Pytorch: RuntimeError: CUDA sin memoria. Intenté asignar 12,50 MiB (GPU 0; 10,92 GiB de capacidad total; 8,57 MiB ya asignados; 9,28 GiB libres; 4,68 MiB en caché)
Error de memoria insuficiente de CUDA, pero la memoria de CUDA está casi vacía
Actualmente estoy entrenando un modelo ligero con una gran cantidad de datos textuales (alrededor de 70GiB de texto).
Para eso, estoy usando una máquina en un clúster ( 'grele' de la red del clúster grid5000 ).
Recibo después de 3 horas de entrenamiento este muy extraño mensaje de error de memoria insuficiente de CUDA:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
Según el mensaje, tengo el espacio requerido pero no asigna la memoria.
¿Alguna idea de qué podría causar esto?
Para obtener información, mi preprocesamiento se basa en torch.multiprocessing.Queue y un iterador sobre las líneas de mis datos de origen para preprocesar los datos sobre la marcha.
Seguimiento de pila completo
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
Todos 91 comentarios
Tengo el mismo error de tiempo de ejecución:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
en 27 ene. 2019
OmarBazaraa
en 27 ene. 2019
@EMarquer @OmarBazaraa ¿Podrías dar un ejemplo de reproducción mínima que podamos ejecutar?
 yf225
en 28 ene. 2019
yf225
en 28 ene. 2019
Ya no puedo reproducir el problema, por lo que cerraré el problema.
El problema desapareció cuando dejé de almacenar los datos preprocesados en la RAM.
@OmarBazaraa , no creo que tu problema sea el mismo que el mío, ya que:
- Estoy intentando asignar 12,50 MiB, con 9,28 GiB libres
- está intentando asignar 195,25 MiB, con 170,14 MiB libres
Según mi experiencia anterior con este problema, o no libera la memoria CUDA o intenta poner demasiados datos en CUDA.
Al no liberar la memoria CUDA, me refiero a que potencialmente todavía tiene referencias a tensores en CUDA que ya no usa. Esos evitarían que se libere la memoria asignada eliminando los tensores.
EMarquer
en 28 ene. 2019
¿Existe alguna solución general?
CUDA sin memoria. Intenté asignar 196,00 MiB (GPU 0; 2,00 GiB de capacidad total; 359,38 MiB ya asignados; 192,29 MiB libres; 152,37 MiB en caché)
 aniketspurohit
en 31 ene. 2019
aniketspurohit
en 31 ene. 2019
@ aniks23 estamos trabajando en un parche que creo que dará una mejor experiencia en este caso. Manténganse al tanto
 fmassa
en 31 ene. 2019
fmassa
en 31 ene. 2019
¿Hay alguna forma de saber qué tamaño de modelo o red puede manejar mi sistema?
sin encontrarse con este problema?
El viernes 1 de febrero de 2019 a las 3:55 a.m. Francisco Massa [email protected]
escribió:
@ aniks23 https://github.com/aniks23 estamos trabajando en un parche que yo
Creo que dará una mejor experiencia en este caso. Manténganse al tanto-
Recibes esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
en 1 feb. 2019
También recibí este mensaje:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Sucedió cuando intentaba ejecutar la lección 1 de Fast.ai Pets https://course.fast.ai/ (celda 31)
 adrianovieira
en 12 mar. 2019
adrianovieira
en 12 mar. 2019
Yo también me encuentro con los mismos errores. Mi modelo estaba funcionando antes con la configuración exacta, pero ahora está dando este error después de que modifiqué un código aparentemente no relacionado.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
en 14 mar. 2019
treble-maker123
en 14 mar. 2019
No sé si mi escenario se puede relacionar con el problema original, pero resolví mi problema (el error OOM en el mensaje anterior desapareció) dividiendo las nn capas secuenciales en mi modelo, por ejemplo
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
para
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
Mi modelo tiene muchos más de estos (5 más para ser exactos). ¿Estoy usando nn secuencial, verdad? ¿O es esto un error? @ yf225 @fmassa
treble-maker123
en 14 mar. 2019
También recibo un error similar:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@ treble-maker123, ¿ha podido demostrar de manera concluyente que nn.Sequential es el problema?
 yasheshgaur
en 17 mar. 2019
yasheshgaur
en 17 mar. 2019
Tengo un problema similar. Estoy usando el cargador de datos pytorch. Dice que debería tener más de 5 Gb libres pero da 0 bytes libres.
RuntimeError Traceback (última llamada más reciente)
22
23 datos, entradas = estados_entradas
---> 24 datos, entradas = Variable (datos) .float (). A (dispositivo), Variable (entradas) .float (). A (dispositivo)
25 imprimir (dispositivo de datos)
26 enc_out = codificador (datos)
RuntimeError: CUDA sin memoria. Intenté asignar 11,00 MiB (GPU 0; 6,00 GiB de capacidad total; 448,58 MiB ya asignados; 0 bytes libres; 942,00 KiB en caché)
 ahsteven
en 3 abr. 2019
ahsteven
en 3 abr. 2019
Hola, también recibí este error.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
en 17 abr. 2019
AlbertZhangHIT
en 17 abr. 2019
Lamentablemente, también encontré el mismo problema.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
Entrené mi modelo en un grupo de servidores y el error le sucedió de manera impredecible a uno de mis servidores. Además, este error de cableado solo ocurre en una de mis estrategias de entrenamiento. Y la única diferencia es que modifico el código durante el aumento de datos y hago que el preproceso de datos sea más complicado que otros. Pero no estoy seguro de cómo resolver este problema.
 qingyu-wang
en 25 abr. 2019
qingyu-wang
en 25 abr. 2019
Yo tambien estoy teniendo este problema. ¿¿¿Cómo resolverlo??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
en 10 may. 2019
nabil2i
en 10 may. 2019
Mismo problema aquí RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
en 16 may. 2019
williamluke4
en 16 may. 2019
@fmassa ¿Tienes más información sobre esto?
williamluke4
en 18 may. 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
El mismo problema para mi
Querido, ¿obtuviste la solución?
(base) F: \ Suresh \ st-gcn> python reconocimiento main1.py -c config / st_gcn / ntu-xsub / train.yaml --device 0 --work_dir ./work_dir
C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ cuda__init __. Py: 117: UserWarning:
Se encontró GPU0 TITAN Xp que tiene capacidad cuda 1.1.
PyTorch ya no admite esta GPU porque es demasiado antigua.
warnings.warn (old_gpu_warn% (d, nombre, mayor, capacidad [1]))
[22.05.19 | 12: 02: 41] Parámetros:
{'base_lr': 0.1, 'ignore_weights': [], 'model': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0.0001, 'work_dir': './work_dir', 'save_interval ': 10,' model_args ': {' in_channels ': 3,' dropout ': 0.5,' num_class ': 60,' edge_importance_weighting ': True,' graph_args ': {' estrategia ':' espacial ',' diseño ': 'ntu-rgb + d'}}, 'debug': False, 'pavi_log': False, 'save_result': False, 'config': 'config / st_gcn / ntu-xsub / train.yaml', 'optimizer': 'SGD', 'weights': None, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'step': [10, 50], 'use_gpu ': True,' phase ':' train ',' print_log ': True,' log_interval ': 100,' feeder ':' feeder.feeder.Feeder ',' start_epoch ': 0,' nesterov ': True,' dispositivo ': [0],' save_log ': True,' test_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/val_data.npy ',' label_path ':' ./data/NTU- RGB-D / xsub / val_label.pkl '},' train_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/train_data.npy ',' debug ': False,' label_path ':' ./data/NTU-RGB-D/xsub/train_l abel.pkl '},' núm_trabajador ': 4}
[22.05.19 | 12: 02: 41] Época de entrenamiento: 0
Rastreo (llamadas recientes más última):
Archivo "main1.py", línea 31, en
p.start ()
Archivo "F: \ Suresh \ st-gcn \ processor \ processor.py", línea 113, en inicio
self.train ()
Archivo "F: \ Suresh \ st-gcn \ processor \ Recognition.py", línea 91, en tren
salida = self.model (datos)
Archivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", línea 489, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "F: \ Suresh \ st-gcn \ net \ st_gcn.py", línea 82, adelante
x, _ = gcn (x, self.A * importancia)
Archivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", línea 489, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "F: \ Suresh \ st-gcn \ net \ st_gcn.py", línea 194, en adelante
x, A = self.gcn (x, A)
Archivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", línea 489, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "F: \ Suresh \ st-gcn \ net \ utils \ tgcn.py", línea 60, adelante
x = self.conv (x)
Archivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", línea 489, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ conv.py", línea 320, en adelante
self.padding, auto.dilatación, auto.group)
RuntimeError: CUDA sin memoria. Intenté asignar 1,37 GiB (GPU 0; 12,00 GiB de capacidad total; 8,28 GiB ya asignados; 652,75 MiB libres; 664,38 MiB en caché)
 Sureshthommandru
en 22 may. 2019
Sureshthommandru
en 22 may. 2019
Se debe a que el mini-lote de datos no cabe en la memoria de la GPU. Simplemente reduzca el tamaño del lote. Cuando configuré el tamaño de lote = 256 para el conjunto de datos cifar10, obtuve el mismo error; Luego configuro el tamaño del lote = 128, está resuelto.
 balcilar
en 1 jun. 2019
balcilar
en 1 jun. 2019
Sí @balcilar tiene razón, reduje el tamaño del lote y ahora funciona
 EKELE-NNOROM
en 4 jun. 2019
EKELE-NNOROM
en 4 jun. 2019
Tengo un problema similar:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
Estoy usando 8 V100 para entrenar el modelo. La parte confusa es que todavía hay 3,03 GB en caché y no se pueden asignar para 11,88 MB.
 magic282
en 10 jun. 2019
magic282
en 10 jun. 2019
¿Cambiaste el tamaño del lote? Reduzca el tamaño del lote a la mitad. Decir el lote
el tamaño es 16 para implementar, intente usar un tamaño de lote de 8 y vea si funciona.
Disfrutar
El lunes, 10 de junio de 2019 a las 2:10 a.m., magic282 [email protected] escribió:
Tengo un problema similar:
RuntimeError: CUDA sin memoria. Intenté asignar 11,88 MiB (GPU 4; 15,75 GiB de capacidad total; 10,50 GiB ya asignados; 1,88 MiB libres; 3,03 GiB en caché)
Estoy usando 8 V100 para entrenar el modelo. La parte confusa es que hay
todavía tiene 3,03 GB en caché y no se puede asignar para 11,88 MB.-
Estás recibiendo esto porque hiciste un comentario.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVDVREXWJWK3TUL52HS4DFVDVREXWG43V2
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
en 10 jun. 2019
Intenté reducir el tamaño del lote y funcionó. La parte confusa es el mensaje de error de que la memoria caché es más grande que la memoria que se va a asignar.
magic282
en 11 jun. 2019
Tengo el mismo problema en un modelo previamente entrenado, cuando uso predecir . Por lo tanto, reducir el tamaño del lote no funcionará.
 pvk444
en 30 jun. 2019
pvk444
en 30 jun. 2019
Si actualiza a la última versión de PyTorch, es posible que tenga menos errores como ese
fmassa
en 30 jun. 2019
¿Puedo preguntar por qué los números del error no cuadran?
Yo (como todos ustedes) obtengo:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
Para mí, significa que lo siguiente debería ser aproximadamente cierto:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
Pero no lo es. ¿Qué es lo que me estoy equivocando?
 AzimAhmadzadeh
en 3 jul. 2019
AzimAhmadzadeh
en 3 jul. 2019
También tuve el problema cuando entrené el U-net, el cach es suficiente, pero aún falla
 tongpinmo
en 10 jul. 2019
tongpinmo
en 10 jul. 2019
Yo tengo el mismo error...
RuntimeError: CUDA sin memoria. Intenté asignar 312,00 MiB (GPU 0; 10,91 GiB de capacidad total; 1,07 GiB ya asignados; 109,62 MiB libres; 15,21 MiB en caché)
 MSKazemi
en 10 jul. 2019
MSKazemi
en 10 jul. 2019
intente reducir el tamaño (cualquier tamaño que no cambie el resultado) funcionará.
 giangnguyen2412
en 11 jul. 2019
giangnguyen2412
en 11 jul. 2019
intente reducir el tamaño (cualquier tamaño que no cambie el resultado) funcionará.
Hola, cambio el batch_size a 1, ¡pero no funciona!
 BCWang93
en 14 jul. 2019
BCWang93
en 14 jul. 2019
Ojalá debas cambiar otro tamaño.
Vào 21:50, CN, 14 Th7, 2019 Bcw93 [email protected] đã viết:
intente reducir el tamaño (cualquier tamaño que no cambie el resultado) funcionará.
Hola, cambio el batch_size a 1, ¡pero no funciona!
-
Estás recibiendo esto porque hiciste un comentario.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVODVREXWJWKNMM2HS4DFVDVREXG43VMD
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
en 15 jul. 2019
Recibiendo este error:
RuntimeError: CUDA sin memoria. Intenté asignar 2,00 MiB (GPU 0; 7,94 GiB de capacidad total; 7,33 GiB ya asignados; 1,12 MiB libre; 40,48 MiB en caché)
nvidia-smi
Jue 22 Ago 21:05:52 2019
+ ------------------------------------------------- ---------------------------- +
| NVIDIA-SMI 430.40 Versión del controlador: 430.40 Versión CUDA: 10.1 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| GPU Name Persistence-M | Bus-Id Disp.A | Uncorr volátil. ECC |
| Fan Temp Perf Pwr: Uso / Cap | Uso de memoria | GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 Quadro M4000 Apagado | 00000000: 09: 00.0 Activado | N / A |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% predeterminado |
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1 GeForce GTX 105 ... Apagado | 00000000: 41: 00.0 Activado | N / A |
| 29% 33C P8 N / A / 75W | 262MiB / 4032MiB | 0% predeterminado |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| Procesos: Memoria GPU |
| GPU PID Tipo Nombre del proceso Uso |
| =============================================== ============================ |
| 0 1909 G / usr / lib / xorg / Xorg 50MiB |
| 1 1909 G / usr / lib / xorg / Xorg 128MiB |
| 1 5236 G ... token-canal-de-misión = 9884100064965360199 130MiB |
+ ------------------------------------------------- ---------------------------- +
SO: Ubuntu 18.04 biónico
Kernel: x86_64 Linux 4.15.0-58-generic
Tiempo de actividad: 29m
Paquetes: 2002
Shell: golpe 4.4.20
Resolución: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
Tema GTK: Lubuntu-predeterminado [GTK2]
Tema del icono: Lubuntu
Fuente: Ubuntu 11
CPU: AMD Ryzen Threadripper 2970WX de 24 núcleos a 48 x 3 GHz [61,8 ° C]
Procesador gráfico: Quadro M4000, GeForce GTX 1050 Ti
RAM: 3194MiB / 64345MiB
 danindiana
en 23 ago. 2019
danindiana
en 23 ago. 2019
¿Está esto arreglado? He reducido el tamaño y el tamaño del lote a 1. No veo ninguna otra solución aquí, pero este ticket está cerrado. Tengo el mismo problema con Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
en 6 sept. 2019
hughkf
en 6 sept. 2019
@hughkf ¿En qué parte del código cambia batch_size?
 aidoshacks
en 6 sept. 2019
aidoshacks
en 6 sept. 2019
@aidoshacks , depende de tu código. Pero he aquí un ejemplo. Este es uno de los cuadernos que causa este problema de manera confiable en mi máquina: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. Cambio la siguiente línea,
bs,size = 8,src_size//2 a bs,size = 1,1 pero todavía tengo este problema de memoria.
hughkf
en 6 sept. 2019
Para mí, cambiar el batch_size de 128 a 64 funcionó, pero eso no parece una solución revelada para mí, ¿o me estoy perdiendo algo?
 shalgi
en 19 sept. 2019
shalgi
en 19 sept. 2019
¿Ha resuelto este problema? También tengo el mismo problema. No cambié nada de mi código, pero después de ejecutarlo muchas veces, se produce este error:
"RuntimeError: CUDA sin memoria. Intenté asignar 40,00 MiB (GPU 0; 15,77 GiB de capacidad total; 13,97 GiB ya asignados; 256,00 KiB libres; 824,57 MiB en caché)"
 mengxiangming
en 26 sept. 2019
mengxiangming
en 26 sept. 2019
Aún teniendo este problema, sería bueno si el estado cambiara a no resuelto.
EDITAR:
Tuvo poco que ver con el tamaño del lote, ya que lo obtengo con el tamaño del lote 1. Reiniciar el kernel lo solucionó y no ha sucedido desde entonces.
 just-in-kees
en 29 sept. 2019
just-in-kees
en 29 sept. 2019
Entonces, ¿cuál es la resolución en ejemplos como a continuación (es decir, mucha memoria libre y tratar de asignar muy poca, lo cual es diferente de algunos ejemplos en este hilo cuando en realidad hay poca cantidad de mem libres y nada está mal)?
RuntimeError: CUDA sin memoria. Intenté asignar 1,33 GiB (GPU 1; 31,72 GiB de capacidad total; 5,68 GiB ya asignados; 24,94 GiB libres ; 5,96 MiB en caché)
No veo por qué el problema pasó al estado 'Cerrado', ya que todavía ocurre en la última versión de pytorch (1.2) y en la GPU NVIDIA moderna (V-100)
¡Gracias!
 yuribd
en 3 oct. 2019
yuribd
en 3 oct. 2019
La mayoría de las veces recibe este mensaje de error en particular del paquete fastai porque está utilizando una GPU inusualmente pequeña. Solucioné este problema reiniciando mi kernel y usando un tamaño de lote más pequeño para la ruta que está dando.
 AurioPinto
en 5 oct. 2019
AurioPinto
en 5 oct. 2019
el mismo problema aqui. Cuando uso pytorch0.4.1, tamaño de lote = 4, está bien. Pero cuando cambio a pytorch1.3 e incluso configuro el tamaño del lote en 1, tengo el problema de oom.
 Sarah20187
en 21 oct. 2019
Sarah20187
en 21 oct. 2019
lo resolví actualizando mi pytorch a la última ... conda update pytorch
 kafura0
en 21 oct. 2019
kafura0
en 21 oct. 2019
Se debe a que el mini-lote de datos no cabe en la memoria de la GPU. Simplemente reduzca el tamaño del lote. Cuando configuré el tamaño de lote = 256 para el conjunto de datos cifar10, obtuve el mismo error; Luego configuro el tamaño del lote = 128, está resuelto.
gracias, solucioné el error de esta manera.
 zhangzibao
en 25 oct. 2019
zhangzibao
en 25 oct. 2019
Disminuí el tamaño de lote a 8, funciona bien. La idea es tener un pequeño tamaño de lote
 Asutosh11
en 30 oct. 2019
Asutosh11
en 30 oct. 2019
Creo que depende del tamaño de entrada total con el que esté tratando una capa en particular. Por ejemplo, si un lote de 256 (32x32) imágenes pasan por 128 filtros en una capa, el tamaño total de entrada es 256x32x32x128 = 2 ^ 25. Este número debería estar por debajo de algún umbral, que supongo que es específico de la máquina. Para AWS p3.2xlarge, por ejemplo, es 2 ^ 26. Por lo tanto, si obtiene errores de memoria CuDA, intente reducir el tamaño del lote o la cantidad de filtros o aplique más submuestreo como capas de zancada o agrupación
 souryadey
en 1 nov. 2019
souryadey
en 1 nov. 2019
Tiene el mismo problema:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
Con la última versión de pytorch (1.3) y cuda (10.1). Nvidia-smi también muestra GPU medio vacía, por lo que la cantidad de memoria libre en el mensaje de error es correcta. Todavía no se puede reproducir con un código simple
 ArgentumWalker
en 3 nov. 2019
ArgentumWalker
en 3 nov. 2019
¡Restablecer el kernel también funcionó para mí! No estaba funcionando incluso con el tamaño de lote = 1 hasta que hice eso
 kennethjmyers
en 7 nov. 2019
kennethjmyers
en 7 nov. 2019
Chicos, resolví mi problema reduciendo el tamaño de mi lote a la mitad.
 faizao
en 19 nov. 2019
faizao
en 19 nov. 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Corregido después de reiniciar
 SomeUserName1
en 22 nov. 2019
SomeUserName1
en 22 nov. 2019
cambió batch_size 64 (rtx2080 ti) a 32 (rtx 2060), problema resuelto. pero quiero saber otra forma de resolver este tipo de problema.
 sailfish009
en 3 dic. 2019
sailfish009
en 3 dic. 2019
¡Esto me está sucediendo cuando hago la predicción !
Cambié el tamaño del lote de 1024 a 8 y sigo obteniendo errores cuando se evalúa el 82% del conjunto de prueba.
Cuando agregué with torch.no_grad() el problema fue RESUELTO.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
en 17 dic. 2019
smasoudn
en 17 dic. 2019
Resolví el problema
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
para
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
en 27 dic. 2019
zhonghaochen
en 27 dic. 2019
Tuve el mismo problema y verifiqué la utilización de la GPU en mi máquina. Ya se usaba mucho y quedaba muy menos memoria. Maté mi cuaderno jupyter y lo reinicié. la memoria se volvió libre y las cosas empezaron a funcionar. Puede utilizar a continuación:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
en 27 dic. 2019
prabhatsharma
en 27 dic. 2019
También recibí este mensaje:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Sucedió cuando intentaba ejecutar la lección 1 de Fast.ai Pets https://course.fast.ai/ (celda 31)
Intente reducir el tamaño de lote (bs) de sus datos de entrenamiento.
Vea lo que funciona para usted.
 rishi0904
en 27 dic. 2019
rishi0904
en 27 dic. 2019
Encontré este problema solucionable sin ajustar el tamaño de su lote.
Terminal abierto y un indicador de Python
import torch
torch.cuda.empty_cache()
Salga del intérprete de Python, vuelva a ejecutar su comando PyTorch original y (con suerte) no debería producir el error de memoria CUDA.
 cpoptic
en 3 ene. 2020
cpoptic
en 3 ene. 2020
Descubrí que cuando mi computadora usa demasiada RAM de CPU, generalmente surge este problema. Entonces, cuando queremos un tamaño de lote más grande, podemos intentar reducir el uso de la RAM de la CPU.
 dhKwang
en 13 ene. 2020
dhKwang
en 13 ene. 2020
Tuve un problema similar.
Reducir el tamaño del lote y reiniciar el kernel ayudó a resolver el problema.
 kumarnikhil936
en 19 ene. 2020
kumarnikhil936
en 19 ene. 2020
En mi caso, reemplazar el optimizador Adam por el optimizador SGD resolvió el mismo problema.
 tranvanluan2
en 23 ene. 2020
tranvanluan2
en 23 ene. 2020
Bueno, en mi caso, usé with torch.no_grad(): (train model) , output.to("cpu") y torch.cuda.empty_cache() y este problema se resolvió.
 PlanNoa
en 30 ene. 2020
PlanNoa
en 30 ene. 2020
RuntimeError: CUDA sin memoria. Intenté asignar 54,00 MiB (GPU 0; 3,95 GiB de capacidad total; 2,65 GiB ya asignados; 39,00 MiB libres; 87,29 MiB en caché)
Encontré la solución y disminuí el valor de batch_size.
 sagrawal06
en 30 ene. 2020
sagrawal06
en 30 ene. 2020
Estoy entrenando un YOLOv3 con pesos Darknet53 en un conjunto de datos personalizado. Mi GPU es una NVIDIA RTX 2080 y estaba enfrentando el mismo problema. Cambiar el tamaño del lote lo solucionó.
 wilderrodrigues
en 2 feb. 2020
wilderrodrigues
en 2 feb. 2020
Recibo este error durante el tiempo de inferencia ... estoy ru
CUDA sin memoria. Intenté asignar 102,00 MiB (GPU 0; 15,78 GiB de capacidad total; 14,54 GiB ya asignados; 48,44 MiB libres; 14,67 GiB reservados en total por PyTorch)
-------------------------------------------------- --------------------------- +
| NVIDIA-SMI 440.59 Versión del controlador: 440.59 Versión CUDA: 10.2 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| GPU Name Persistence-M | Bus-Id Disp.A | Uncorr volátil. ECC |
| Fan Temp Perf Pwr: Uso / Cap | Uso de memoria | GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 Tesla V100-SXM2 ... Encendido | 00000000: 00: 1E.0 Apagado | 0 |
| N / D 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% predeterminado |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| Procesos: Memoria GPU |
| GPU PID Tipo Nombre del proceso Uso |
| =============================================== ============================ |
| 0 13978 C /.conda/envs/ / bin / python 16101MiB |
+ ------------------------------------------------- ---------------------------- +
 tvinith
en 29 feb. 2020
tvinith
en 29 feb. 2020
Se debe a que el mini-lote de datos no cabe en la memoria de la GPU. Simplemente reduzca el tamaño del lote. Cuando configuré el tamaño de lote = 256 para el conjunto de datos cifar10, obtuve el mismo error; Luego configuro el tamaño del lote = 128, está resuelto.
gracias, tienes razón
 Rxma1805
en 2 mar. 2020
Rxma1805
en 2 mar. 2020
Para el caso particular, donde hay suficiente memoria GPU, pero aún se produce un error. En mi caso, lo RESUELVE reduciendo la cantidad de trabajadores en el cargador de datos.
 Yurasyk
en 14 mar. 2020
Yurasyk
en 14 mar. 2020
Fondo
py36, pytorch1.4, tf2.0, conda
afina la Roberta
Asunto
El mismo problema que @EMarquer : pycharm muestra que todavía tengo suficiente memoria, sin embargo, la asignación de memoria falló, sin memoria.
Maneras en que lo intenté
- "batch_size = 1" falló
- "torch.cuda.empty_cache ()" falló
- CUDA_VISIBLE_DEVICES = "0" Python Run.py falló
- Como no uso jupyter, no es necesario reiniciar el kernel
Manera exitosa
- nvidia-smi


- La verdad es que lo que muestra pycharm es diferente a lo que muestra "nvidia-smi" (lo siento, no guardé la imagen de pycharm), en realidad no hay suficiente memoria .
- Los procesos 6123 y 32644 se ejecutan en la terminal antes.
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
en 17 mar. 2020
FernandoZhuang
en 17 mar. 2020
Lo que simplemente funcionó para mí:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
en 6 abr. 2020
MastafaF
en 6 abr. 2020
Encontré este problema solucionable sin ajustar el tamaño de su lote.
Terminal abierto y un indicador de Python
import torch torch.cuda.empty_cache()Salga del intérprete de Python, vuelva a ejecutar su comando PyTorch original y (con suerte) no debería producir el error de memoria CUDA.
En mi caso, resuelve mi problema.
 LiEAEX
en 10 abr. 2020
LiEAEX
en 10 abr. 2020
Asegúrese de usar su GPU en la ranura 0 con --device_ids 0
Sé que estoy machacando la terminología, pero funcionó. Supongo que asume que desea usar la CPU en lugar de la GPU si no selecciona una identificación.
 aaron387
en 12 abr. 2020
aaron387
en 12 abr. 2020
Estoy teniendo el mismo error:
RuntimeError: CUDA sin memoria. Intenté asignar 4,84 GiB (GPU 0; 7,44 GiB de capacidad total; 5,22 GiB ya asignados; 1,75 GiB libres; 18,51 MiB en caché)
Cuando reinicio el clúster o cambio el tamaño del lote, funciona. Pero no me gusta esta solución. Incluso probé torch.cuda.empty_cache (), esto no funciona para mí. ¿Existe alguna otra forma eficiente de resolver esto?
 Tann10
en 13 abr. 2020
Tann10
en 13 abr. 2020
No sé si mi escenario se puede relacionar con el problema original, pero resolví mi problema (el error OOM en el mensaje anterior desapareció) dividiendo las nn capas secuenciales en mi modelo, por ejemplo
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)para
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))Mi modelo tiene muchos más de estos (5 más para ser exactos). ¿Estoy usando nn secuencial, verdad? ¿O es esto un error? @ yf225 @fmassa
Parece que también soluciono el error similar pero a la inversa contigo.
Yo cambio todo
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)para
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
en 14 abr. 2020
xml94
en 14 abr. 2020
Para mí, cambiar batch_size o cualquier solución dada no ayudó. Pero resultó que en mi archivo .cfg tenía valores incorrectos de clases y filtro en una capa. Entonces, si nada ayuda, revise su .cfg.
 ulaszewskim
en 1 may. 2020
ulaszewskim
en 1 may. 2020
Terminal abierta
Primer tipo
nvidia-smi
luego seleccione el PID que corresponda a la ruta de Python o anaconda y escriba
sudo kill -9 PID
 krypticmouse
en 4 may. 2020
krypticmouse
en 4 may. 2020
He tenido este error durante algún tiempo. Para mí, resulta que sigo sosteniendo una variable de Python (es decir, tensor de antorcha) que hace referencia al resultado del modelo, por lo que no se puede liberar de forma segura ya que el código aún puede acceder a él.
Mi código se parece a:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
La solución para esto fue transferir p a una lista. Entonces, el código debería verse así:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
Esto asegura que predictions mantengan valores en la memoria principal, no un tensor en la GPU.
 abdelrahmanhosny
en 8 may. 2020
abdelrahmanhosny
en 8 may. 2020
Tengo este error al usar el módulo fastai.vision, que se basa en pytorch. Estoy usando CUDA 10.1
 jkomyno
en 16 may. 2020
jkomyno
en 16 may. 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
Reducir el tamaño de per_gpu_train_batch_size de 16 a 8, resolvió mi problema.
 autodataming
en 3 jun. 2020
autodataming
en 3 jun. 2020
Si actualiza a la última versión de PyTorch, es posible que tenga menos errores como ese
de verdad, ¿por qué dices eso?
 XinyingZheng
en 9 jun. 2020
XinyingZheng
en 9 jun. 2020
La cuestión principal de este tema sigue siendo un problema abierto. Recibo el mismo mensaje extraño de CUDA fuera de la memoria. Intentó asignar 2,26 GiB en 4,08 GiB libres. Aparentemente hay suficiente memoria pero no se puede asignar.
Información del proyecto: entrenando un conjunto de datos resnet 10 sobre activitynet con tamaño de lote 4, falla en la final de la primera época.
EDITADO: Algunas percepciones: si limpio mi memoria RAM y solo mantengo el código Python en ejecución, el error no aparece. Tal vez haya suficiente memoria en la GPU, pero la memoria RAM no puede manejar todos los demás pasos de procesamiento.
Información de la computadora: Dell G5 - i7 9th - GTX 1660Ti 6GB - 16 GB RAM
EDITADO2: Estaba usando "_MultiProcessingDataLoaderIter" con 4 trabajadores y genera el mensaje de memoria insuficiente en la llamada de reenvío. Si reduzco el número de trabajadores a 1, no genera ningún error. Con 1 trabajador, el uso de memoria RAM sigue siendo de 11/16 GB, con 4 aumenta a 14,5 / 16 GB. Y con solo 1 trabajador, en realidad, puedo aumentar el tamaño del lote a 32, elevando la memoria de la GPU a 3.5GB / 6GB.
RuntimeError: CUDA sin memoria. Intenté asignar 2,26 GiB (GPU 0; 6,00 GiB de capacidad total; 209,63 MiB ya asignados; 4,08 GiB libres; 246,00 MiB reservados en total por PyTorch)
Mensaje de error completo
Rastreo (llamadas recientes más última):
Archivo "main.py", línea 450, en
si opt.distribuido:
Archivo "main.py", línea 409, en main_worker
opt.device, current_lr, train_logger,
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ training.py", línea 37, en train_epoch
salidas = modelo (entradas)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", línea 532, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nnparallel \ data_parallel.py", línea 150, en adelante
return self.module ( entradas [0], * kwargs [0])
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", línea 532, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py", línea 205, en adelante
x = self.layer3 (x)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", línea 532, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ container.py", línea 100, en adelante
entrada = módulo (entrada)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", línea 532, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py", línea 51, en adelante
out = self.conv2 (fuera)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", línea 532, en __call__
resultado = self.forward ( entrada, * kwargs)
Archivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ conv.py", línea 480, en adelante
self.padding, auto.dilatación, auto.group)
RuntimeError: CUDA sin memoria. Intenté asignar 2,26 GiB (GPU 0; 6,00 GiB de capacidad total; 209,63 MiB ya asignados; 4,08 GiB libres; 246,00 MiB reservados
en total por PyTorch)
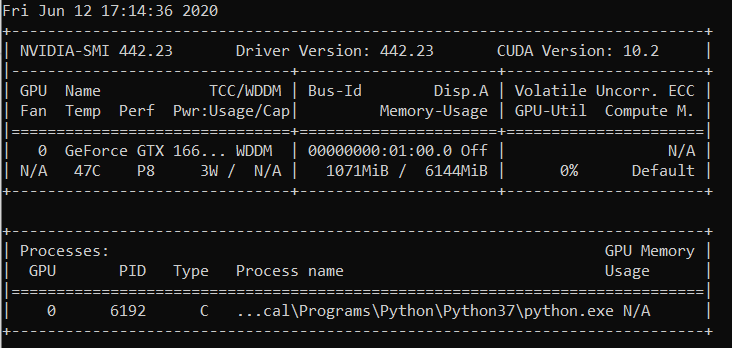
 guilhermesurek
en 12 jun. 2020
guilhermesurek
en 12 jun. 2020
pequeño el tamaño del lote, funciona
 cuge1995
en 15 jun. 2020
cuge1995
en 15 jun. 2020
He tenido este error durante algún tiempo. Para mí, resulta que sigo sosteniendo una variable de Python (es decir, tensor de antorcha) que hace referencia al resultado del modelo, por lo que no se puede liberar de forma segura ya que el código aún puede acceder a él.
Mi código se parece a:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)La solución para esto fue transferir
pa una lista. Entonces, el código debería verse así:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Esto asegura que
predictionsmantengan valores en la memoria principal, no un tensor en la GPU.
@abdelrahmanhosny Gracias por señalar esto. Enfrenté exactamente el mismo problema en PyTorch 1.5.0, y no tuve problemas de OOM durante el entrenamiento, sin embargo, durante la inferencia también mantuve una variable de Python (es decir, tensor de antorcha) que hace referencia al resultado del modelo en la memoria, lo que provocó que la GPU se quedara sin memoria. después de un cierto número de lotes.
En mi caso, sin embargo, transferir las predicciones a la lista no funcionó ya que estoy generando imágenes con mi red, por lo tanto, tuve que hacer lo siguiente:
predictions.append(p.detach().cpu().numpy())
¡Esto entonces resolvió el problema!
 samkellerhals
en 19 jun. 2020
samkellerhals
en 19 jun. 2020
¿Existe alguna solución general?
CUDA sin memoria. Intenté asignar 196,00 MiB (GPU 0; 2,00 GiB de capacidad total; 359,38 MiB ya asignados; 192,29 MiB libres; 152,37 MiB en caché)
¿Existe alguna solución general?
CUDA sin memoria. Intenté asignar 196,00 MiB (GPU 0; 2,00 GiB de capacidad total; 359,38 MiB ya asignados; 192,29 MiB libres; 152,37 MiB en caché)
 manavkhadka0
en 24 jun. 2020
manavkhadka0
en 24 jun. 2020
He tenido este error durante algún tiempo. Para mí, resulta que sigo sosteniendo una variable de Python (es decir, tensor de antorcha) que hace referencia al resultado del modelo, por lo que no se puede liberar de forma segura ya que el código aún puede acceder a él.
Mi código se parece a:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)La solución para esto fue transferir
pa una lista. Entonces, el código debería verse así:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Esto asegura que
predictionsmantengan valores en la memoria principal, no un tensor en la GPU.@abdelrahmanhosny Gracias por señalar esto. Enfrenté exactamente el mismo problema en PyTorch 1.5.0, y no tuve problemas de OOM durante el entrenamiento, sin embargo, durante la inferencia también mantuve una variable de Python (es decir, tensor de antorcha) que hace referencia al resultado del modelo en la memoria, lo que provocó que la GPU se quedara sin memoria. después de un cierto número de lotes.
En mi caso, sin embargo, transferir las predicciones a la lista no funcionó ya que estoy generando imágenes con mi red, por lo tanto, tuve que hacer lo siguiente:
predictions.append(p.detach().cpu().numpy())¡Esto entonces resolvió el problema!
Tengo el mismo problema en el modelo ParrallelWaveGAN y utilicé las soluciones en # 16417 pero no me funciona
y = self.model_gan (* x) .view (-1) .detach (). cpu (). numpy ()
gc.collect ()
torch.cuda.empty_cache ()
 tuong-olli
en 25 jun. 2020
tuong-olli
en 25 jun. 2020
Tuve el mismo problema durante el entrenamiento.
Recolectar basura y vaciar la memoria cuda después de cada época me resolvió el problema.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
en 5 ago. 2020
IsakWesterlundBitville
en 5 ago. 2020
Lo que simplemente funcionó para mí:
import gc # Your code with pytorch using GPU gc.collect()
¡¡Gracias!! Estaba teniendo problemas para ejecutar el ejemplo de perros y gatos y esto funcionó para mí.
 Michelpayan
en 5 ago. 2020
Michelpayan
en 5 ago. 2020
Tuve el mismo problema durante el entrenamiento.
Recolectar basura y vaciar la memoria cuda después de cada época me resolvió el problema.gc.collect() torch.cuda.empty_cache()
Lo mismo para mi
 AleksandrTulenkov
en 6 ago. 2020
AleksandrTulenkov
en 6 ago. 2020
Disminuya el tamaño del lote y aumente las épocas. así es como lo resolví.
 oyekamal
en 18 sept. 2020
oyekamal
en 18 sept. 2020
@areebsyed Verifique la memoria RAM, tuve este problema cuando configuré muchos trabajadores en paralelo.
guilhermesurek
en 29 sept. 2020
También recibo el mismo error al ajustar con precisión bert2bert EncoderDecoderModel preentrenado en pytorch en Colab sin siquiera completar una sola época.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
en 6 oct. 2020
Aakash12980
en 6 oct. 2020
@ Aakash12980 ¿Intentaste reducir el tamaño del lote? Además, las imágenes de entrada que desea entrenar tal vez intenten cambiar su tamaño
 areebsyed
en 6 oct. 2020
areebsyed
en 6 oct. 2020
@areebsyed Sí, reduje el tamaño del lote a 4 y funcionó.
Aakash12980
en 6 oct. 2020
mismo
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
en 7 oct. 2020
monajalal
en 7 oct. 2020
mismo
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal intente reducir el tamaño del lote o el tamaño de la dimensión de entrada.
Aakash12980
en 7 oct. 2020
Entonces, ¿cuál es la resolución en ejemplos como a continuación (es decir, mucha memoria _free_ y tratar de asignar muy poca, que es diferente de _algunos_ ejemplos en este hilo cuando en realidad hay poca cantidad de mem libres y nada está mal)?
RuntimeError: CUDA sin memoria. Intenté asignar _ 1,33 GiB _ (GPU 1; 31,72 GiB de capacidad total; 5,68 GiB ya asignados; _ 24,94 GiB libres _; 5,96 MiB en caché)
No veo por qué el problema pasó al estado 'Cerrado', ya que todavía ocurre en la última versión de pytorch (1.2) y en la GPU NVIDIA moderna (V-100)
¡Gracias!
Sí, siento que la mayoría de la gente no se da cuenta de que el problema no es simplemente OOM, es que hay OOM mientras que el error dice que hay suficiente espacio libre. También estoy enfrentando este problema en Windows, ¿encontraste alguna solución?
 YoadTew
en 6 nov. 2020
YoadTew
en 6 nov. 2020
Temas relacionados
 cdluminate
·
3Comentarios
cdluminate
·
3Comentarios
 bartolsthoorn
·
3Comentarios
bartolsthoorn
·
3Comentarios
 soumith
·
3Comentarios
soumith
·
3Comentarios
 ikostrikov
·
3Comentarios
ikostrikov
·
3Comentarios
 Coderx7
·
3Comentarios
Coderx7
·
3Comentarios
Comentario más útil
Se debe a que el mini-lote de datos no cabe en la memoria de la GPU. Simplemente reduzca el tamaño del lote. Cuando configuré el tamaño de lote = 256 para el conjunto de datos cifar10, obtuve el mismo error; Luego configuro el tamaño del lote = 128, está resuelto.