Pytorch: 런타임 오류: CUDA 메모리가 부족합니다. 12.50MiB 할당 시도(GPU 0, 10.92GiB 총 용량, 8.57MiB 이미 할당됨, 9.28GiB 여유 공간, 4.68MiB 캐시됨)
CUDA 메모리 부족 오류이지만 CUDA 메모리가 거의 비어 있습니다.
저는 현재 매우 많은 양의 텍스트 데이터(약 70GiB의 텍스트)에 대해 경량 모델을 훈련하고 있습니다.
이를 위해 클러스터에서 시스템을 사용하고 있습니다( grid5000 클러스터 네트워크의 'grele' ).
이 매우 이상한 CUDA 메모리 부족 오류 메시지를 3시간 동안 교육한 후 다음과 같은 메시지가 나타납니다.
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
메시지에 따르면 필요한 공간이 있지만 메모리를 할당하지 않습니다.
이 문제의 원인이 무엇인지 아십니까?
참고로 내 사전 처리는 torch.multiprocessing.Queue 및 내 소스 데이터 라인에 대한 반복자를 사용하여 데이터를 즉석에서 사전 처리합니다.
전체 스택 추적
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
모든 91 댓글
동일한 런타임 오류가 있습니다.
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
에 2019년 01월 27일
OmarBazaraa
에 2019년 01월 27일
@EMarquer @OmarBazaraa 우리가 실행할 수 있는 최소한의 재현 예제를 줄 수 있습니까?
 yf225
에 2019년 01월 28일
yf225
에 2019년 01월 28일
더 이상 문제를 재현할 수 없으므로 문제를 종료합니다.
RAM에 전처리된 데이터 저장을 중단하면 문제가 사라졌습니다.
@OmarBazaraa , 다음과 같이 귀하의 문제가 내 문제와 동일하다고 생각하지 않습니다.
- 9.28GiB 여유 공간이 있는 12.50MiB를 할당하려고 합니다.
- 170.14MiB 여유 공간이 있는 195.25MiB를 할당하려고 합니다.
이 문제에 대한 나의 이전 경험에 따르면 CUDA 메모리를 해제하지 않거나 CUDA에 너무 많은 데이터를 넣으려고 합니다.
CUDA 메모리를 해제하지 않음으로써 더 이상 사용하지 않는 CUDA의 텐서에 대한 참조가 여전히 있을 수 있음을 의미합니다. 이는 텐서를 삭제하여 할당된 메모리가 해제되는 것을 방지합니다.
EMarquer
에 2019년 01월 28일
일반적인 해결책이 있습니까?
CUDA 메모리가 부족합니다. 196.00MiB 할당 시도(GPU 0, 2.00GiB 총 용량, 359.38MiB 이미 할당됨, 192.29MiB 여유 공간, 152.37MiB 캐시됨)
 aniketspurohit
에 2019년 01월 31일
aniketspurohit
에 2019년 01월 31일
@aniks23 우리는 이 경우 더 나은 경험을 제공할 것이라고 생각하는 패치를 작업 중입니다. 계속 지켜봐 주세요
 fmassa
에 2019년 01월 31일
fmassa
에 2019년 01월 31일
내 시스템이 처리할 수 있는 모델이나 네트워크의 크기를 알 수 있는 방법이 있습니까?
이 문제에 부딪히지 않고?
2019년 2월 1일 금요일 오전 3:55 Francisco Massa [email protected]
썼다:
@aniks23 https://github.com/aniks23 우리는 패치를 작업 중입니다.
이 경우 더 나은 경험을 제공할 것이라고 믿습니다. 계속 지켜봐 주세요—
당신이 언급되었기 때문에 이것을 받는 것입니다.
이 이메일에 직접 답장하고 GitHub에서 확인
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
또는 스레드 음소거
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
에 2019년 02월 01일
이 메시지도 받았습니다.
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Fast.ai Lesson1 Pets https://course.fast.ai/ (cell 31)를 실행하려고 할 때 발생했습니다.
 adrianovieira
에 2019년 03월 12일
adrianovieira
에 2019년 03월 12일
저도 같은 오류에 빠져있습니다. 내 모델은 이전에 정확한 설정으로 작업했지만 지금은 관련이 없어 보이는 일부 코드를 수정한 후 이 오류가 발생합니다.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
에 2019년 03월 14일
treble-maker123
에 2019년 03월 14일
내 시나리오가 원래 문제와 관련이 있는지 모르겠지만 내 모델의 nn.Sequential 레이어를 분해하여 문제(이전 메시지의 OOM 오류가 사라졌습니다)를 해결했습니다.
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
에게
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
내 모델에는 이 중 훨씬 더 많은 것이 있습니다(정확히 5개 이상). nn.Sequential을 사용하고 있습니까? 아니면 이것이 버그입니까? @yf225 @fmassa
treble-maker123
에 2019년 03월 14일
비슷한 오류가 발생합니다.
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@treble-maker123, nn.Sequential이 문제라는 것을 결론적으로 증명할 수 있었습니까?
 yasheshgaur
에 2019년 03월 17일
yasheshgaur
에 2019년 03월 17일
비슷한 문제가 있습니다. pytorch 데이터 로더를 사용하고 있습니다. 5GB 이상의 여유 공간이 있어야 하지만 0바이트 여유 공간이 제공됩니다.
RuntimeError Traceback(가장 최근 호출 마지막)
22
23 데이터, 입력 = 상태_입력
---> 24개 데이터, 입력 = Variable(data).float().to(device), Variable(inputs).float().to(device)
25 인쇄(data.device)
26 enc_out = 인코더(데이터)
런타임 오류: CUDA 메모리가 부족합니다. 11.00MiB 할당 시도(GPU 0, 6.00GiB 총 용량, 448.58MiB 이미 할당됨, 0바이트 여유 공간, 942.00KiB 캐시됨)
 ahsteven
에 2019년 04월 03일
ahsteven
에 2019년 04월 03일
안녕하세요, 저도이 오류가 발생했습니다.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
에 2019년 04월 17일
AlbertZhangHIT
에 2019년 04월 17일
슬프게도 나는 같은 문제를 만났습니다.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
서버 클러스터에서 내 모델을 훈련했는데 내 서버 중 하나에 예기치 않게 오류가 발생했습니다. 또한 이러한 유선 오류는 내 훈련 전략 중 하나에서만 발생합니다. 그리고 유일한 차이점은 데이터 보강 중에 코드를 수정 하고 데이터 전처리를 다른 것보다 복잡하게 만든다는 것입니다. 하지만 이 문제를 해결하는 방법을 잘 모르겠습니다.
 qingyu-wang
에 2019년 04월 25일
qingyu-wang
에 2019년 04월 25일
나는 또한이 문제가 있습니다. 해결 방법??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
에 2019년 05월 10일
nabil2i
에 2019년 05월 10일
여기도 같은 문제 RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
에 2019년 05월 16일
williamluke4
에 2019년 05월 16일
@fmassa 이것에 대한 더 많은 정보가 있습니까?
williamluke4
에 2019년 05월 18일
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
나에게 같은 문제
친애하는, 솔루션을 얻었습니까?
(기본) F:\Suresh\st-gcn>python main1.py 인식 -c config/st_gcn/ntu-xsub/train.yaml --device 0 --work_dir ./work_dir
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117: UserWarning:
cuda 기능 1.1의 GPU0 TITAN Xp를 찾았습니다.
PyTorch는 이 GPU가 너무 오래되었기 때문에 더 이상 지원하지 않습니다.
warnings.warn(old_gpu_warn % (d, 이름, 주요, 기능[1]))
[05.22.19|12:02:41] 매개변수:
{'base_lr': 0.1, 'ignore_weights': [], '모델': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0.0001, 'work_dir': './work_dir', 'save_interval ': 10, 'model_args': {'in_channels': 3, 'dropout': 0.5, 'num_class': 60, 'edge_importance_weighting': True, 'graph_args': {'전략': '공간', '레이아웃': 'ntu-rgb+d'}}, '디버그': 거짓, 'pavi_log': 거짓, 'save_result': 거짓, 'config': 'config/st_gcn/ntu-xsub/train.yaml', '최적화기': 'SGD', '가중치': 없음, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'step': [10, 50], 'use_gpu ': True, 'phase': 'train', 'print_log': True, 'log_interval': 100, 'feeder': 'feeder.feeder.Feeder', 'start_epoch': 0, 'nesterov': True, '장치 ': [0], 'save_log': 참, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU- RGB-D/xsub/val_label.pkl'}, 'train_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/train_data.npy', '디버그': False, 'label_path': ' ./data/NTU-RGB-D/xsub/train_l abel.pkl'}, 'num_worker': 4}
[05.22.19|12:02:41] 훈련 에포크: 0
역추적(가장 최근 호출 마지막):
파일 "main1.py", 31행,
p.start()
파일 "F:\Suresh\st-gcn\processor\processor.py", 113행, 시작 시
self.train()
파일 "F:\Suresh\st-gcn\processor\recognition.py", 91행, 기차
출력 = self.model(데이터)
파일 "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", 489행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "F:\Suresh\st-gcn\net\st_gcn.py", 82행, 앞으로
x, _ = gcn(x, self.A * 중요도)
파일 "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", 489행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "F:\Suresh\st-gcn\net\st_gcn.py", 194행, 앞으로
x, A = self.gcn(x, A)
파일 "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", 489행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "F:\Suresh\st-gcn\net\utils\tgcn.py", 60행, 앞으로
x = self.conv(x)
파일 "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", 489행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py", 320행, 앞으로
self.padding, self.dilation, self.groups)
런타임 오류: CUDA 메모리가 부족합니다. 1.37GiB 할당 시도(GPU 0, 12.00GiB 총 용량, 8.28GiB 이미 할당됨, 652.75MiB 여유 공간, 664.38MiB 캐시됨)
 Sureshthommandru
에 2019년 05월 22일
Sureshthommandru
에 2019년 05월 22일
데이터의 미니 배치가 GPU 메모리에 맞지 않기 때문입니다. 배치 크기를 줄이면 됩니다. cifar10 데이터 세트에 대해 배치 크기 = 256을 설정할 때 동일한 오류가 발생했습니다. 그런 다음 배치 크기 = 128로 설정하면 해결됩니다.
 balcilar
에 2019년 06월 01일
balcilar
에 2019년 06월 01일
예 @balcilar 가 맞습니다. 배치 크기를 줄였으며 이제 작동합니다.
 EKELE-NNOROM
에 2019년 06월 04일
EKELE-NNOROM
에 2019년 06월 04일
비슷한 문제가 있습니다.
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
8 V100을 사용하여 모델을 훈련하고 있습니다. 혼란스러운 부분은 여전히 3.03GB가 캐시되어 있으며 11.88MB에 할당할 수 없다는 것입니다.
 magic282
에 2019년 06월 10일
magic282
에 2019년 06월 10일
배치 크기를 변경했습니까? 배치 크기를 절반으로 줄이십시오. 배치를 말하다
구현하기 위해 크기는 16입니다. 배치 크기 8을 사용해 보고 작동하는지 확인하십시오.
즐기다
2019년 6월 10일 월요일 오전 2시 10분에 magic282 [email protected]에서 다음과 같이 썼습니다.
비슷한 문제가 있습니다.
런타임 오류: CUDA 메모리가 부족합니다. 11.88MiB 할당 시도(GPU 4, 15.75GiB 총 용량, 10.50GiB 이미 할당됨, 1.88MiB 여유 공간, 3.03GiB 캐시됨)
8 V100을 사용하여 모델을 훈련하고 있습니다. 헷갈리는 부분은
여전히 3.03GB가 캐시되어 11.88MB에 할당할 수 없습니다.—
당신이 댓글을 달았기 때문에 이것을 받는 것입니다.
이 이메일에 직접 답장하고 GitHub에서 확인
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWissues3TUL52HS4DFVEXG43VMXXVWJ3NVWWK3TUL52HS4DFVREWSL
또는 스레드 음소거
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
에 2019년 06월 10일
배치 크기를 줄이려고 시도했지만 효과가있었습니다. 혼란스러운 부분은 캐시된 메모리가 할당할 메모리보다 크다는 오류 메시지입니다.
magic282
에 2019년 06월 11일
나는 predict 를 사용할 때 사전 훈련된 모델에서 동일한 문제를 얻습니다. 따라서 배치 크기를 줄이는 것은 효과가 없습니다.
 pvk444
에 2019년 06월 30일
pvk444
에 2019년 06월 30일
최신 버전의 PyTorch로 업데이트하면 이와 같은 오류가 덜 발생할 수 있습니다.
fmassa
에 2019년 06월 30일
오류의 숫자가 합산되지 않는 이유를 여쭤봐도 될까요?!
나는 (여러분 모두와 마찬가지로) 다음을 얻습니다.
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
나에게 그것은 다음이 대략 사실이어야 함을 의미합니다.
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
하지만 그렇지 않습니다. 내가 무엇을 잘못 알고 있습니까?
 AzimAhmadzadeh
에 2019년 07월 03일
AzimAhmadzadeh
에 2019년 07월 03일
U-net을 훈련할 때도 문제가 발생했습니다. 캐시는 충분하지만 여전히 충돌합니다.
 tongpinmo
에 2019년 07월 10일
tongpinmo
에 2019년 07월 10일
나는 같은 오류가 있습니다 ...
런타임 오류: CUDA 메모리가 부족합니다. 312.00MiB 할당 시도(GPU 0, 10.91GiB 총 용량, 1.07GiB 이미 할당됨, 109.62MiB 여유 공간, 15.21MiB 캐시됨)
 MSKazemi
에 2019년 07월 10일
MSKazemi
에 2019년 07월 10일
크기를 줄이십시오(결과를 변경하지 않는 모든 크기)가 작동합니다.
 giangnguyen2412
에 2019년 07월 11일
giangnguyen2412
에 2019년 07월 11일
크기를 줄이십시오(결과를 변경하지 않는 모든 크기)가 작동합니다.
안녕하세요, batch_size를 1로 변경했지만 작동하지 않습니다!
 BCWang93
에 2019년 07월 14일
BCWang93
에 2019년 07월 14일
다른 크기로 변경해야 합니다.
Vào 21:50, CN, 2019년 7월 14일 Bcw93 [email protected] đã viết:
크기를 줄이십시오(결과를 변경하지 않는 모든 크기)가 작동합니다.
안녕하세요, batch_size를 1로 변경했지만 작동하지 않습니다!
—
당신이 댓글을 달았기 때문에 이것을 받는 것입니다.
이 이메일에 직접 답장하고 GitHub에서 확인
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVEXG43VMVVBW63
또는 스레드 음소거
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
에 2019년 07월 15일
이 오류가 발생하는 경우:
런타임 오류: CUDA 메모리가 부족합니다. 2.00MiB 할당 시도(GPU 0, 7.94GiB 총 용량, 7.33GiB 이미 할당됨, 1.12MiB 여유 공간, 40.48MiB 캐시됨)
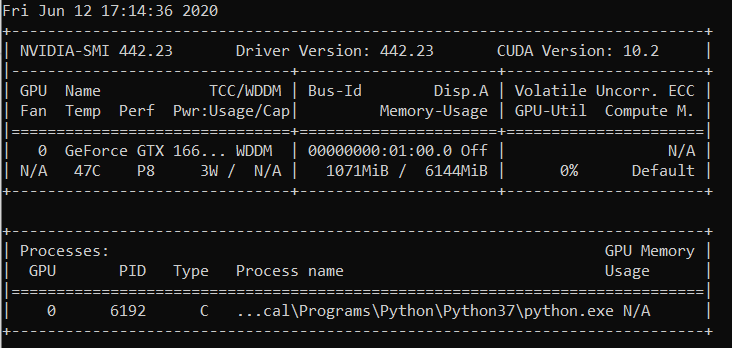
엔비디아-smi
2019년 8월 22일 목 21:05:52
+---------------------------------------------------------------- --------------------------+
| NVIDIA-SMI 430.40 드라이버 버전: 430.40 CUDA 버전: 10.1 |
|---------------------------------------------+----------------- --+----------------------+
| GPU 이름 지속성-M| 버스 ID Disp.A | 휘발성 부정확. ECC |
| 팬 온도 성능 Pwr: 사용량/한도 | 메모리 사용량 | GPU 활용 컴퓨팅 M. |
|===================================================== =====+========================|
| 0 Quadro M4000 끄기 | 00000000:09:00.0 켜기 | 해당 없음 |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% 기본값 |
+-------------------------------+-------------------- --+----------------------+
| 1 GeForce GTX 105... 끄기 | 00000000:41:00.0 켜기 | 해당 없음 |
| 29% 33C P8 해당 없음 / 75W | 262MiB / 4032MiB | 0% 기본값 |
+-------------------------------+-------------------- -----+----------------------+
+---------------------------------------------------------------- --------------------------+
| 프로세스: GPU 메모리 |
| GPU PID 유형 프로세스 이름 사용법 |
|=================================================== ==============================|
| 0 1909 G /usr/lib/xorg/Xorg 50MiB |
| 1 1909 G /usr/lib/xorg/Xorg 128MiB |
| 1 5236 G ...퀘스트 채널 토큰=9884100064965360199 130MiB |
+---------------------------------------------------------------- --------------------------+
OS: 우분투 18.04 바이오닉
커널: x86_64 Linux 4.15.0-58-일반
가동 시간: 29분
패키지: 2002년
쉘: bash 4.4.20
해상도: 1920x1080 1080x1920
DE: LXDE
WM: 오픈박스
GTK 테마: Lubuntu-default [GTK2]
아이콘 테마: 루분투
글꼴: 우분투 11
CPU: AMD Ryzen Threadripper 2970WX 24코어 @ 48x 3GHz [61.8°C]
GPU: 쿼드로 M4000, 지포스 GTX 1050 Ti
램: 3194MiB / 64345MiB
 danindiana
에 2019년 08월 23일
danindiana
에 2019년 08월 23일
이거 고쳐졌나요? 크기와 배치 크기를 모두 1로 줄였습니다. 여기에 다른 솔루션이 없지만 이 티켓은 닫혀 있습니다. Cuda 10.1 Windows 10, Pytorch 1.2.0에서 동일한 문제가 있습니다.
 hughkf
에 2019년 09월 06일
hughkf
에 2019년 09월 06일
@hughkf 코드의 어디에서 batch_size를 변경합니까?
 aidoshacks
에 2019년 09월 06일
aidoshacks
에 2019년 09월 06일
@aidoshacks , 코드에 따라 다릅니다. 그러나 여기에 한 가지 예가 있습니다. 이것은 내 컴퓨터에서 이 문제를 안정적으로 일으키는 노트북 중 하나입니다: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. 다음 줄을 변경합니다.
bs,size = 8,src_size//2 ~ bs,size = 1,1 하지만 여전히 메모리 부족 문제가 발생합니다.
hughkf
에 2019년 09월 06일
나를 위해 batch_size를 128에서 64로 변경하는 것이 효과가 있었지만 나에게 공개된 솔루션처럼 보이지 않거나 내가 놓치고 있는 것이 있습니까?
 shalgi
에 2019년 09월 19일
shalgi
에 2019년 09월 19일
이 문제가 해결되었습니까? 나는 또한 같은 문제가 발생했습니다. 내 코드를 변경하지 않았지만 여러 번 실행한 후 다음 오류가 발생합니다.
"런타임 오류: CUDA 메모리 부족. 40.00MiB 할당 시도(GPU 0, 15.77GiB 총 용량, 13.97GiB 이미 할당됨, 256.00KiB 여유 공간, 824.57MiB 캐시됨)"
 mengxiangming
에 2019년 09월 26일
mengxiangming
에 2019년 09월 26일
여전히 이 문제가 있는 경우 상태가 해결되지 않음으로 변경되면 좋을 것입니다.
편집하다:
배치 크기 1로 볼 때 배치 크기와 거의 관련이 없었습니다. 커널을 다시 시작하면 문제가 해결되었으며 그 이후로는 발생하지 않았습니다.
 just-in-kees
에 2019년 09월 29일
just-in-kees
에 2019년 09월 29일
그렇다면 아래와 같은 예제의 해결 방법은 무엇입니까(즉, 많은 여유 메모리와 매우 적은 할당을 시도합니다. 이는 실제로 일부 예제와 다릅니다)?
런타임 오류: CUDA 메모리가 부족합니다. 1.33 지브을 할당 시도 (GPU 1, 31.72 지브 총 용량, 5.68 지브가 이미 할당, 24.94 지브 무료, 5.96 MIB는 캐시)
최신 pytorch 버전(1.2) 및 최신 NVIDIA GPU(V-100)에서 여전히 발생하므로 문제가 '닫힘' 상태로 전환된 이유를 모르겠습니다.
감사 해요!
 yuribd
에 2019년 10월 03일
yuribd
에 2019년 10월 03일
fastai 패키지에서 이 특정 오류 메시지를 받는 대부분의 경우 비정상적으로 작은 GPU를 사용하고 있기 때문입니다. 커널을 다시 시작하고 제공하는 경로에 더 작은 배치 크기를 사용하여 이 문제를 해결했습니다.
 AurioPinto
에 2019년 10월 05일
AurioPinto
에 2019년 10월 05일
여기에 같은 문제가 있습니다. pytorch0.4.1, 배치 크기=4를 사용할 때 괜찮습니다. 그러나 pytorch1.3으로 변경하고 배치 크기를 1로 설정해도 oom 문제가 발생합니다.
 Sarah20187
에 2019년 10월 21일
Sarah20187
에 2019년 10월 21일
내 pytorch를 최신 버전으로 업데이트하여 해결했습니다... conda update pytorch
 kafura0
에 2019년 10월 21일
kafura0
에 2019년 10월 21일
데이터의 미니 배치가 GPU 메모리에 맞지 않기 때문입니다. 배치 크기를 줄이면 됩니다. cifar10 데이터 세트에 대해 배치 크기 = 256을 설정할 때 동일한 오류가 발생했습니다. 그런 다음 배치 크기 = 128로 설정하면 해결됩니다.
덕분에 이 방법으로 오류를 해결했습니다.
 zhangzibao
에 2019년 10월 25일
zhangzibao
에 2019년 10월 25일
batch_size를 8로 줄였더니 잘 됩니다. 아이디어는 작은 batch_size를 갖는 것입니다.
 Asutosh11
에 2019년 10월 30일
Asutosh11
에 2019년 10월 30일
특정 레이어가 처리하는 총 입력 크기에 따라 다르다고 생각합니다. 예를 들어, 256(32x32) 이미지의 배치가 레이어에서 128개의 필터를 통과하는 경우 총 입력 크기는 256x32x32x128 = 2^25입니다. 이 숫자는 특정 임계값보다 낮아야 하며 이는 시스템에 따라 다릅니다. 예를 들어 AWS p3.2xlarge의 경우 2^26입니다. 따라서 CuDA 메모리 오류가 발생하는 경우 배치 크기 또는 필터 수를 줄이거나 스트라이드 또는 풀링 레이어와 같은 더 많은 다운샘플링을 넣어보십시오.
 souryadey
에 2019년 11월 01일
souryadey
에 2019년 11월 01일
같은 문제가 있습니다:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
최신 pytorch(1.3) 및 cuda(10.1) 버전. Nvidia-smi는 또한 GPU가 반쯤 비어 있음을 보여주므로 오류 메시지의 여유 메모리 양이 정확합니다. 아직 간단한 코드로 재현할 수 없음
 ArgentumWalker
에 2019년 11월 03일
ArgentumWalker
에 2019년 11월 03일
커널 재설정도 저에게 효과적이었습니다! 내가 할 때까지 배치 크기 = 1로도 작동하지 않았습니다.
 kennethjmyers
에 2019년 11월 07일
kennethjmyers
에 2019년 11월 07일
여러분, 배치 크기를 절반으로 줄이는 문제를 해결했습니다.
 faizao
에 2019년 11월 19일
faizao
에 2019년 11월 19일
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
재부팅 후 수정
 SomeUserName1
에 2019년 11월 22일
SomeUserName1
에 2019년 11월 22일
batch_size 64(rtx2080 ti)를 32(rtx 2060)로 변경하여 문제가 해결되었습니다. 하지만 이런 종류의 문제를 해결하는 다른 방법을 알고 싶습니다.
 sailfish009
에 2019년 12월 03일
sailfish009
에 2019년 12월 03일
이것은 내가 예측을 할 때 나에게 일어나고 있습니다!
배치 크기를 1024에서 8로 변경했는데 테스트 세트의 82%가 평가될 때 여전히 오류가 발생합니다.
with torch.no_grad() 추가했을 때 문제가 해결되었습니다.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
에 2019년 12월 17일
smasoudn
에 2019년 12월 17일
나는 문제를 해결했다
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
에게
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
에 2019년 12월 27일
zhonghaochen
에 2019년 12월 27일
나는 같은 문제가 있었고 내 컴퓨터의 GPU 사용률을 확인했습니다. 이미 많이 사용되었고 매우 적은 양의 메모리가 남았습니다. jupyter 노트북을 종료하고 다시 시작했습니다. 메모리가 자유로워지고 작업이 시작되었습니다. 아래에서 사용할 수 있습니다.
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
에 2019년 12월 27일
prabhatsharma
에 2019년 12월 27일
이 메시지도 받았습니다.
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Fast.ai Lesson1 Pets https://course.fast.ai/ (cell 31)를 실행하려고 할 때 발생했습니다.
훈련 데이터의 배치 크기(bs)를 줄이십시오.
당신에게 효과가 무엇인지보십시오.
 rishi0904
에 2019년 12월 27일
rishi0904
에 2019년 12월 27일
배치 크기를 조정하지 않고도 이 문제를 해결할 수 있음을 발견했습니다.
터미널 및 파이썬 프롬프트 열기
import torch
torch.cuda.empty_cache()
Python 인터프리터를 종료하고 원래 PyTorch 명령을 다시 실행하면 CUDA 메모리 오류가 발생하지 않아야 합니다.
 cpoptic
에 2020년 01월 03일
cpoptic
에 2020년 01월 03일
내 컴퓨터가 CPU RAM을 너무 많이 사용하면 일반적으로 이 문제가 발생한다는 것을 알았습니다. 따라서 더 큰 배치 크기를 원할 때 CPU RAM 사용량을 줄이려고 할 수 있습니다.
 dhKwang
에 2020년 01월 13일
dhKwang
에 2020년 01월 13일
비슷한 문제가있었습니다.
배치 크기를 줄이고 커널을 다시 시작하면 문제를 해결하는 데 도움이 되었습니다.
 kumarnikhil936
에 2020년 01월 19일
kumarnikhil936
에 2020년 01월 19일
제 경우에는 Adam 옵티마이저를 SGD 옵티마이저로 교체해도 동일한 문제가 해결되었습니다.
 tranvanluan2
에 2020년 01월 23일
tranvanluan2
에 2020년 01월 23일
음, 제 경우에는 with torch.no_grad(): (train model) , output.to("cpu") 및 torch.cuda.empty_cache() 했고 이 문제는 해결되었습니다.
 PlanNoa
에 2020년 01월 30일
PlanNoa
에 2020년 01월 30일
런타임 오류: CUDA 메모리가 부족합니다. 54.00MiB 할당 시도(GPU 0, 3.95GiB 총 용량, 2.65GiB 이미 할당됨, 39.00MiB 여유 공간, 87.29MiB 캐시됨)
솔루션을 찾았고 batch_size 값을 줄였습니다.
 sagrawal06
에 2020년 01월 30일
sagrawal06
에 2020년 01월 30일
사용자 지정 데이터 세트에서 Darknet53 가중치를 사용하여 YOLOv3을 훈련하고 있습니다. 내 GPU는 NVIDIA RTX 2080이고 동일한 문제에 직면했습니다. 배치 크기를 변경하면 해결되었습니다.
 wilderrodrigues
에 2020년 02월 02일
wilderrodrigues
에 2020년 02월 02일
추론 시간 동안 이 오류가 발생합니다....i'm ru
CUDA 메모리가 부족합니다. 102.00MiB 할당 시도(GPU 0, 15.78GiB 총 용량, 14.54GiB 이미 할당됨, 48.44MiB 여유 공간, PyTorch에서 총 14.67GiB 예약)
-------------------------------------------------- ---------------------------+
| NVIDIA-SMI 440.59 드라이버 버전: 440.59 CUDA 버전: 10.2 |
|---------------------------------------------+----------------- --+----------------------+
| GPU 이름 지속성-M| 버스 ID Disp.A | 휘발성 부정확. ECC |
| 팬 온도 성능 Pwr: 사용량/한도 | 메모리 사용량 | GPU 활용 컴퓨팅 M. |
|===================================================== =====+========================|
| 0 Tesla V100-SXM2... 켜기 | 00000000:00:1E.0 끄기 | 0 |
| 해당 없음 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% 기본값 |
+-------------------------------+-------------------- -----+----------------------+
+---------------------------------------------------------------- --------------------------+
| 프로세스: GPU 메모리 |
| GPU PID 유형 프로세스 이름 사용법 |
|=================================================== ==============================|
| 0 13978 C
+---------------------------------------------------------------- --------------------------+
 tvinith
에 2020년 02월 29일
tvinith
에 2020년 02월 29일
데이터의 미니 배치가 GPU 메모리에 맞지 않기 때문입니다. 배치 크기를 줄이면 됩니다. cifar10 데이터 세트에 대해 배치 크기 = 256을 설정할 때 동일한 오류가 발생했습니다. 그런 다음 배치 크기 = 128로 설정하면 해결됩니다.
고마워요, 당신이 옳습니다
 Rxma1805
에 2020년 03월 02일
Rxma1805
에 2020년 03월 02일
GPU 메모리가 충분하지만 여전히 오류가 발생하는 특정 경우입니다. 제 경우에는 데이터 로더의 작업자 수를 줄여서 해결했습니다.
 Yurasyk
에 2020년 03월 14일
Yurasyk
에 2020년 03월 14일
배경
py36, pytorch1.4, tf2.0, 콘다
로베르타 미세 조정
문제
@EMarquer 와 동일한 문제 : pycharm 은 여전히 충분한 메모리가 있지만 메모리 할당에 실패하여 메모리 부족을 보여줍니다.
내가 시도한 방법
- "batch_size = 1" 실패
- "torch.cuda.empty_cache()" 실패
- CUDA_VISIBLE_DEVICES="0" python Run.py 실패
- jupyter를 사용하지 않기 때문에 커널을 다시 시작할 필요가 없습니다.
성공적인 방법
- 엔비디아-smi


- 진실은 pycharm이 표시하는 것이 "nvidia-smi"가 표시하는 것과 다르며(pycharm 사진을 저장하지 않아서 죄송합니다) 실제로 메모리가 충분하지 않다는 것 입니다.
- 프로세스 6123 및 32644는 이전에 터미널에서 실행됩니다.
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
에 2020년 03월 17일
FernandoZhuang
에 2020년 03월 17일
단순히 나를 위해 일한 것 :
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
에 2020년 04월 06일
MastafaF
에 2020년 04월 06일
배치 크기를 조정하지 않고도 이 문제를 해결할 수 있음을 발견했습니다.
터미널 및 파이썬 프롬프트 열기
import torch torch.cuda.empty_cache()Python 인터프리터를 종료하고 원래 PyTorch 명령을 다시 실행하면 CUDA 메모리 오류가 발생하지 않아야 합니다.
내 경우에는 내 문제를 해결합니다.
 LiEAEX
에 2020년 04월 10일
LiEAEX
에 2020년 04월 10일
--device_ids 0과 함께 슬롯 0에서 GPU를 사용하고 있는지 확인하십시오.
나는 용어를 도살하고 있다는 것을 알고 있지만 효과가있었습니다. id를 선택하지 않으면 GPU 대신 CPU를 사용한다고 가정합니다.
 aaron387
에 2020년 04월 12일
aaron387
에 2020년 04월 12일
동일한 오류가 발생합니다.
런타임 오류: CUDA 메모리가 부족합니다. 4.84GiB 할당 시도(GPU 0, 7.44GiB 총 용량, 5.22GiB 이미 할당됨, 1.75GiB 여유 공간, 18.51MiB 캐시됨)
클러스터를 다시 시작하거나 배치 크기를 변경하면 작동합니다. 하지만 이 솔루션이 마음에 들지 않습니다. 나는 심지어 torch.cuda.empty_cache() 를 시도했지만 이것은 나를 위해 작동하지 않습니다. 이것을 해결할 다른 효율적인 방법이 있습니까?
 Tann10
에 2020년 04월 13일
Tann10
에 2020년 04월 13일
내 시나리오가 원래 문제와 관련이 있는지 모르겠지만 내 모델의 nn.Sequential 레이어를 분해하여 문제(이전 메시지의 OOM 오류가 사라졌습니다)를 해결했습니다.
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)에게
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))내 모델에는 이 중 훨씬 더 많은 것이 있습니다(정확히 5개 이상). nn.Sequential을 사용하고 있습니까? 아니면 이것이 버그입니까? @yf225 @fmassa
나도 비슷한 오류를 해결하지만 반대로 당신과 함께 해결하는 것 같습니다.
나는 모두를 바꿉니다
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)에게
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
에 2020년 04월 14일
xml94
에 2020년 04월 14일
나를 위해 batch_size 또는 주어진 솔루션을 변경해도 도움이되지 않았습니다. 그러나 내 .cfg 파일에 잘못된 클래스 값과 한 레이어의 필터가 있는 것으로 나타났습니다. 따라서 아무 것도 도움이 되지 않으면 .cfg를 다시 확인하십시오.
 ulaszewskim
에 2020년 05월 01일
ulaszewskim
에 2020년 05월 01일
터미널 열기
첫 번째 유형
엔비디아-smi
그런 다음 python 또는 anaconda 경로에 해당하는 PID를 선택하고 작성하십시오.
sudo kill -9 PID
 krypticmouse
에 2020년 05월 04일
krypticmouse
에 2020년 05월 04일
나는이 버그를 한동안 겪었습니다. 저에게는 모델 결과를 참조하는 python 변수(예: 토치 텐서)를 계속 보유하고 있으므로 코드가 여전히 액세스할 수 있으므로 안전하게 해제할 수 없습니다.
내 코드는 다음과 같습니다.
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
이에 대한 수정은 p 를 목록으로 전송하는 것이었습니다. 따라서 코드는 다음과 같아야 합니다.
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
이렇게 하면 predictions 가 GPU의 텐서가 아니라 주 메모리에 값을 유지합니다.
 abdelrahmanhosny
에 2020년 05월 08일
abdelrahmanhosny
에 2020년 05월 08일
pytorch에 의존하는 fastai.vision 모듈을 사용하여 이 버그가 있습니다. 나는 CUDA 10.1을 사용하고 있습니다
 jkomyno
에 2020년 05월 16일
jkomyno
에 2020년 05월 16일
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
per_gpu_train_batch_size를 16에서 8로 줄이면 내 문제가 해결되었습니다.
 autodataming
에 2020년 06월 03일
autodataming
에 2020년 06월 03일
최신 버전의 PyTorch로 업데이트하면 이와 같은 오류가 덜 발생할 수 있습니다.
정말, 왜 그렇게 말합니까
 XinyingZheng
에 2020년 06월 09일
XinyingZheng
에 2020년 06월 09일
이 문제의 주요 질문은 여전히 미해결 문제입니다. 동일한 이상한 CUDA 메모리 부족 메시지가 나타납니다. 4.08GiB에 2.26GiB를 무료로 할당하려고 했습니다. 메모리가 충분해 보이지만 할당에 실패합니다.
프로젝트 정보: 배치 크기가 4인 activitynet 데이터 세트를 통해 resnet 10을 훈련하면 첫 번째 epoch의 마지막에서 실패합니다.
편집됨: 일부 인식: RAM 메모리를 청소하고 Python 코드만 계속 실행하면 오류가 발생하지 않습니다. GPU에 충분한 메모리가 있지만 RAM 메모리는 다른 모든 처리 단계를 처리할 수 없습니다.
컴퓨터 정보: Dell G5 - i7 9th - GTX 1660Ti 6GB - 16GB RAM
EDITED2: 4명의 작업자와 함께 "_MultiProcessingDataLoaderIter"를 사용하고 있었는데 전달 호출에서 메모리 부족 메시지가 발생합니다. 작업자 수를 1로 줄이면 오류가 발생하지 않습니다. 작업자가 1인 경우 램 메모리 사용량은 11/16GB로 유지되고 4인 경우 14.5/16GB로 증가합니다. 그리고 실제로 1명의 작업자로 배치 크기를 32로 늘릴 수 있고 GPU 메모리를 3.5GB/6GB로 높일 수 있습니다.
런타임 오류: CUDA 메모리가 부족합니다. 2.26GiB 할당 시도(GPU 0, 6.00GiB 총 용량, 209.63MiB 이미 할당됨, 4.08GiB 여유 공간, PyTorch에서 총 예약 246.00MiB)
전체 오류 메시지
역추적(가장 최근 호출 마지막):
파일 "main.py", 450행,
opt.distributed인 경우:
main_worker의 파일 "main.py", 409행
opt.device, current_lr, train_logger,
"D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\training.py" 파일, 37행, train_epoch
출력 = 모델(입력)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", 532행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py", 150행, 앞으로
반환 self.module( 입력[0], * kwargs[0])
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", 532행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", 205행, 앞으로
x = self.layer3(x)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", 532행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py", 100행, 앞으로
입력 = 모듈(입력)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", 532행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", 51행, 앞으로
out = self.conv2(out)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", 532행, __call__
결과 = self.forward( 입력, * kwargs)
파일 "D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py", 480행, 앞으로
self.padding, self.dilation, self.groups)
런타임 오류: CUDA 메모리가 부족합니다. 2.26GiB 할당 시도(GPU 0, 6.00GiB 총 용량, 209.63MiB 이미 할당됨, 4.08GiB 사용 가능, 246.00MiB 예약됨)
PyTorch에 의해 총계)
 guilhermesurek
에 2020년 06월 12일
guilhermesurek
에 2020년 06월 12일
작은 배치 크기, 작동
 cuge1995
에 2020년 06월 15일
cuge1995
에 2020년 06월 15일
나는이 버그를 한동안 겪었습니다. 저에게는 모델 결과를 참조하는 python 변수(예: 토치 텐서)를 계속 보유하고 있으므로 코드가 여전히 액세스할 수 있으므로 안전하게 해제할 수 없습니다.
내 코드는 다음과 같습니다.
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)이에 대한 수정은
p를 목록으로 전송하는 것이었습니다. 따라서 코드는 다음과 같아야 합니다.predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())이렇게 하면
predictions가 GPU의 텐서가 아니라 주 메모리에 값을 유지합니다.
@abdelrahmanhosny 지적해 주셔서 감사합니다. 나는 PyTorch 1.5.0에서 똑같은 문제에 직면했고 훈련 중에 OOM 문제가 없었지만 추론하는 동안 메모리에 모델 결과를 참조하는 파이썬 변수(예: 토치 텐서)를 계속 유지하여 GPU가 메모리 부족을 초래했습니다. 일정 수의 배치 후.
그러나 제 경우에는 네트워크로 이미지를 생성할 때 예측을 목록으로 전송하는 것이 작동하지 않았으므로 다음을 수행해야 했습니다.
predictions.append(p.detach().cpu().numpy())
그러면 문제가 해결되었습니다!
 samkellerhals
에 2020년 06월 19일
samkellerhals
에 2020년 06월 19일
일반적인 해결책이 있습니까?
CUDA 메모리가 부족합니다. 196.00MiB 할당 시도(GPU 0, 2.00GiB 총 용량, 359.38MiB 이미 할당됨, 192.29MiB 여유 공간, 152.37MiB 캐시됨)
일반적인 해결책이 있습니까?
CUDA 메모리가 부족합니다. 196.00MiB 할당 시도(GPU 0, 2.00GiB 총 용량, 359.38MiB 이미 할당됨, 192.29MiB 여유 공간, 152.37MiB 캐시됨)
 manavkhadka0
에 2020년 06월 24일
manavkhadka0
에 2020년 06월 24일
나는이 버그를 한동안 겪었습니다. 저에게는 모델 결과를 참조하는 python 변수(예: 토치 텐서)를 계속 보유하고 있으므로 코드가 여전히 액세스할 수 있으므로 안전하게 해제할 수 없습니다.
내 코드는 다음과 같습니다.predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)이에 대한 수정은
p를 목록으로 전송하는 것이었습니다. 따라서 코드는 다음과 같아야 합니다.predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())이렇게 하면
predictions가 GPU의 텐서가 아니라 주 메모리에 값을 유지합니다.@abdelrahmanhosny 지적해 주셔서 감사합니다. 나는 PyTorch 1.5.0에서 똑같은 문제에 직면했고 훈련 중에 OOM 문제가 없었지만 추론하는 동안 메모리에 모델 결과를 참조하는 파이썬 변수(예: 토치 텐서)를 계속 유지하여 GPU가 메모리 부족을 초래했습니다. 일정 수의 배치 후.
그러나 제 경우에는 네트워크로 이미지를 생성할 때 예측을 목록으로 전송하는 것이 작동하지 않았으므로 다음을 수행해야 했습니다.
predictions.append(p.detach().cpu().numpy())그러면 문제가 해결되었습니다!
ParallelWaveGAN 모델에서 동일한 문제가 있고 #16417의 솔루션을 사용했지만 작동하지 않습니다.
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
gc.collect()
토치.cuda.empty_cache()
 tuong-olli
에 2020년 06월 25일
tuong-olli
에 2020년 06월 25일
훈련 중에 같은 문제가 발생했습니다.
각 에포크 후에 쓰레기를 수집하고 cuda 메모리를 비우면 문제가 해결되었습니다.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
에 2020년 08월 05일
IsakWesterlundBitville
에 2020년 08월 05일
단순히 나를 위해 일한 것 :
import gc # Your code with pytorch using GPU gc.collect()
감사합니다!! 나는 고양이와 개 예제를 실행하는 데 문제가 있었고 이것이 나를 위해 일했습니다.
 Michelpayan
에 2020년 08월 05일
Michelpayan
에 2020년 08월 05일
훈련 중에 같은 문제가 발생했습니다.
각 에포크 후에 쓰레기를 수집하고 cuda 메모리를 비우면 문제가 해결되었습니다.gc.collect() torch.cuda.empty_cache()
나에게도 마찬가지
 AleksandrTulenkov
에 2020년 08월 06일
AleksandrTulenkov
에 2020년 08월 06일
배치 크기를 줄이고 에포크를 늘립니다. 그것이 내가 해결한 방법입니다.
 oyekamal
에 2020년 09월 18일
oyekamal
에 2020년 09월 18일
@areebsyed 램 메모리를 확인하십시오. 많은 작업자를 병렬로 설정할 때이 문제가 발생했습니다.
guilhermesurek
에 2020년 09월 29일
단일 epoch를 완료하지 않고 Colab의 pytorch에서 사전 훈련된 bert2bert EncoderDecoderModel을 미세 조정하는 동안에도 동일한 오류가 발생합니다.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
에 2020년 10월 06일
Aakash12980
에 2020년 10월 06일
@Aakash12980 배치 크기를
 areebsyed
에 2020년 10월 06일
areebsyed
에 2020년 10월 06일
@areebsyed 예, 배치 크기를 4로 줄였으며 작동했습니다.
Aakash12980
에 2020년 10월 06일
같은
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
에 2020년 10월 07일
monajalal
에 2020년 10월 07일
같은
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal 배치 크기 또는 입력 차원 크기를 줄이십시오.
Aakash12980
에 2020년 10월 07일
그렇다면 아래와 같은 예제의 해결 방법은 무엇입니까(즉, _free_ 메모리가 많고 할당을 거의 시도하지 않음 - 실제로 여유 메모리가 거의 없고 아무 문제가 없을 때 이 스레드의 _some_ 예제와 다릅니다)?
런타임 오류: CUDA 메모리가 부족합니다. 할당 시도 _ 1.33 지브 _ (GPU 1, 31.72 지브 총 용량, 이미 할당 5.68 지브는; _ 24.94 지브 무료 _; 5.96 MIB는 캐시)
최신 pytorch 버전(1.2) 및 최신 NVIDIA GPU(V-100)에서 여전히 발생하므로 문제가 '닫힘' 상태로 전환된 이유를 모르겠습니다.
감사 해요!
예, 대부분의 사람들이 문제가 단순히 OOM이 아니라 OOM이 있다는 것을 깨닫지 못하는 것 같습니다. 오류에는 여유 공간이 충분하다는 오류가 표시됩니다. Windows에서도 이 문제에 직면하고 있습니다. 해결책을 찾으셨습니까?
 YoadTew
에 2020년 11월 06일
YoadTew
에 2020년 11월 06일
관련 문제
 eliabruni
·
3코멘트
eliabruni
·
3코멘트
 kdexd
·
3코멘트
kdexd
·
3코멘트
 dablyo
·
3코멘트
dablyo
·
3코멘트
 szagoruyko
·
3코멘트
szagoruyko
·
3코멘트
 Coderx7
·
3코멘트
Coderx7
·
3코멘트
가장 유용한 댓글
데이터의 미니 배치가 GPU 메모리에 맞지 않기 때문입니다. 배치 크기를 줄이면 됩니다. cifar10 데이터 세트에 대해 배치 크기 = 256을 설정할 때 동일한 오류가 발생했습니다. 그런 다음 배치 크기 = 128로 설정하면 해결됩니다.