Pytorch: RuntimeError:CUDAのメモリが不足しています。 12.50 MiBを割り当てようとしました(GPU 0、10.92GiBの合計容量; 8.57MiBはすでに割り当てられています; 9.28GiBは無料です; 4.68 MiBはキャッシュされています)
CUDAのメモリ不足エラーですが、CUDAメモリがほとんど空です
私は現在、非常に大量のテキストデータ(約70GiBのテキスト)で軽量モデルをトレーニングしています。
そのために、私はクラスター上のマシンを使用しています( grid5000クラスターネットワークの「grele」 )。
この非常に奇妙なCUDAOut of Memoryエラーメッセージを3時間トレーニングした後、次のメッセージが表示されます。
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) 。
メッセージによると、必要なスペースはありますが、メモリが割り当てられていません。
これを引き起こす可能性のあるアイデアはありますか?
詳細については、前処理はtorch.multiprocessing.Queueと、ソースデータの行に対するイテレータに依存して、データをその場で前処理します。
完全なスタックトレース
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
全てのコメント91件
同じランタイムエラーがあります:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
2019年01月27日
OmarBazaraa
2019年01月27日
@ EMarquer @ OmarBazaraa実行できる最小限の再現例を
 yf225
2019年01月28日
yf225
2019年01月28日
問題を再現できなくなったため、問題を解決します。
前処理されたデータをRAMに保存するのをやめると、問題は解消されました。
@OmarBazaraa 、私はあなたの問題が私のものと同じではないと思います:
- 12.50 MiBを割り当てようとしていますが、9.28GiBは無料です
- 195.25 MiBを割り当てようとしていますが、170.14MiBは無料です
この問題に関する私の以前の経験から、CUDAメモリを解放しないか、CUDAに大量のデータを入れようとします。
CUDAメモリを解放しないということは、もう使用しないCUDAのテンソルへの参照がまだ残っている可能性があることを意味します。 それらは、テンソルを削除することによって割り当てられたメモリが解放されるのを防ぎます。
EMarquer
2019年01月28日
一般的な解決策はありますか?
CUDAのメモリが不足しています。 196.00 MiBを割り当てようとしました(GPU 0、合計容量2.00 GiB、すでに割り当てられている359.38 MiB、空き192.29 MiB、キャッシュされている152.37 MiB)
 aniketspurohit
2019年01月31日
aniketspurohit
2019年01月31日
@ aniks23この場合、より良いエクスペリエンスが得られると私が信じているパッチに取り組んでいます。 乞うご期待
 fmassa
2019年01月31日
fmassa
2019年01月31日
私のシステムが処理できるモデルまたはネットワークの大きさを知る方法はありますか?
この問題に遭遇することなく?
2019年2月1日金曜日午前3時55分フランシスコマッサ[email protected]
書きました:
@ aniks23https ://github.com/aniks23私たちはパッチに取り組んでい
この場合、より良い経験が得られると信じています。 乞うご期待—
あなたが言及されたのであなたはこれを受け取っています。
このメールに直接返信し、GitHubで表示してください
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 、
またはスレッドをミュートします
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
。
aniketspurohit
2019年02月01日
私もこのメッセージを受け取りました:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Fast.ai lesson1 Pets https://course.fast.ai/ (セル31)を実行しようとしたときに発生しました
 adrianovieira
2019年03月12日
adrianovieira
2019年03月12日
私も同じエラーに遭遇しています。 私のモデルは以前は正確なセットアップで動作していましたが、一見無関係に見えるコードを変更した後、このエラーが発生します。
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
2019年03月14日
treble-maker123
2019年03月14日
シナリオが元の問題に関連しているかどうかはわかりませんが、モデルのnn.Sequentialレイヤーを分割することで、問題を解決しました(前のメッセージのOOMエラーはなくなりました)。
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
に
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
私のモデルにはこれらがもっとたくさんあります(正確にはさらに5つ)。 nn.Sequential rightを使用していますか? それともこれはバグですか? @ yf225 @fmassa
treble-maker123
2019年03月14日
同様のエラーが発生します:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@ treble-maker123、nn.Sequentialが問題であることを最終的に証明できましたか?
 yasheshgaur
2019年03月17日
yasheshgaur
2019年03月17日
同様の問題が発生しています。 pytorchデータローダーを使用しています。 5 Gb以上の空き容量があるはずですが、0バイトの空き容量があります。
RuntimeErrorトレースバック(最後の最後の呼び出し)
22
23データ、入力= states_inputs
---> 24データ、入力= Variable(data).float()。to(device)、Variable(inputs).float()。to(device)
25 print(data.device)
26 enc_out =エンコーダー(データ)
RuntimeError:CUDAのメモリが不足しています。 11.00 MiBを割り当てようとしました(GPU 0、合計容量6.00 GiB、すでに割り当てられている448.58 MiB、空き0バイト、キャッシュされた942.00 KiB)
 ahsteven
2019年04月03日
ahsteven
2019年04月03日
こんにちは、私もこのエラーが発生しました。
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
2019年04月17日
AlbertZhangHIT
2019年04月17日
悲しいことに、私も同じ問題に遭遇しました。
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
サーバーのクラスターでモデルをトレーニングしましたが、サーバーの1つで予期しないエラーが発生しました。 また、このような有線エラーは、私のトレーニング戦略の1つでのみ発生します。 唯一の違いは、データ拡張中にコードを
 qingyu-wang
2019年04月25日
qingyu-wang
2019年04月25日
私もこの問題を抱えています。 それを解決する方法??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
2019年05月10日
nabil2i
2019年05月10日
ここで同じ問題RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
2019年05月16日
williamluke4
2019年05月16日
@fmassaこれについてもっと情報がありますか?
williamluke4
2019年05月18日
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
私にとって同じ問題
親愛なる、あなたは解決策を得ましたか?
(ベース)F:\ Suresh \ st-gcn> pythonmain1.py認識-cconfig / st_gcn / ntu-xsub / train.yaml --device 0 --work_dir ./work_dir
C:\ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ cuda__init __。py:117:UserWarning:
cuda機能1.1のGPU0TITANXpが見つかりました。
PyTorchは古すぎるため、このGPUをサポートしなくなりました。
warnings.warn(old_gpu_warn%(d、name、major、capability [1]))
[05.22.19 | 12:02:41]パラメーター:
{'base_lr':0.1、 'ignore_weights':[]、 'model': 'net.st_gcn.Model'、 'eval_interval':5、 'weight_decay':0.0001、 'work_dir': './ work_dir'、 'save_interval ':10、' model_args ':{' in_channels ':3、' dropout ':0.5、' num_class ':60、' edge_importance_weighting ':True、' graph_args ':{' strategy ':' Spatial '、' layout ': 'ntu-rgb + d'}}、 'debug':False、 'pavi_log':False、 'save_result':False、 'config': 'config / st_gcn / ntu-xsub / train.yaml'、 'optimizer': 'SGD'、 '重み':なし、 'num_epoch':80、 'batch_size':64、 'show_topk':[1、5]、 'test_batch_size':64、 'ステップ':[10、50]、 'use_gpu ':True、'フェーズ ':' train '、' print_log ':True、' log_interval ':100、' feeder ':' feeder.feeder.Feeder '、' start_epoch ':0、' nesterov ':True、' device ':[0]、' save_log ':True、' test_feeder_args ':{' data_path ':' ./data/NTU-RGB-D/xsub/val_data.npy '、' label_path ':' ./data/NTU- RGB-D / xsub / val_label.pkl '}、' train_feeder_args ':{' data_path ':' ./data/NTU-RGB-D/xsub/train_data.npy '、' debug ':False、' label_path ':' ./data/NTU-RGB-D/xsub/train_l abel.pkl '}、' num_worker ':4}
[05.22.19 | 12:02:41]トレーニングエポック:0
トレースバック(最後の最後の呼び出し):
ファイル "main1.py"、行31、
p.start()
ファイル「F:\ Suresh \ st-gcn \ processor \ processor.py」、113行目、開始時
self.train()
電車内のファイル「F:\ Suresh \ st-gcn \ processor \ recognition.py」、91行目
出力= self.model(data)
ファイル "C:\ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py"、行489、__ call__
結果= self.forward( input、* kwargs)
ファイル "F:\ Suresh \ st-gcn \ net \ st_gcn.py"、82行目、前方
x、_ = gcn(x、self.A *重要度)
ファイル "C:\ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py"、行489、__ call__
結果= self.forward( input、* kwargs)
ファイル "F:\ Suresh \ st-gcn \ net \ st_gcn.py"、行194、前方
x、A = self.gcn(x、A)
ファイル "C:\ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py"、行489、__ call__
結果= self.forward( input、* kwargs)
ファイル「F:\ Suresh \ st-gcn \ net \ utils \ tgcn.py」、60行目、前方
x = self.conv(x)
ファイル "C:\ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py"、行489、__ call__
結果= self.forward( input、* kwargs)
ファイル "C:\ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ conv.py"、行320、前方
self.padding、self.dilation、self.groups)
RuntimeError:CUDAのメモリが不足しています。 1.37 GiBを割り当てようとしました(GPU 0、合計容量12.00 GiB、すでに割り当てられている8.28 GiB、空き652.75 MiB、キャッシュされた664.38 MiB)
 Sureshthommandru
2019年05月22日
Sureshthommandru
2019年05月22日
これは、データのミニバッチがGPUメモリに収まらないためです。 バッチサイズを小さくするだけです。 cifar10データセットのバッチサイズを256に設定すると、同じエラーが発生しました。 次に、バッチサイズを128に設定すると、解決されます。
 balcilar
2019年06月01日
balcilar
2019年06月01日
ええ@balcilarは正しいです、私はバッチサイズを減らしました、そして今それは働きます
 EKELE-NNOROM
2019年06月04日
EKELE-NNOROM
2019年06月04日
私は同様の問題を抱えています:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
モデルのトレーニングに8V100を使用しています。 紛らわしいのは、3.03GBがまだキャッシュされており、11.88MBに割り当てることができないことです。
 magic282
2019年06月10日
magic282
2019年06月10日
バッチサイズを変更しましたか。 バッチサイズを半分に減らします。 バッチを言う
実装するサイズは16です。バッチサイズ8を使用してみて、機能するかどうかを確認してください。
楽しみ
2:10で月、2019年6月10日にmagic282 [email protected]書きました:
私は同様の問題を抱えています:
RuntimeError:CUDAのメモリが不足しています。 11.88 MiBを割り当てようとしました(GPU 4、合計容量15.75 GiB、すでに割り当てられている10.50 GiB、空き1.88 MiB、キャッシュされている3.03 GiB)
モデルのトレーニングに8V100を使用しています。 紛らわしい部分はあるということです
まだ3.03GBがキャッシュされており、11.88MBに割り当てることはできません。—
あなたがコメントしたのであなたはこれを受け取っています。
このメールに直接返信し、GitHubで表示してください
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKT
またはスレッドをミュートします
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
。
EKELE-NNOROM
2019年06月10日
バッチサイズを小さくしてみましたが、うまくいきました。 紛らわしい部分は、キャッシュされたメモリが割り当てられるメモリよりも大きいというエラーメッセージです。
magic282
2019年06月11日
予測を使用
 pvk444
2019年06月30日
pvk444
2019年06月30日
PyTorchの最新バージョンに更新すると、そのようなエラーが少なくなる可能性があります
fmassa
2019年06月30日
エラーの数値が合計されない理由を尋ねることはできますか?!
私は(あなた方全員のように)得ます:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
私にとって、それは次のことがほぼ真実であるべきであることを意味します:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
そうではありません。 私が間違っているのは何ですか?
 AzimAhmadzadeh
2019年07月03日
AzimAhmadzadeh
2019年07月03日
U-netをトレーニングしたときにも問題が発生しました。cachで十分ですが、それでもクラッシュします。
 tongpinmo
2019年07月10日
tongpinmo
2019年07月10日
同じエラーが発生します...
RuntimeError:CUDAのメモリが不足しています。 312.00 MiBを割り当てようとしました(GPU 0、10.91GiBの合計容量; 1.07GiBはすでに割り当てられています; 109.62MiBは無料です; 15.21 MiBはキャッシュされています)
 MSKazemi
2019年07月10日
MSKazemi
2019年07月10日
サイズを小さくしてみてください(結果を変更しない任意のサイズ)が機能します。
 giangnguyen2412
2019年07月11日
giangnguyen2412
2019年07月11日
サイズを小さくしてみてください(結果を変更しない任意のサイズ)が機能します。
こんにちは、batch_sizeを1に変更しましたが、機能しません!
 BCWang93
2019年07月14日
BCWang93
2019年07月14日
別のサイズに変更していただけますか。
VAO 21時50分、CN、14 TH7、2019 Bcw93 [email protected] DJA VIET:
サイズを小さくしてみてください(結果を変更しない任意のサイズ)が機能します。
こんにちは、batch_sizeを1に変更しましたが、機能しません!
—
あなたがコメントしたのであなたはこれを受け取っています。
このメールに直接返信し、GitHubで表示してください
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5
またはスレッドをミュートします
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
。
giangnguyen2412
2019年07月15日
このエラーの取得:
RuntimeError:CUDAのメモリが不足しています。 2.00 MiBを割り当てようとしました(GPU 0、7.94GiBの合計容量; 7.33GiBはすでに割り当てられています; 1.12MiBは空き、40.48 MiBはキャッシュされています)
nvidia-smi
2019年8月22日木曜日21:05:52
+ ------------------------------------------------- ---------------------------- +
| NVIDIA-SMI 430.40ドライバーバージョン:430.40 CUDAバージョン:10.1 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| GPU名の永続性-M | Bus-Id Disp.A | 揮発性のUncorr。 ECC |
| ファン温度パフォーマンス電源:使用法/キャップ| メモリ-使用法| GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 QuadroM4000オフ| 00000000:09:00.0オン| 該当なし|
| 46%37C P8 12W / 120W | 71MiB / 8126MiB | 10%デフォルト|
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1 GeForce GTX 105 ...オフ| 00000000:41:00.0オン| 該当なし|
| 29%33C P8 N / A / 75W | 262MiB / 4032MiB | 0%デフォルト|
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| プロセス:GPUメモリ|
| GPUPIDタイププロセス名使用法|
| ================================================= ============================ |
| 0 1909 G / usr / lib / xorg / Xorg 50MiB |
| 1 1909 G / usr / lib / xorg / Xorg 128MiB |
| 1 5236 G ... quest-channel-token = 9884100064965360199 130MiB |
+ ------------------------------------------------- ---------------------------- +
OS:Ubuntu 18.04 bionic
カーネル:x86_64 Linux4.15.0-58-汎用
稼働時間:29分
パッケージ:2002
シェル:bash 4.4.20
解像度:1920x1080 1080x1920
DE:LXDE
WM:OpenBox
GTKテーマ:Lubuntu-デフォルト[GTK2]
アイコンテーマ:Lubuntu
フォント:Ubuntu 11
CPU:AMD Ryzen Threadripper 2970WX24コア@ 48x 3GHz [61.8°C]
GPU:Quadro M4000、GeForce GTX 1050 Ti
RAM:3194MiB / 64345MiB
 danindiana
2019年08月23日
danindiana
2019年08月23日
これは修正されていますか? サイズとバッチサイズの両方を1に減らしました。ここに他の解決策はありませんが、このチケットはクローズされています。 Cuda 10.1 Windows 10、Pytorch1.2.0でも同じ問題が発生しています
 hughkf
2019年09月06日
hughkf
2019年09月06日
@hughkfコードのどこでbatch_sizeを変更しますか?
 aidoshacks
2019年09月06日
aidoshacks
2019年09月06日
@aidoshacks 、それはあなたのコードに依存します。 しかし、ここに一例があります。 これは、私のマシンでこの問題を確実に引き起こすノートブックの1つです: https :
bs,size = 8,src_size//2からbs,size = 1,1が、それでもメモリ不足の問題が発生します。
hughkf
2019年09月06日
私にとって、batch_sizeを128から64に変更することは機能しましたが、それは私にとって開示された解決策のようには見えません、または私は何かが欠けていますか?
 shalgi
2019年09月19日
shalgi
2019年09月19日
この問題は解決しましたか? 私も同じ問題を抱えていました。 コードを何も変更しませんでしたが、何度も実行した後、次のエラーが発生します。
"RuntimeError:CUDA outofmemory。40.00MiBを割り当てようとしました(GPU 0; 15.77GiBの合計容量; 13.97GiBはすでに割り当てられています; 256.00KiBは空きです; 824.57 MiBはキャッシュされています)"
 mengxiangming
2019年09月26日
mengxiangming
2019年09月26日
まだこの問題が発生しているので、ステータスが未解決に変更されると便利です。
編集:
バッチサイズ1で取得したので、バッチサイズとはほとんど関係がありませんでした。カーネルを再起動すると修正されましたが、それ以降は発生していません。
 just-in-kees
2019年09月29日
just-in-kees
2019年09月29日
では、以下のような例の解決策は何ですか(つまり、空きメモリが多く、割り当てをほとんど行わないようにしています。これは、実際にいくつかの例とは異なります)。
RuntimeError:CUDAのメモリが不足しています。 1.33 GiBを割り当てようとしました(GPU 1、31.72GiBの合計容量; 5.68GiBはすでに割り当てられています; 24.94GiBは無料です; 5.96 MiBはキャッシュされています)
最新のpytorchver(1.2)と最新のNVIDIA GPU(V-100)でも引き続き発生するため、問題が「クローズ」ステータスになった理由がわかりません。
ありがとう!
 yuribd
2019年10月03日
yuribd
2019年10月03日
ほとんどの場合、fastaiパッケージからこの特定のエラーメッセージが表示されるのは、非常に小さいGPUを使用しているためです。 カーネルを再起動し、指定するパスに小さいバッチサイズを使用することで、この問題を修正しました。
 AurioPinto
2019年10月05日
AurioPinto
2019年10月05日
ここで同じ問題。 pytorch0.4.1、バッチサイズ= 4を使用すると、問題ありません。 しかし、pytorch1.3に変更し、バッチサイズを1に設定すると、oomの問題が発生します。
 Sarah20187
2019年10月21日
Sarah20187
2019年10月21日
私のpytorchを最新のものに更新することでそれを解決しました... conda update pytorch
 kafura0
2019年10月21日
kafura0
2019年10月21日
これは、データのミニバッチがGPUメモリに収まらないためです。 バッチサイズを小さくするだけです。 cifar10データセットのバッチサイズを256に設定すると、同じエラーが発生しました。 次に、バッチサイズを128に設定すると、解決されます。
おかげで、私はこの方法でエラーに対処しました。
 zhangzibao
2019年10月25日
zhangzibao
2019年10月25日
batch_sizeを8に減らしましたが、正常に機能します。 アイデアは小さなbatch_sizeを持つことです
 Asutosh11
2019年10月30日
Asutosh11
2019年10月30日
特定のレイヤーが処理している合計入力サイズに依存すると思います。 たとえば、256(32x32)画像のバッチがレイヤー内の128のフィルターを通過する場合、合計入力サイズは256x32x32x128 = 2 ^ 25です。 この数値は、マシン固有のしきい値を下回っている必要があります。 たとえば、AWS p3.2xlargeの場合、2 ^ 26です。 したがって、CuDAメモリエラーが発生した場合は、バッチサイズまたはフィルターの数を減らすか、ストライドレイヤーやプールレイヤーなどのダウンサンプリングを増やしてみてください
 souryadey
2019年11月01日
souryadey
2019年11月01日
同じ問題があります:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
最新のpytorch(1.3)およびcuda(10.1)バージョンを使用。 Nvidia-smiは半分空のGPUも表示するため、エラーメッセージの空きメモリの量は正しいです。 まだ簡単なコードでは再現できません
 ArgentumWalker
2019年11月03日
ArgentumWalker
2019年11月03日
カーネルのリセットも私にとってはうまくいきました! それを行うまで、バッチサイズ= 1でも機能しませんでした
 kennethjmyers
2019年11月07日
kennethjmyers
2019年11月07日
みんな、バッチサイズを半分に減らすという問題を解決しました。
 faizao
2019年11月19日
faizao
2019年11月19日
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
再起動後に修正されました
 SomeUserName1
2019年11月22日
SomeUserName1
2019年11月22日
batch_size 64(rtx2080 ti)を32(rtx 2060)に変更し、問題を解決しました。 しかし、私はこの種の問題を解決する他の方法を知りたいです。
 sailfish009
2019年12月03日
sailfish009
2019年12月03日
私が予測をするとき、これは私に起こっています!
バッチサイズを1024から8に変更しましたが、テストセットの82%が評価されたときにエラーが発生します。
with torch.no_grad()を追加すると、問題は解決しました。
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
2019年12月17日
smasoudn
2019年12月17日
私は問題を解決しました
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
にloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
2019年12月27日
zhonghaochen
2019年12月27日
同じ問題が発生し、マシンのGPU使用率を確認しました。 すでに多く使用されており、メモリの残りは非常に少なくなっています。 jupyterノートブックを強制終了して再起動しました。 メモリが解放され、物事が機能し始めました。 以下を使用できます。
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
2019年12月27日
prabhatsharma
2019年12月27日
私もこのメッセージを受け取りました:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Fast.ai lesson1 Pets https://course.fast.ai/ (セル31)を実行しようとしたときに発生しました
トレーニングデータのバッチサイズ(bs)を減らすようにしてください。
何があなたのために働くかを見てください。
 rishi0904
2019年12月27日
rishi0904
2019年12月27日
この問題は、バッチサイズを調整しなくても解決できることがわかりました。
ターミナルとPythonプロンプトを開く
import torch
torch.cuda.empty_cache()
Pythonインタープリターを終了し、元のPyTorchコマンドを再実行すると、(うまくいけば)CUDAメモリエラーが発生しないはずです。
 cpoptic
2020年01月03日
cpoptic
2020年01月03日
私のコンピュータがCPURAMを使いすぎると、通常この問題が発生することがわかりました。 したがって、より大きなバッチサイズが必要な場合は、CPURAMの使用量を減らすことができます。
 dhKwang
2020年01月13日
dhKwang
2020年01月13日
同様の問題がありました。
バッチサイズを減らしてカーネルを再起動すると、問題の解決に役立ちました。
 kumarnikhil936
2020年01月19日
kumarnikhil936
2020年01月19日
私の場合、AdamオプティマイザーをSGDオプティマイザーに置き換えると同じ問題が解決しました。
 tranvanluan2
2020年01月23日
tranvanluan2
2020年01月23日
さて、私の場合、 with torch.no_grad(): (train model) 、 output.to("cpu") 、 torch.cuda.empty_cache() 、この問題は解決しました。
 PlanNoa
2020年01月30日
PlanNoa
2020年01月30日
RuntimeError:CUDAのメモリが不足しています。 54.00 MiBを割り当てようとしました(GPU 0、3.95GiBの合計容量; 2.65GiBはすでに割り当てられています; 39.00MiBは無料です; 87.29 MiBはキャッシュされています)
解決策を見つけ、batch_sizeの値を減らしました。
 sagrawal06
2020年01月30日
sagrawal06
2020年01月30日
カスタムデータセットでDarknet53ウェイトを使用してYOLOv3をトレーニングしています。 私のGPUはNVIDIARTX 2080であり、同じ問題に直面していました。 バッチサイズを変更すると解決しました。
 wilderrodrigues
2020年02月02日
wilderrodrigues
2020年02月02日
推論時間中にこのエラーが発生します....私はruです
CUDAのメモリが不足しています。 102.00 MiBを割り当てようとしました(GPU 0、15.78GiBの合計容量; 14.54GiBはすでに割り当てられています; 48.44MiBは無料です; 14.67 GiBはPyTorchによって合計で予約されています)
-------------------------------------------------- --------------------------- +
| NVIDIA-SMI 440.59ドライバーバージョン:440.59 CUDAバージョン:10.2 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| GPU名の永続性-M | Bus-Id Disp.A | 揮発性のUncorr。 ECC |
| ファン温度パフォーマンス電源:使用法/キャップ| メモリ-使用法| GPU-Util Compute M. |
| =============================== + ================= ===== + ====================== |
| 0 Tesla V100-SXM2 ...オン| 0000000:00:1E.0オフ| 0 |
| 該当なし35CP0 41W / 300W | 16112MiB / 16160MiB | 0%デフォルト|
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| プロセス:GPUメモリ|
| GPUPIDタイププロセス名使用法|
| ================================================= ============================ |
| 0 13978 C /.conda/envs/ / bin / python 16101MiB |
+ ------------------------------------------------- ---------------------------- +
 tvinith
2020年02月29日
tvinith
2020年02月29日
これは、データのミニバッチがGPUメモリに収まらないためです。 バッチサイズを小さくするだけです。 cifar10データセットのバッチサイズを256に設定すると、同じエラーが発生しました。 次に、バッチサイズを128に設定すると、解決されます。
ありがとう、あなたは正しい
 Rxma1805
2020年03月02日
Rxma1805
2020年03月02日
十分なGPUメモリがあるが、それでもエラーがスローされる特定のケース。 私の場合、データローダーのワーカー数を減らすことで解決しました。
 Yurasyk
2020年03月14日
Yurasyk
2020年03月14日
バックグラウンド
py36、pytorch1.4、tf2.0、conda
ロベルタを微調整する
問題
@EMarquerと同じ問題: pycharmは、まだ十分なメモリがあることを示していますが、メモリの割り当てに失敗し、メモリが不足しています。
私が試した方法
- 「batch_size = 1」が失敗しました
- 「torch.cuda.empty_cache()」が失敗しました
- CUDA_VISIBLE_DEVICES = "0" pythonRun.pyが失敗しました
- 私はjupyterを使用していないので、カーネルを再起動する必要はありません
成功する方法
- nvidia-smi


- 真実は、pycharmが表示するものは「nvidia-smi」が表示するものとは異なり(申し訳ありませんが、pycharmの写真を保存しませんでした)、実際には十分なメモリがありません。
- プロセス6123および32644は、以前は端末で実行されていました。
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
2020年03月17日
FernandoZhuang
2020年03月17日
単に私のために働いたもの:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
2020年04月06日
MastafaF
2020年04月06日
この問題は、バッチサイズを調整しなくても解決できることがわかりました。
ターミナルとPythonプロンプトを開く
import torch torch.cuda.empty_cache()Pythonインタープリターを終了し、元のPyTorchコマンドを再実行すると、(うまくいけば)CUDAメモリエラーが発生しないはずです。
私の場合、それは私の問題を解決します。
 LiEAEX
2020年04月10日
LiEAEX
2020年04月10日
--device_ids0を使用してスロット0でGPUを使用していることを確認してください
私は用語を精肉することを知っていますが、それはうまくいきました。 IDを選択しない場合は、GPUではなくCPUを使用することを前提としています。
 aaron387
2020年04月12日
aaron387
2020年04月12日
同じエラーが発生します:
RuntimeError:CUDAのメモリが不足しています。 4.84 GiBを割り当てようとしました(GPU 0、7.44GiBの合計容量; 5.22GiBはすでに割り当てられています; 1.75GiBは空き、18.51 MiBはキャッシュされています)
クラスタを再起動するか、バッチサイズを変更すると、機能します。 しかし、私はこの解決策が好きではありません。 torch.cuda.empty_cache()を試しましたが、これは機能しません。 これを解決する他の効率的な方法はありますか?
 Tann10
2020年04月13日
Tann10
2020年04月13日
シナリオが元の問題に関連しているかどうかはわかりませんが、モデルのnn.Sequentialレイヤーを分割することで、問題を解決しました(前のメッセージのOOMエラーはなくなりました)。
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)に
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))私のモデルにはこれらがもっとたくさんあります(正確にはさらに5つ)。 nn.Sequential rightを使用していますか? それともこれはバグですか? @ yf225 @fmassa
私も同様のエラーを解決しているようですが、あなたとは会話を交わしています。
私はすべてを変更します
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)に
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
2020年04月14日
xml94
2020年04月14日
私にとって、batch_sizeまたは特定のソリューションのいずれかを変更しても役に立ちませんでした。 しかし、私の.cfgファイルでは、1つのレイヤーでクラスとフィルターの値が間違っていたことが判明しました。 したがって、何も役に立たない場合は、.cfgを再確認してください。
 ulaszewskim
2020年05月01日
ulaszewskim
2020年05月01日
オープンターミナル
最初のタイプ
nvidia-smi
次に、pythonまたはanacondaパスに対応するPIDを選択し、次のように記述します。
sudo kill -9 PID
 krypticmouse
2020年05月04日
krypticmouse
2020年05月04日
私はしばらくの間このバグを抱えています。 私の場合、モデルの結果を参照するPython変数(つまり、トーチテンソル)を保持し続けていることがわかりました。そのため、コードが引き続きアクセスできるため、安全に解放できません。
私のコードは次のようになります。
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
これに対する修正は、 pをリストに転送すること
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
これにより、 predictionsがGPUのテンソルではなく、メインメモリに値を保持することが保証されます。
 abdelrahmanhosny
2020年05月08日
abdelrahmanhosny
2020年05月08日
pytorchに依存するfastai.visionモジュールを使用してこのバグが発生しています。 CUDA10.1を使用しています
 jkomyno
2020年05月16日
jkomyno
2020年05月16日
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
per_gpu_train_batch_sizeを16から8に減らして、問題を解決しました。
 autodataming
2020年06月03日
autodataming
2020年06月03日
PyTorchの最新バージョンに更新すると、そのようなエラーが少なくなる可能性があります
本当に、なぜあなたはそれを言うのですか
 XinyingZheng
2020年06月09日
XinyingZheng
2020年06月09日
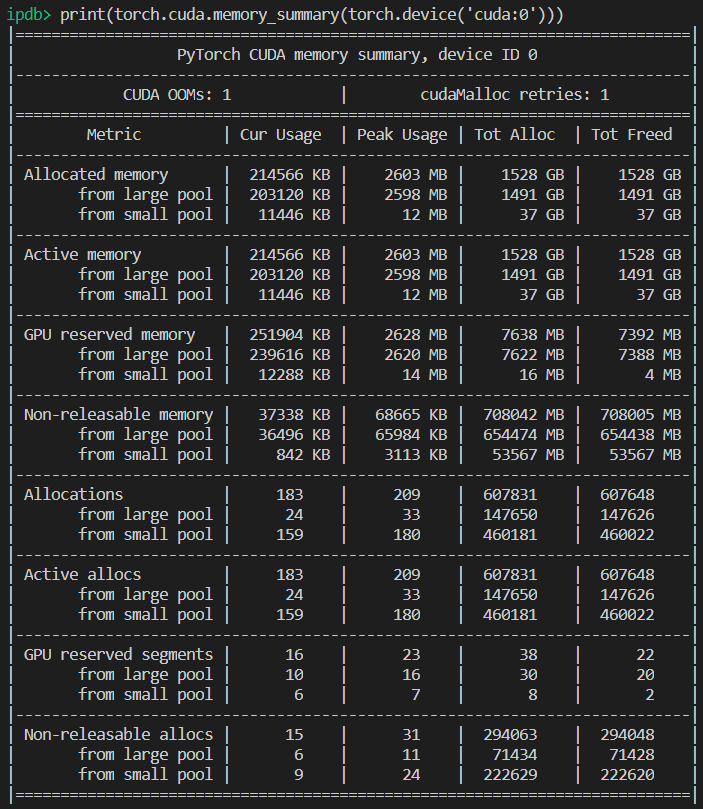
この問題の主な問題は、未解決の問題です。 同じ奇妙なCUDAのメモリ不足メッセージが表示されます。 4.08GiBで2.26GiBを無料で割り当てようとしました。 十分なメモリがあるようですが、割り当てに失敗します。
プロジェクト情報:バッチサイズ4のアクティビティネットデータセットを介してresnet 10をトレーニングすると、最初のエポックの最終で失敗します。
編集:いくつかの認識:RAMメモリをクリーンアップし、Pythonコードのみを実行し続けても、エラーは発生しません。 GPUには十分なメモリがあるかもしれませんが、RAMメモリは他のすべての処理ステップを処理できません。
コンピュータ情報:Dell G5-i7 9th-GTX 1660Ti 6GB-16 GB RAM
EDITED2:4つのワーカーで「_MultiProcessingDataLoaderIter」を使用していましたが、転送呼び出しでメモリ不足のメッセージが発生します。 ワーカーの数を1に減らしても、エラーは発生しません。 1人のワーカーの場合、RAMメモリの使用量は11 / 16GBのままで、4人の場合は14.5 / 16GBに増加します。 そして、たった1人のワーカーで、実際には、バッチサイズを32に増やし、GPUメモリを3.5GB / 6GBに増やすことができます。
RuntimeError:CUDAのメモリが不足しています。 2.26 GiBを割り当てようとしました(GPU 0、6.00GiBの合計容量; 209.63 MiBはすでに割り当てられています、4.08 GiBは無料、246.00 MiBはPyTorchによって合計で予約されています)
エラーメッセージ全体
トレースバック(最後の最後の呼び出し):
ファイル "main.py"、行450、
opt.distributedの場合:
main_workerのファイル "main.py"、行409
opt.device、current_lr、train_logger、
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ training.py」、37行目、train_epoch
出力=モデル(入力)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py」、532行目、__ call__
結果= self.forward( input、* kwargs)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nnparallel \ data_parallel.py」、行150、前方
self.module( inputs [0]、* kwargs [0])を返します
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py」、532行目、__ call__
結果= self.forward( input、* kwargs)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py」、205行目、前方
x = self.layer3(x)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py」、532行目、__ call__
結果= self.forward( input、* kwargs)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ container.py」、100行目、前方
入力=モジュール(入力)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py」、532行目、__ call__
結果= self.forward( input、* kwargs)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py」、51行目、前方
out = self.conv2(out)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py」、532行目、__ call__
結果= self.forward( input、* kwargs)
ファイル「D:\ Guilherme \ GoogleDrive \ Professional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ conv.py」、480行目
self.padding、self.dilation、self.groups)
RuntimeError:CUDAのメモリが不足しています。 2.26 GiBを割り当てようとしました(GPU 0、6.00GiBの合計容量; 209.63MiBはすでに割り当てられています; 4.08GiBは無料です; 246.00MiBは予約済みです
PyTorchによる合計)
 guilhermesurek
2020年06月12日
guilhermesurek
2020年06月12日
バッチサイズが小さい場合は機能します
 cuge1995
2020年06月15日
cuge1995
2020年06月15日
私はしばらくの間このバグを抱えています。 私の場合、モデルの結果を参照するPython変数(つまり、トーチテンソル)を保持し続けていることがわかりました。そのため、コードが引き続きアクセスできるため、安全に解放できません。
私のコードは次のようになります。
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)これに対する修正は、
pをリストに転送することpredictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())これにより、
predictionsがGPUのテンソルではなく、メインメモリに値を保持することが保証されます。
@abdelrahmanhosnyこれを指摘してくれてありがとう。 PyTorch 1.5.0でまったく同じ問題に直面し、トレーニング中にOOMの問題は発生しませんでしたが、推論中に、モデルの結果を参照するpython変数(つまりトーチテンソル)をメモリに保持し続けたため、GPUのメモリが不足しました一定数のバッチの後。
ただし、私の場合、ネットワークで画像を生成しているため、予測をリストに転送することはできませんでした。そのため、次のことを行う必要がありました。
predictions.append(p.detach().cpu().numpy())
これで問題は解決しました!
 samkellerhals
2020年06月19日
samkellerhals
2020年06月19日
一般的な解決策はありますか?
CUDAのメモリが不足しています。 196.00 MiBを割り当てようとしました(GPU 0、合計容量2.00 GiB、すでに割り当てられている359.38 MiB、空き192.29 MiB、キャッシュされている152.37 MiB)
一般的な解決策はありますか?
CUDAのメモリが不足しています。 196.00 MiBを割り当てようとしました(GPU 0、合計容量2.00 GiB、すでに割り当てられている359.38 MiB、空き192.29 MiB、キャッシュされている152.37 MiB)
 manavkhadka0
2020年06月24日
manavkhadka0
2020年06月24日
私はしばらくの間このバグを抱えています。 私の場合、モデルの結果を参照するPython変数(つまり、トーチテンソル)を保持し続けていることがわかりました。そのため、コードが引き続きアクセスできるため、安全に解放できません。
私のコードは次のようになります。predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)これに対する修正は、
pをリストに転送することpredictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())これにより、
predictionsがGPUのテンソルではなく、メインメモリに値を保持することが保証されます。@abdelrahmanhosnyこれを指摘してくれてありがとう。 PyTorch 1.5.0でまったく同じ問題に直面し、トレーニング中にOOMの問題は発生しませんでしたが、推論中に、モデルの結果を参照するpython変数(つまりトーチテンソル)をメモリに保持し続けたため、GPUのメモリが不足しました一定数のバッチの後。
ただし、私の場合、ネットワークで画像を生成しているため、予測をリストに転送することはできませんでした。そのため、次のことを行う必要がありました。
predictions.append(p.detach().cpu().numpy())これで問題は解決しました!
ParrallelWaveGANモデルでも同じ問題があり、#16417のソリューションを使用しましたが、機能しません
y = self.model_gan(* x).view(-1).detach()。cpu()。numpy()
gc.collect()
torch.cuda.empty_cache()
 tuong-olli
2020年06月25日
tuong-olli
2020年06月25日
トレーニング中に同じ問題が発生しました。
各エポックの後にゴミを収集し、cudaメモリを空にすることで問題が解決しました。
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
2020年08月05日
IsakWesterlundBitville
2020年08月05日
単に私のために働いたもの:
import gc # Your code with pytorch using GPU gc.collect()
ありがとうございました!! Cats and dogsの例を実行するのに問題があり、これはうまくいきました。
 Michelpayan
2020年08月05日
Michelpayan
2020年08月05日
トレーニング中に同じ問題が発生しました。
各エポックの後にゴミを収集し、cudaメモリを空にすることで問題が解決しました。gc.collect() torch.cuda.empty_cache()
わたしも
 AleksandrTulenkov
2020年08月06日
AleksandrTulenkov
2020年08月06日
バッチサイズを減らし、エポックを増やします。 それが私がそれを解決した方法です。
 oyekamal
2020年09月18日
oyekamal
2020年09月18日
@areebsyed RAMメモリを確認してください。多くのワーカーを並列に設定すると、この問題が発生しました。
guilhermesurek
2020年09月29日
Colabのpytorchで事前トレーニング済みのbert2bertEncoderDecoderModelを微調整しているときにも、1つのエポックを完了せずに、同じエラーが発生します。
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
2020年10月06日
Aakash12980
2020年10月06日
@ Aakash12980バッチサイズを減らしてみましたか? また、トレーニングしたい入力画像は、サイズを変更してみてください。
 areebsyed
2020年10月06日
areebsyed
2020年10月06日
@areebsyedはい、バッチサイズを4に減らしましたが、機能しました。
Aakash12980
2020年10月06日
同じ
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
2020年10月07日
monajalal
2020年10月07日
同じ
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalalは、バッチサイズまたは入力ディメンションサイズを減らしてみてください。
Aakash12980
2020年10月07日
では、以下のような例の解決策は何ですか(つまり、多くの_free_メモリを割り当て、ほとんど割り当てようとしません。これは、実際には空きメモリの量が少なく、何も問題がない場合のこのスレッドの_some_の例とは異なります)。
RuntimeError:CUDAのメモリが不足しています。 割り当てを試みました_1.33 GiB _(GPU 1; 31.72GiB合計容量; 5.68GiBはすでに割り当てられています; _ 24.94GiB空き_; 5.96 MiBキャッシュ)
最新のpytorchver(1.2)と最新のNVIDIA GPU(V-100)でも引き続き発生するため、問題が「クローズ」ステータスになった理由がわかりません。
ありがとう!
うん、ほとんどの人は問題が単にOOMではないことに気付いていないように感じます。それは、エラーが十分な空き領域があることを示しているのにOOMがあるということです。 私はWindowsでもこの問題に直面していますが、解決策はありましたか?
 YoadTew
2020年11月06日
YoadTew
2020年11月06日
関連する問題
 bartolsthoorn
·
3コメント
bartolsthoorn
·
3コメント
 ikostrikov
·
3コメント
ikostrikov
·
3コメント
 rajarshd
·
3コメント
rajarshd
·
3コメント
 soumith
·
3コメント
soumith
·
3コメント
 szagoruyko
·
3コメント
szagoruyko
·
3コメント
最も参考になるコメント
これは、データのミニバッチがGPUメモリに収まらないためです。 バッチサイズを小さくするだけです。 cifar10データセットのバッチサイズを256に設定すると、同じエラーが発生しました。 次に、バッチサイズを128に設定すると、解決されます。