Pytorch: 运行时错误:CUDA 内存不足。 尝试分配 12.50 MiB(GPU 0;10.92 GiB 总容量;已分配 8.57 MiB;9.28 GiB 空闲;4.68 MiB 缓存)
CUDA 内存不足错误,但 CUDA 内存几乎为空
我目前正在大量文本数据(大约 70GiB 文本)上训练一个轻量级模型。
为此,我在集群上使用一台机器( grid5000 集群网络的“grele” )。
训练 3 小时后,我收到了这条非常奇怪的 CUDA 内存不足错误消息:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) 。
根据消息,我有所需的空间,但它没有分配内存。
知道什么可能导致这种情况吗?
有关信息,我的预处理依赖于torch.multiprocessing.Queue和源数据行上的迭代器来动态预处理数据。
完整的堆栈跟踪
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
所有91条评论
我有相同的运行时错误:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
于 2019-01-27
OmarBazaraa
于 2019-01-27
@EMarquer @OmarBazaraa你能给出一个我们可以运行的最小重现示例吗?
 yf225
于 2019-01-28
yf225
于 2019-01-28
我无法再重现该问题,因此我将关闭该问题。
当我停止将预处理数据存储在 RAM 中时,问题就消失了。
@OmarBazaraa ,我认为您的问题与我的不同,因为:
- 我正在尝试分配 12.50 MiB,其中有 9.28 GiB 免费
- 您正在尝试分配 195.25 MiB,其中 170.14 MiB 免费
根据我之前对这个问题的经验,要么你没有释放 CUDA 内存,要么你试图在 CUDA 上放置太多数据。
通过不释放 CUDA 内存,我的意思是您可能仍然引用 CUDA 中不再使用的张量。 这些将阻止通过删除张量来释放分配的内存。
EMarquer
于 2019-01-28
有什么通用的解决方案吗?
CUDA 内存不足。 尝试分配 196.00 MiB(GPU 0;2.00 GiB 总容量;已分配 359.38 MiB;192.29 MiB 空闲;152.37 MiB 缓存)
 aniketspurohit
于 2019-01-31
aniketspurohit
于 2019-01-31
@aniks23我们正在开发一个补丁,我相信在这种情况下会提供更好的体验。 敬请关注
 fmassa
于 2019-01-31
fmassa
于 2019-01-31
有什么方法可以知道我的系统可以处理多大的模型或网络
没有遇到这个问题?
2019 年 2 月 1 日星期五上午 3:55 弗朗西斯科·马萨[email protected]
写道:
@aniks23 https://github.com/aniks23我们正在开发一个补丁,我
相信在这种情况下会提供更好的体验。 敬请关注—
你收到这个是因为你被提到了。
直接回复本邮件,在GitHub上查看
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
于 2019-02-01
我也收到了这条消息:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
它发生在我尝试运行Fast.ai 课程 1 宠物https://course.fast.ai/ (单元 31)时
 adrianovieira
于 2019-03-12
adrianovieira
于 2019-03-12
我也遇到了同样的错误。 我的模型早些时候使用了确切的设置,但现在在我修改了一些看似无关的代码后出现了这个错误。
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
于 2019-03-14
treble-maker123
于 2019-03-14
我不知道我的场景是否与原始问题有关,但我通过分解模型中的 nn.Sequential 层解决了我的问题(上一条消息中的 OOM 错误消失了),例如
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
到
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
我的模型有更多这些(准确地说是 5 个)。 我使用 nn.Sequential 对吗? 或者这是一个错误? @yf225 @fmassa
treble-maker123
于 2019-03-14
我也收到类似的错误:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@treble-maker123,您是否能够最终证明 nn.Sequential 是问题所在?
 yasheshgaur
于 2019-03-17
yasheshgaur
于 2019-03-17
我有一个类似的问题。 我正在使用 pytorch 数据加载器。 说我应该有超过 5 Gb 的免费空间,但它提供了 0 字节的免费空间。
RuntimeError Traceback(最近一次调用)
22
23 个数据,输入 = states_inputs
---> 24 个数据,输入 = Variable(data).float().to(device), Variable(inputs).float().to(device)
25 打印(数据.设备)
26 enc_out = 编码器(数据)
运行时错误:CUDA 内存不足。 尝试分配 11.00 MiB(GPU 0;6.00 GiB 总容量;已分配 448.58 MiB;0 字节空闲;942.00 KiB 缓存)
 ahsteven
于 2019-04-03
ahsteven
于 2019-04-03
你好,我也遇到了这个错误。
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
于 2019-04-17
AlbertZhangHIT
于 2019-04-17
可悲的是,我也遇到了同样的问题。
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
我已经在一组服务器中训练了我的模型,并且错误发生在我的一台服务器上。 此外,这种有线错误仅发生在我的一种训练策略中。 而且唯一的区别是我在数据扩充时修改了代码,使数据预处理比其他的更复杂。 但我不确定如何解决这个问题。
 qingyu-wang
于 2019-04-25
qingyu-wang
于 2019-04-25
我也有这个问题。 怎么解决??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
于 2019-05-10
nabil2i
于 2019-05-10
同样的问题RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
于 2019-05-16
williamluke4
于 2019-05-16
@fmassa你有这方面的更多信息吗?
williamluke4
于 2019-05-18
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
对我来说同样的问题
亲,你解决了吗?
(base) F:\Suresh\st-gcn>python main1.py 识别 -c config/st_gcn/ntu-xsub/train.yaml --device 0 --work_dir ./work_dir
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117: UserWarning:
找到 GPU0 TITAN Xp,它具有 cuda 功能 1.1。
PyTorch 不再支持这个 GPU,因为它太旧了。
警告.警告(old_gpu_warn %(d,名称,专业,能力[1]))
[05.22.19|12:02:41] 参数:
{'base_lr':0.1,'ignore_weights':[],'model':'net.st_gcn.Model','eval_interval':5,'weight_decay':0.0001,'work_dir':'./work_dir','save_interval ': 10, 'model_args': {'in_channels': 3, 'dropout': 0.5, 'num_class': 60, 'edge_importance_weighting': True, 'graph_args': {'strategy': 'spatial', 'layout': 'ntu-rgb+d'}}, 'debug': False, 'pavi_log': False, 'save_result': False, 'config': 'config/st_gcn/ntu-xsub/train.yaml', '优化器': 'SGD','权重':无,'num_epoch':80,'batch_size':64,'show_topk':[1, 5],'test_batch_size':64,'step':[10, 50],'use_gpu ': True, 'phase': 'train', 'print_log': True, 'log_interval': 100, 'feeder': 'feeder.feeder.Feeder', 'start_epoch': 0, 'nesterov': True, 'device ': [0], 'save_log': True, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU- RGB-D/xsub/val_label.pkl'}, 'train_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/train_data.npy', 'debug': False, 'label_path': ' ./data/NTU-RGB-D/xsub/train_l abel.pkl'}, 'num_worker': 4}
[05.22.19|12:02:41] 训练时期:0
回溯(最近一次调用最后一次):
文件“main1.py”,第 31 行,在
p.start()
文件“F:\Suresh\st-gcn\processor\processor.py”,第 113 行,在开始
self.train()
文件“F:\Suresh\st-gcn\processor\recognition.py”,第 91 行,在火车中
输出 = self.model(data)
文件“C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py”,第 489 行,在 __call__ 中
结果 = self.forward(输入,* kwargs)
文件“F:\Suresh\st-gcn\net\st_gcn.py”,第 82 行,向前
x, _ = gcn(x, self.A * 重要性)
文件“C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py”,第 489 行,在 __call__ 中
结果 = self.forward(输入,* kwargs)
文件“F:\Suresh\st-gcn\net\st_gcn.py”,第 194 行,向前
x, A = self.gcn(x, A)
文件“C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py”,第 489 行,在 __call__ 中
结果 = self.forward(输入,* kwargs)
文件“F:\Suresh\st-gcn\net\utils\tgcn.py”,第 60 行,向前
x = self.conv(x)
文件“C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py”,第 489 行,在 __call__ 中
结果 = self.forward(输入,* kwargs)
文件“C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py”,第320行,向前
self.padding, self.dilation, self.groups)
运行时错误:CUDA 内存不足。 尝试分配 1.37 GiB(GPU 0;12.00 GiB 总容量;已分配 8.28 GiB;652.75 MiB 空闲;664.38 MiB 缓存)
 Sureshthommandru
于 2019-05-22
Sureshthommandru
于 2019-05-22
这是因为小批量数据不适合 GPU 内存。 只需减少批量大小。 当我为 cifar10 数据集设置批量大小 = 256 时,我得到了同样的错误; 然后我设置batch size=128,就解决了。
 balcilar
于 2019-06-01
balcilar
于 2019-06-01
是的@balcilar是对的,我减少了批量大小,现在它可以工作了
 EKELE-NNOROM
于 2019-06-04
EKELE-NNOROM
于 2019-06-04
我有个类似的问题:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
我正在使用 8 V100 来训练模型。 令人困惑的部分是仍然有 3.03GB 缓存,无法分配给 11.88MB。
 magic282
于 2019-06-10
magic282
于 2019-06-10
您是否更改了批量大小。 将批量大小减少一半。 说批
大小是 16 来实现,尝试使用 8 的批量大小,看看它是否有效。
享受
在 2019 年 6 月 10 日星期一凌晨 2 点 10 分,magic282 [email protected]写道:
我有个类似的问题:
运行时错误:CUDA 内存不足。 尝试分配 11.88 MiB(GPU 4;15.75 GiB 总容量;10.50 GiB 已分配;1.88 MiB 空闲;3.03 GiB 缓存)
我正在使用 8 V100 来训练模型。 令人困惑的部分是有
仍然缓存了 3.03GB,不能分配给 11.88MB。—
您收到此消息是因为您发表了评论。
直接回复本邮件,在GitHub上查看
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LODMX500000000000000000000000000000000 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
于 2019-06-10
我尝试减少批量大小并且它起作用了。 令人困惑的部分是缓存内存大于要分配的内存的错误消息。
magic282
于 2019-06-11
当我使用predict时,我在预训练模型上遇到了同样的问题。 所以减少批量大小是行不通的。
 pvk444
于 2019-06-30
pvk444
于 2019-06-30
如果您更新到最新版本的 PyTorch,您可能会遇到这样的错误
fmassa
于 2019-06-30
我可以问为什么错误中的数字不加起来吗?!
我(和你们一样)得到:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
对我来说,这意味着以下应该大致正确:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
但事实并非如此。 什么是我弄错了?
 AzimAhmadzadeh
于 2019-07-03
AzimAhmadzadeh
于 2019-07-03
我在训练U-net时也遇到了这个问题,缓存足够了,但它仍然崩溃
 tongpinmo
于 2019-07-10
tongpinmo
于 2019-07-10
我有同样的错误...
运行时错误:CUDA 内存不足。 尝试分配 312.00 MiB(GPU 0;10.91 GiB 总容量;1.07 GiB 已分配;109.62 MiB 空闲;15.21 MiB 缓存)
 MSKazemi
于 2019-07-10
MSKazemi
于 2019-07-10
尝试减小尺寸(任何不会改变结果的尺寸)都会起作用。
 giangnguyen2412
于 2019-07-11
giangnguyen2412
于 2019-07-11
尝试减小尺寸(任何不会改变结果的尺寸)都会起作用。
您好,我将batch_size 更改为1,但不起作用!
 BCWang93
于 2019-07-14
BCWang93
于 2019-07-14
可能你应该换一个尺寸。
Vào 21:50, CN, 14 Th7, 2019 Bcw93 [email protected] đã viết:
尝试减小尺寸(任何不会改变结果的尺寸)都会起作用。
您好,我将batch_size 更改为1,但不起作用!
—
您收到此消息是因为您发表了评论。
直接回复本邮件,在GitHub上查看
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXWSEWJ0Z00000000000000000000
或静音线程
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
于 2019-07-15
收到此错误:
运行时错误:CUDA 内存不足。 尝试分配 2.00 MiB(GPU 0;7.94 GiB 总容量;7.33 GiB 已分配;1.12 MiB 空闲;40.48 MiB 缓存)
英伟达-smi
2019 年 8 月 22 日星期四 21:05:52
+------------------------------------------------- -----------------------------+
| NVIDIA-SMI 430.40 驱动程序版本:430.40 CUDA 版本:10.1 |
|-----------------------------------------+----------------- -----+----------------------+
| GPU名称持久性-M| 总线 ID Disp.A | 挥发性未校正。 ECC |
| 风扇温度性能Pwr:Usage/Cap | 内存使用 | GPU-Util 计算 M。
|==================================================== ======+========================|
| 0 Quadro M4000 关闭 | 00000000:09:00.0 开 | 不适用 |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% 默认 |
+-------------------------------+----------------- -----+----------------------+
| 1 GeForce GTX 105...关闭 | 00000000:41:00.0 开 | 不适用 |
| 29% 33C P8 不适用 / 75W | 262MiB / 4032MiB | 0% 默认 |
+-------------------------------+----------------- -----+----------------------+
+------------------------------------------------- -----------------------------+
| 进程:GPU 内存 |
| GPU PID 类型进程名称用法|
|================================================== ==============================|
| 0 1909 G /usr/lib/xorg/Xorg 50MiB |
| 1 1909 G /usr/lib/xorg/Xorg 128MiB |
| 1 5236 G ...quest-channel-token=9884100064965360199 130MiB |
+------------------------------------------------- -----------------------------+
操作系统:Ubuntu 18.04 仿生
内核:x86_64 Linux 4.15.0-58-generic
正常运行时间:29m
包装:2002
外壳:bash 4.4.20
分辨率:1920x1080 1080x1920
德:LXDE
WM:OpenBox
GTK 主题:Lubuntu-default [GTK2]
图标主题:Lubuntu
字体:Ubuntu 11
CPU:AMD 锐龙 Threadripper 2970WX 24 核 @ 48x 3GHz [61.8°C]
GPU:Quadro M4000、GeForce GTX 1050 Ti
内存:3194MiB / 64345MiB
 danindiana
于 2019-08-23
danindiana
于 2019-08-23
这是固定的吗? 我已将大小和批量大小都减小到 1。我在这里看不到任何其他解决方案,但此票已关闭。 我在 Cuda 10.1 Windows 10、Pytorch 1.2.0 上遇到了同样的问题
 hughkf
于 2019-09-06
hughkf
于 2019-09-06
@hughkf您在代码中的
 aidoshacks
于 2019-09-06
aidoshacks
于 2019-09-06
@aidoshacks ,这取决于您的代码。 但这是一个例子。 这是在我的机器上可靠地导致此问题的笔记本之一: https :
bs,size = 8,src_size//2到bs,size = 1,1但我仍然遇到内存不足的问题。
hughkf
于 2019-09-06
对我来说,将 batch_size 从 128 更改为 64 有效,但这对我来说似乎不是公开的解决方案,还是我遗漏了什么?
 shalgi
于 2019-09-19
shalgi
于 2019-09-19
这个问题解决了吗? 我也遇到了同样的问题。 我没有更改任何代码,但运行多次后,出现此错误:
“运行时错误:CUDA 内存不足。尝试分配 40.00 MiB(GPU 0;15.77 GiB 总容量;13.97 GiB 已分配;256.00 KiB 空闲;824.57 MiB 缓存)”
 mengxiangming
于 2019-09-26
mengxiangming
于 2019-09-26
仍然有这个问题,如果状态更改为未解决就好了。
编辑:
与批处理大小无关,因为我用批处理大小 1 得到它。重新启动内核为我修复了它,从那以后就没有发生过。
 just-in-kees
于 2019-09-29
just-in-kees
于 2019-09-29
那么像下面这样的示例的解决方案是什么(即大量空闲内存并试图分配很少 - 这与此线程中的一些示例不同,当实际上空闲内存很少并且没有任何问题时)?
运行时错误:CUDA 内存不足。 尝试分配1.33 GiB (GPU 1;31.72 GiB 总容量;已分配 5.68 GiB; 24.94 GiB 空闲;5.96 MiB 缓存)
我不明白为什么问题会变成“关闭”状态,因为它仍然发生在最新的 pytorch 版本 (1.2) 和现代 NVIDIA GPU (V-100) 上
谢谢!
 yuribd
于 2019-10-03
yuribd
于 2019-10-03
大多数情况下,您从 fastai 包中收到此特定错误消息是因为您使用的是异常小的 GPU。 我通过重新启动内核并为您提供的路径使用较小的批处理大小来解决此问题。
 AurioPinto
于 2019-10-05
AurioPinto
于 2019-10-05
同样的问题在这里。 当我使用pytorch0.4.1,batch size=4时,没问题。 但是当我改成pytorch1.3,甚至将batch size设置为1时,就出现了oom问题。
 Sarah20187
于 2019-10-21
Sarah20187
于 2019-10-21
通过将我的 pytorch 更新到最新版本来解决它... conda update pytorch
 kafura0
于 2019-10-21
kafura0
于 2019-10-21
这是因为小批量数据不适合 GPU 内存。 只需减少批量大小。 当我为 cifar10 数据集设置批量大小 = 256 时,我得到了同样的错误; 然后我设置batch size=128,就解决了。
谢谢,我通过这种方式解决了错误。
 zhangzibao
于 2019-10-25
zhangzibao
于 2019-10-25
我将 batch_size 减小到 8,它工作正常。 这个想法是有一个小的batch_size
 Asutosh11
于 2019-10-30
Asutosh11
于 2019-10-30
我认为这取决于特定层正在处理的总输入大小。 例如,如果一批 256 (32x32) 个图像在一个层中通过 128 个过滤器,则总输入大小为 256x32x32x128 = 2^25。 这个数字应该低于某个阈值,我猜这是机器特定的。 例如,对于 AWS p3.2xlarge,它是 2^26。 因此,如果您遇到 CuDA 内存错误,请尝试减少批次大小或过滤器数量,或者进行更多下采样,例如步幅或池化层
 souryadey
于 2019-11-01
souryadey
于 2019-11-01
有同样的问题:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
使用最新的 pytorch (1.3) 和 cuda (10.1) 版本。 Nvidia-smi 还显示半空 GPU,因此错误消息中的可用内存量是正确的。 还不能用简单的代码重现它
 ArgentumWalker
于 2019-11-03
ArgentumWalker
于 2019-11-03
重置内核也对我有用! 在我这样做之前,即使批量大小= 1 也无法工作
 kennethjmyers
于 2019-11-07
kennethjmyers
于 2019-11-07
伙计们,我解决了将批量减少一半的问题。
 faizao
于 2019-11-19
faizao
于 2019-11-19
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
重启后修复
 SomeUserName1
于 2019-11-22
SomeUserName1
于 2019-11-22
将 batch_size 64(rtx2080 ti) 改为 32(rtx 2060),问题解决。 但我想知道解决此类问题的其他方法。
 sailfish009
于 2019-12-03
sailfish009
于 2019-12-03
当我做预测时,这发生在我身上!
我将批量大小从 1024 更改为 8,但在评估 82% 的测试集时仍然出现错误。
当我添加with torch.no_grad() ,问题就解决了。
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
于 2019-12-17
smasoudn
于 2019-12-17
我解决了这个问题
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
到loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
于 2019-12-27
zhonghaochen
于 2019-12-27
我遇到了同样的问题,我检查了我机器上的 GPU 利用率。 已经使用了很多,剩下的内存量非常少。 我杀死了我的 jupyter 笔记本并重新启动了它。 内存变得空闲,事情开始工作。 您可以在下面使用:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
于 2019-12-27
prabhatsharma
于 2019-12-27
我也收到了这条消息:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)它发生在我尝试运行Fast.ai 课程 1 宠物https://course.fast.ai/ (单元 31)时
尝试减少训练数据的批量大小 (bs)。
看看什么对你有用。
 rishi0904
于 2019-12-27
rishi0904
于 2019-12-27
我发现这个问题可以在不调整批量大小的情况下解决。
打开终端和 python 提示
import torch
torch.cuda.empty_cache()
退出 Python 解释器,重新运行原始 PyTorch 命令,它应该(希望)不会产生 CUDA 内存错误。
 cpoptic
于 2020-01-03
cpoptic
于 2020-01-03
我发现当我的计算机使用过多的 CPU RAM 时,通常会出现此问题。 所以当我们想要更大的批量大小时,我们可以尝试减少 CPU RAM 的使用。
 dhKwang
于 2020-01-13
dhKwang
于 2020-01-13
有一个类似的问题。
减少批处理大小并重新启动内核有助于解决问题。
 kumarnikhil936
于 2020-01-19
kumarnikhil936
于 2020-01-19
就我而言,用 SGD 优化器替换 Adam 优化器解决了同样的问题。
 tranvanluan2
于 2020-01-23
tranvanluan2
于 2020-01-23
好吧,就我而言,使用with torch.no_grad(): (train model) 、 output.to("cpu")和torch.cuda.empty_cache() ,这个问题就解决了。
 PlanNoa
于 2020-01-30
PlanNoa
于 2020-01-30
运行时错误:CUDA 内存不足。 尝试分配 54.00 MiB(GPU 0;3.95 GiB 总容量;已分配 2.65 GiB;39.00 MiB 免费;87.29 MiB 缓存)
我找到了解决方案,并减少了 batch_size 值。
 sagrawal06
于 2020-01-30
sagrawal06
于 2020-01-30
我正在自定义数据集上使用 Darknet53 权重训练 YOLOv3。 我的 GPU 是 NVIDIA RTX 2080,我也遇到了同样的问题。 更改批量大小解决了它。
 wilderrodrigues
于 2020-02-02
wilderrodrigues
于 2020-02-02
我在推理期间收到此错误....我是 ru
CUDA 内存不足。 尝试分配 102.00 MiB(GPU 0;15.78 GiB 总容量;14.54 GiB 已分配;48.44 MiB 空闲;PyTorch 总共保留 14.67 GiB)
-------------------------------------------------- ---------------------------+
| NVIDIA-SMI 440.59 驱动程序版本:440.59 CUDA 版本:10.2 |
|-----------------------------------------+----------------- -----+----------------------+
| GPU名称持久性-M| 总线 ID Disp.A | 挥发性未校正。 ECC |
| 风扇温度性能Pwr:Usage/Cap | 内存使用 | GPU-Util 计算 M。
|==================================================== ======+========================|
| 0 特斯拉 V100-SXM2... 开 | 00000000:00:1E.0 关闭 | 0 |
| 不适用 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% 默认 |
+-------------------------------+----------------- -----+----------------------+
+------------------------------------------------- -----------------------------+
| 进程:GPU 内存 |
| GPU PID 类型进程名称用法|
|================================================== ==============================|
| 0 13978 C/ .conda /
+------------------------------------------------- -----------------------------+
 tvinith
于 2020-02-29
tvinith
于 2020-02-29
这是因为小批量数据不适合 GPU 内存。 只需减少批量大小。 当我为 cifar10 数据集设置批量大小 = 256 时,我得到了同样的错误; 然后我设置batch size=128,就解决了。
谢谢你,你说得对
 Rxma1805
于 2020-03-02
Rxma1805
于 2020-03-02
对于有足够 GPU 内存但仍会引发错误的特殊情况。 在我的情况下,我通过减少数据加载器中的工作人员数量来解决它。
 Yurasyk
于 2020-03-14
Yurasyk
于 2020-03-14
背景
py36、pytorch1.4、tf2.0、康达
微调罗伯塔
问题
与@EMarquer相同的问题: pycharm显示我仍然有足够的内存,但是分配内存失败,内存不足。
我试过的方法
- “batch_size = 1”失败
- “torch.cuda.empty_cache()”失败
- CUDA_VISIBLE_DEVICES="0" python Run.py 失败
- 因为我不使用jupyter,所以不需要重启内核
成功之道
- 英伟达-smi


- 事实是,pycharm 显示的内容与“nvidia-smi”显示的内容不同(抱歉,我没有保存 pycharm 的图片),实际上没有足够的内存。
- 进程 6123 和 32644 之前在终端上运行。
- 须藤杀-9 6123
- 须藤杀-9 32644
 FernandoZhuang
于 2020-03-17
FernandoZhuang
于 2020-03-17
什么对我有用:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
于 2020-04-06
MastafaF
于 2020-04-06
我发现这个问题可以在不调整批量大小的情况下解决。
打开终端和 python 提示
import torch torch.cuda.empty_cache()退出 Python 解释器,重新运行原始 PyTorch 命令,它应该(希望)不会产生 CUDA 内存错误。
就我而言,它解决了我的问题。
 LiEAEX
于 2020-04-10
LiEAEX
于 2020-04-10
确保在插槽 0 使用 GPU 并使用 --device_ids 0
我知道我正在扼杀这些术语,但它奏效了。 如果您不选择 id,我想它假设您想使用 CPU 而不是 GPU。
 aaron387
于 2020-04-12
aaron387
于 2020-04-12
我收到同样的错误:
运行时错误:CUDA 内存不足。 尝试分配 4.84 GiB(GPU 0;7.44 GiB 总容量;已分配 5.22 GiB;1.75 GiB 空闲;18.51 MiB 缓存)
当我重新启动集群或更改批量大小时,它可以工作。 但我不喜欢这个解决方案。 我什至尝试过 torch.cuda.empty_cache() ,这对我不起作用。 有没有其他有效的方法来解决这个问题?
 Tann10
于 2020-04-13
Tann10
于 2020-04-13
我不知道我的场景是否与原始问题有关,但我通过分解模型中的 nn.Sequential 层解决了我的问题(上一条消息中的 OOM 错误消失了),例如
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)到
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))我的模型有更多这些(准确地说是 5 个)。 我使用 nn.Sequential 对吗? 或者这是一个错误? @yf225 @fmassa
看来我也解决了类似的错误,但与您相反。
我改变一切
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)到
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
于 2020-04-14
xml94
于 2020-04-14
对我来说,更改 batch_size 或任何给定的解决方案都没有帮助。 但事实证明,在我的 .cfg 文件中,我在一层中有错误的类值和过滤器。 因此,如果没有任何帮助,请仔细检查您的 .cfg。
 ulaszewskim
于 2020-05-01
ulaszewskim
于 2020-05-01
打开终端
第一种
英伟达-smi
然后选择python或anaconda路径对应的PID并写入
须藤杀死 -9 PID
 krypticmouse
于 2020-05-04
krypticmouse
于 2020-05-04
我已经有一段时间了这个错误。 对我来说,事实证明我一直持有一个引用模型结果的 python 变量(即火炬张量),因此不能安全地释放它,因为代码仍然可以访问它。
我的代码看起来像:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
解决方法是将p转移到列表中。 因此,代码应如下所示:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
这确保predictions在主内存中保存值,而不是 GPU 中的张量。
 abdelrahmanhosny
于 2020-05-08
abdelrahmanhosny
于 2020-05-08
我使用依赖 pytorch 的 fastai.vision 模块遇到了这个错误。 我正在使用 CUDA 10.1
 jkomyno
于 2020-05-16
jkomyno
于 2020-05-16
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
将 per_gpu_train_batch_size 从 16 减少到 8,它解决了我的问题。
 autodataming
于 2020-06-03
autodataming
于 2020-06-03
如果您更新到最新版本的 PyTorch,您可能会遇到这样的错误
真的,为什么这么说
 XinyingZheng
于 2020-06-09
XinyingZheng
于 2020-06-09
这个问题的主要问题仍然是一个未解决的问题。 我收到了同样奇怪的 CUDA 内存不足消息。 它试图在 4.08 GiB 空闲空间中分配 2.26 GiB。 看似有足够的内存,但分配失败。
项目信息:在批处理大小为 4 的 activitynet 数据集上训练 resnet 10,它在第一个 epoch 的最后阶段失败。
编辑:一些看法:如果我清理我的 RAM 内存并只保持 python 代码运行,则不会引发错误。 也许 GPU 内存足够,但 RAM 内存无法处理所有其他处理步骤。
计算机信息:戴尔 G5 - i7 9th - GTX 1660Ti 6GB - 16 GB RAM
EDITED2:我正在使用“_MultiProcessingDataLoaderIter”和 4 个工人,它在前向调用中引发内存不足消息。 如果我将工人数量减少到 1,它不会引发任何错误。 使用 1 个工人时,ram 内存使用量保持在 11/16GB,而使用 4 个则提高到 14.5/16GB。 实际上,只需 1 个工人,我就可以将批量大小提高到 32,从而将 GPU 内存提高到 3.5GB/6GB。
运行时错误:CUDA 内存不足。 尝试分配 2.26 GiB(GPU 0;6.00 GiB 总容量;209.63 MiB 已分配;4.08 GiB 空闲;PyTorch 总共保留 246.00 MiB)
整个错误信息
回溯(最近一次调用最后一次):
文件“main.py”,第 450 行,在
如果 opt.distributed:
文件“main.py”,第 409 行,在 main_worker 中
opt.device, current_lr, train_logger,
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\training.py”,第 37 行,在 train_epoch
输出 = 模型(输入)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py”,第 532 行,在 __call__
结果 = self.forward(输入,* kwargs)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py”,第150行,向前
返回 self.module( inputs[0], * kwargs[0])
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py”,第 532 行,在 __call__
结果 = self.forward(输入,* kwargs)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py”,第205行,向前
x = self.layer3(x)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py”,第532行,__call__
结果 = self.forward(输入,* kwargs)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py”,第100行,向前
输入 = 模块(输入)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py”,第532行,__call__
结果 = self.forward(输入,* kwargs)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py”,第51行,向前
out = self.conv2(out)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py”,第532行,__call__
结果 = self.forward(输入,* kwargs)
文件“D:\Guilherme\Google Drive\Profissional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py”,第480行,向前
self.padding, self.dilation, self.groups)
运行时错误:CUDA 内存不足。 尝试分配 2.26 GiB(GPU 0;6.00 GiB 总容量;209.63 MiB 已分配;4.08 GiB 免费;246.00 MiB 保留
总共由 PyTorch 提供)
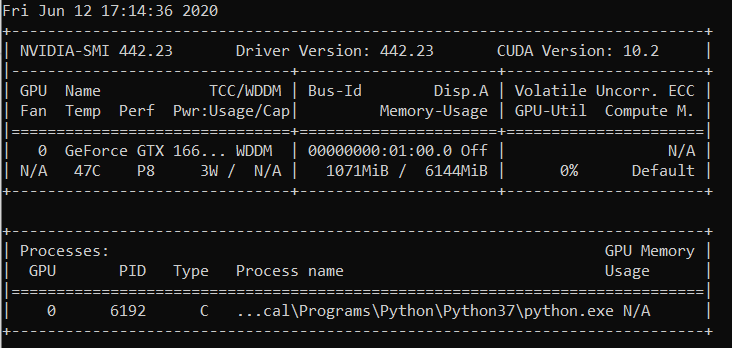
 guilhermesurek
于 2020-06-12
guilhermesurek
于 2020-06-12
小批量,它的工作原理
 cuge1995
于 2020-06-15
cuge1995
于 2020-06-15
我已经有一段时间了这个错误。 对我来说,事实证明我一直持有一个引用模型结果的 python 变量(即火炬张量),因此不能安全地释放它,因为代码仍然可以访问它。
我的代码看起来像:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)解决方法是将
p转移到列表中。 因此,代码应如下所示:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())这确保
predictions在主内存中保存值,而不是 GPU 中的张量。
@abdelrahmanhosny感谢您指出这一点。 我在 PyTorch 1.5.0 中遇到了完全相同的问题,并且在训练期间没有 OOM 问题但是在推理期间我还一直持有一个 python 变量(即火炬张量),该变量在内存中引用模型结果,这导致 GPU 内存不足经过一定数量的批次。
然而,在我的情况下,将预测转移到列表中不起作用,因为我正在使用我的网络生成图像,因此我必须执行以下操作:
predictions.append(p.detach().cpu().numpy())
这样就解决了问题!
 samkellerhals
于 2020-06-19
samkellerhals
于 2020-06-19
有什么通用的解决方案吗?
CUDA 内存不足。 尝试分配 196.00 MiB(GPU 0;2.00 GiB 总容量;已分配 359.38 MiB;192.29 MiB 空闲;152.37 MiB 缓存)
有什么通用的解决方案吗?
CUDA 内存不足。 尝试分配 196.00 MiB(GPU 0;2.00 GiB 总容量;已分配 359.38 MiB;192.29 MiB 空闲;152.37 MiB 缓存)
 manavkhadka0
于 2020-06-24
manavkhadka0
于 2020-06-24
我已经有一段时间了这个错误。 对我来说,事实证明我一直持有一个引用模型结果的 python 变量(即火炬张量),因此不能安全地释放它,因为代码仍然可以访问它。
我的代码看起来像:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)解决方法是将
p转移到列表中。 因此,代码应如下所示:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())这确保
predictions在主内存中保存值,而不是 GPU 中的张量。@abdelrahmanhosny感谢您指出这一点。 我在 PyTorch 1.5.0 中遇到了完全相同的问题,并且在训练期间没有 OOM 问题但是在推理期间我还一直持有一个 python 变量(即火炬张量),该变量在内存中引用模型结果,这导致 GPU 内存不足经过一定数量的批次。
然而,在我的情况下,将预测转移到列表中不起作用,因为我正在使用我的网络生成图像,因此我必须执行以下操作:
predictions.append(p.detach().cpu().numpy())这样就解决了问题!
我在 ParrallelWaveGAN 模型中遇到了同样的问题,我使用了 #16417 中的解决方案,但它对我不起作用
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
gc.collect()
torch.cuda.empty_cache()
 tuong-olli
于 2020-06-25
tuong-olli
于 2020-06-25
在训练期间遇到了同样的问题。
在每个纪元后收集垃圾并清空 cuda 内存为我解决了这个问题。
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
于 2020-08-05
IsakWesterlundBitville
于 2020-08-05
什么对我有用:
import gc # Your code with pytorch using GPU gc.collect()
谢谢!! 我在运行猫和狗的例子时遇到了麻烦,这对我有用。
 Michelpayan
于 2020-08-05
Michelpayan
于 2020-08-05
在训练期间遇到了同样的问题。
在每个纪元后收集垃圾并清空 cuda 内存为我解决了这个问题。gc.collect() torch.cuda.empty_cache()
我也是
 AleksandrTulenkov
于 2020-08-06
AleksandrTulenkov
于 2020-08-06
减少批量大小并增加时代。 我就是这样解决的。
 oyekamal
于 2020-09-18
oyekamal
于 2020-09-18
@areebsyed检查 ram 内存,我在并行设置许多工人时遇到了这个问题。
guilhermesurek
于 2020-09-29
在 Colab 的 pytorch 中微调预训练的 bert2bert EncoderDecoderModel 时,我也遇到了同样的错误,甚至没有完成一个 epoch。
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
于 2020-10-06
Aakash12980
于 2020-10-06
@Aakash12980您是否尝试过减少批量大小? 您想要训练的输入图像也可能尝试调整它们的大小
 areebsyed
于 2020-10-06
areebsyed
于 2020-10-06
@areebsyed是的,我将批量大小减少到 4 并且它起作用了。
Aakash12980
于 2020-10-06
相同的
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
于 2020-10-07
monajalal
于 2020-10-07
相同的
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal尝试减少批量大小或输入维度大小。
Aakash12980
于 2020-10-07
那么像下面这样的例子的解决方案是什么(即大量_free_内存并试图分配很少 - 这与此线程中的_some_示例不同,当实际上空闲内存很少并且没有任何问题时)?
运行时错误:CUDA 内存不足。 尝试分配 _ 1.33 GiB _(GPU 1;31.72 GiB 总容量;已分配 5.68 GiB;_ 24.94 GiB 空闲_;5.96 MiB 缓存)
我不明白为什么问题会变成“关闭”状态,因为它仍然发生在最新的 pytorch 版本 (1.2) 和现代 NVIDIA GPU (V-100) 上
谢谢!
是的,我觉得大多数人都没有意识到问题不仅仅是 OOM,而是 OOM 而错误说有足够的可用空间。 我在windows上也遇到这个问题,请问有解决办法吗?
 YoadTew
于 2020-11-06
YoadTew
于 2020-11-06
相关问题
 bartolsthoorn
·
3评论
bartolsthoorn
·
3评论
 dablyo
·
3评论
dablyo
·
3评论
 soumith
·
3评论
soumith
·
3评论
 ikostrikov
·
3评论
ikostrikov
·
3评论
 cdluminate
·
3评论
cdluminate
·
3评论
最有用的评论
这是因为小批量数据不适合 GPU 内存。 只需减少批量大小。 当我为 cifar10 数据集设置批量大小 = 256 时,我得到了同样的错误; 然后我设置batch size=128,就解决了。