori GPU. Hanya mengurangi ukuran batch. Ketika saya mengatur ukuran batch = 256 untuk dataset cifar10 saya mendapatkan kesalahan yang sama; Kemudian saya mengatur ukuran batch = 128, itu terpecahkan.