Pytorch: RuntimeError: CUDA sem memória. Tentei alocar 12,50 MiB (GPU 0; capacidade total de 10,92 GiB; 8,57 MiB já alocado; 9,28 GiB livre; 4,68 MiB em cache)
Erro de falta de memória CUDA, mas a memória CUDA está quase vazia
Atualmente, estou treinando um modelo leve em uma grande quantidade de dados textuais (cerca de 70 GiB de texto).
Para isso, estou usando uma máquina em um cluster ( 'grele' da rede de cluster grid5000 ).
Após 3h de treinamento, estou recebendo esta mensagem de erro CUDA Out of Memory muito estranha:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) .
De acordo com a mensagem, tenho o espaço necessário, mas não aloca a memória.
Alguma ideia do que pode causar isso?
Para obter informações, meu pré-processamento depende de torch.multiprocessing.Queue e um iterador nas linhas de meus dados de origem para pré-processar os dados em tempo real.
Stacktrace completo
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
Todos 91 comentários
Eu tenho o mesmo erro de tempo de execução:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
em 27 jan. 2019
OmarBazaraa
em 27 jan. 2019
@EMarquer @OmarBazaraa Você poderia dar um exemplo de reprodução mínima que possamos executar?
 yf225
em 28 jan. 2019
yf225
em 28 jan. 2019
Não consigo mais reproduzir o problema, portanto, irei encerrá-lo.
O problema desapareceu quando parei de armazenar os dados pré-processados na RAM.
@OmarBazaraa , não acho que o seu problema seja igual ao meu, pois:
- Estou tentando alocar 12,50 MiB, com 9,28 GiB livre
- você está tentando alocar 195,25 MiB, com 170,14 MiB livre
Da minha experiência anterior com este problema, ou você não libera a memória CUDA ou tenta colocar muitos dados no CUDA.
Por não liberar a memória CUDA, quero dizer que você potencialmente ainda tem referências a tensores em CUDA que não usa mais. Isso evitaria que a memória alocada fosse liberada pela exclusão dos tensores.
EMarquer
em 28 jan. 2019
Existe alguma solução geral?
CUDA sem memória. Tentou alocar 196,00 MiB (GPU 0; capacidade total de 2,00 GiB; 359,38 MiB já alocado; 192,29 MiB livre; 152,37 MiB em cache)
 aniketspurohit
em 31 jan. 2019
aniketspurohit
em 31 jan. 2019
@ aniks23 estamos trabalhando em um patch que acredito que dará melhor experiência neste caso. Fique ligado
 fmassa
em 31 jan. 2019
fmassa
em 31 jan. 2019
Existe alguma maneira de saber o tamanho de um modelo ou rede que meu sistema pode suportar
sem topar com esse problema?
Na sexta-feira, 1º de fevereiro de 2019 às 03h55 Francisco Massa [email protected]
escreveu:
@ aniks23 https://github.com/aniks23 estamos trabalhando em um patch que eu
acredito que dará uma experiência melhor neste caso. Fique ligado-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
em 1 fev. 2019
Eu também recebi esta mensagem:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
Aconteceu quando eu estava tentando executar o Fast.ai lição1 Animais de estimação https://course.fast.ai/ (célula 31)
 adrianovieira
em 12 mar. 2019
adrianovieira
em 12 mar. 2019
Eu também estou cometendo os mesmos erros. Meu modelo estava trabalhando anteriormente com a configuração exata, mas agora está apresentando este erro depois que modifiquei algum código aparentemente não relacionado.
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
em 14 mar. 2019
treble-maker123
em 14 mar. 2019
Não sei se meu cenário pode ser relacionado ao problema original, mas resolvi meu problema (o erro OOM na mensagem anterior foi embora) quebrando as camadas nn. Camadas sequenciais em meu modelo, por exemplo,
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
para
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
Meu modelo tem muito mais destes (mais 5 para ser exato). Estou usando nn.Sequential certo? Ou isso é um bug? @ yf225 @fmassa
treble-maker123
em 14 mar. 2019
Estou recebendo um erro semelhante também:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@ treble-maker123, você conseguiu provar de forma conclusiva que nn.Sequential é o problema?
 yasheshgaur
em 17 mar. 2019
yasheshgaur
em 17 mar. 2019
Estou tendo um problema semelhante. Estou usando o dataloader pytorch. SaysI deveria ter mais de 5 Gb livres, mas dá 0 bytes livres.
RuntimeError Traceback (última chamada mais recente)
22
23 dados, entradas = estados_inputs
---> 24 dados, entradas = Variável (dados) .float (). Para (dispositivo), Variável (entradas) .float (). Para (dispositivo)
25 imprimir (data.device)
26 enc_out = codificador (dados)
RuntimeError: CUDA sem memória. Tentei alocar 11,00 MiB (GPU 0; capacidade total de 6,00 GiB; 448,58 MiB já alocados; 0 bytes livres; 942,00 KiB em cache)
 ahsteven
em 3 abr. 2019
ahsteven
em 3 abr. 2019
Olá, também recebi este erro.
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
em 17 abr. 2019
AlbertZhangHIT
em 17 abr. 2019
Infelizmente, também encontrei o mesmo problema.
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
Treinei meu modelo em um cluster de servidores e o erro aconteceu de forma imprevisível em um de meus servidores. Além disso, esse erro com fio só acontece em uma das minhas estratégias de treinamento. E a única diferença é que eu modifico o código durante o aumento dos dados e torno o pré-processamento dos dados mais complicado do que outros. Mas não tenho certeza de como resolver esse problema.
 qingyu-wang
em 25 abr. 2019
qingyu-wang
em 25 abr. 2019
Eu também estou tendo esse problema. Como resolver isso ??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
em 10 mai. 2019
nabil2i
em 10 mai. 2019
O mesmo problema aqui RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
em 16 mai. 2019
williamluke4
em 16 mai. 2019
@fmassa Você tem mais informações sobre isso?
williamluke4
em 18 mai. 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
O mesmo problema para mim
Caro, você conseguiu a solução?
(base) F: \ Suresh \ st-gcn> python main1.py reconhecimento -c config / st_gcn / ntu-xsub / train.yaml --device 0 --work_dir ./work_dir
C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ cuda__init __. Py: 117: UserWarning:
GPU0 TITAN Xp encontrado, que tem capacidade cuda 1.1.
O PyTorch não oferece mais suporte a esta GPU porque é muito antiga.
warnings.warn (old_gpu_warn% (d, nome, principal, capacidade [1]))
[05.22.19 | 12: 02: 41] Parâmetros:
{'base_lr': 0.1, 'ignore_weights': [], 'model': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0.0001, 'work_dir': './work_dir', 'save_interval ': 10,' model_args ': {' in_channels ': 3,' dropout ': 0.5,' num_class ': 60,' edge_importance_weighting ': True,' graph_args ': {' strategy ':' spatial ',' layout ': 'ntu-rgb + d'}}, 'debug': False, 'pavi_log': False, 'save_result': False, 'config': 'config / st_gcn / ntu-xsub / train.yaml', 'otimizador': 'SGD', 'pesos': Nenhum, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'etapa': [10, 50], 'use_gpu ': True,' phase ':' train ',' print_log ': True,' log_interval ': 100,' feeder ':' feeder.feeder.Feeder ',' start_epoch ': 0,' nesterov ': True,' device ': [0],' save_log ': True,' test_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/val_data.npy ',' label_path ':' ./data/NTU- RGB-D / xsub / val_label.pkl '},' train_feeder_args ': {' data_path ':' ./data/NTU-RGB-D/xsub/train_data.npy ',' debug ': False,' label_path ':' ./data/NTU-RGB-D/xsub/train_l abel.pkl '},' num_worker ': 4}
[02/05/19 | 12: 02: 41] Período de treinamento: 0
Traceback (última chamada mais recente):
Arquivo "main1.py", linha 31, em
p.start ()
Arquivo "F: \ Suresh \ st-gcn \ processor \ processor.py", linha 113, no início
self.train ()
Arquivo "F: \ Suresh \ st-gcn \ processor \ recognition.py", linha 91, em andamento
output = self.model (dados)
Arquivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", linha 489, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "F: \ Suresh \ st-gcn \ net \ st_gcn.py", linha 82, em frente
x, _ = gcn (x, auto.A * importância)
Arquivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", linha 489, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "F: \ Suresh \ st-gcn \ net \ st_gcn.py", linha 194, em frente
x, A = self.gcn (x, A)
Arquivo "C: \ Usuários \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", linha 489, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "F: \ Suresh \ st-gcn \ net \ utils \ tgcn.py", linha 60, em frente
x = self.conv (x)
Arquivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ module.py", linha 489, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "C: \ Users \ cudalab10 \ Anaconda3lib \ site-packages \ torch \ nn \ modules \ conv.py", linha 320, em diante
self.padding, self.dilation, self.groups)
RuntimeError: CUDA sem memória. Tentei alocar 1,37 GiB (GPU 0; 12,00 GiB de capacidade total; 8,28 GiB já alocados; 652,75 MiB livres; 664,38 MiB em cache)
 Sureshthommandru
em 22 mai. 2019
Sureshthommandru
em 22 mai. 2019
É porque o minilote de dados não cabe na memória da GPU. Apenas diminua o tamanho do lote. Ao definir o tamanho do lote = 256 para o conjunto de dados cifar10, obtive o mesmo erro; Então eu defino o tamanho do lote = 128, está resolvido.
 balcilar
em 1 jun. 2019
balcilar
em 1 jun. 2019
Sim @balcilar está certo, eu reduzi o tamanho do lote e agora funciona
 EKELE-NNOROM
em 4 jun. 2019
EKELE-NNOROM
em 4 jun. 2019
Eu tenho um problema semelhante:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
Estou usando 8 V100 para treinar o modelo. A parte confusa é que ainda há 3,03 GB em cache e não pode ser alocado para 11,88 MB.
 magic282
em 10 jun. 2019
magic282
em 10 jun. 2019
Você alterou o tamanho do lote. Reduza o tamanho do lote pela metade. Diga o lote
o tamanho é 16 para implementar, tente usar um tamanho de lote de 8 e veja se funciona.
Aproveitar
Na segunda-feira, 10 de junho de 2019 às 2h10, magic282 [email protected] escreveu:
Eu tenho um problema semelhante:
RuntimeError: CUDA sem memória. Tentei alocar 11,88 MiB (GPU 4; capacidade total de 15,75 GiB; 10,50 GiB já alocado; 1,88 MiB livre; 3,03 GiB em cache)
Estou usando 8 V100 para treinar o modelo. A parte confusa é que há
ainda 3,03 GB em cache e não pode ser alocado para 11,88 MB.-
Você está recebendo isto porque comentou.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODXJAK5Q#issuecomment-500303222 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
em 10 jun. 2019
Tentei reduzir o tamanho do lote e funcionou. A parte confusa é a mensagem de erro de que a memória em cache é maior do que a memória a ser alocada.
magic282
em 11 jun. 2019
Eu tenho o mesmo problema em um modelo pré-treinado, quando uso a previsão . Portanto, reduzir o tamanho do lote não funcionará.
 pvk444
em 30 jun. 2019
pvk444
em 30 jun. 2019
Se você atualizar para a versão mais recente do PyTorch, poderá ter menos erros como esse
fmassa
em 30 jun. 2019
Posso perguntar por que os números do erro não batem ?!
Eu (como todos vocês) recebo:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
Para mim, isso significa que o seguinte deve ser aproximadamente verdadeiro:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
Mas não é. O que é que estou entendendo de errado?
 AzimAhmadzadeh
em 3 jul. 2019
AzimAhmadzadeh
em 3 jul. 2019
Também tive o problema quando treinei o U-net, o cach é suficiente, mas ainda travar
 tongpinmo
em 10 jul. 2019
tongpinmo
em 10 jul. 2019
Eu tenho o mesmo erro...
RuntimeError: CUDA sem memória. Tentei alocar 312,00 MiB (GPU 0; capacidade total de 10,91 GiB; 1,07 GiB já alocado; 109,62 MiB livre; 15,21 MiB em cache)
 MSKazemi
em 10 jul. 2019
MSKazemi
em 10 jul. 2019
tente reduzir o tamanho (qualquer tamanho que não altere o resultado) funcionará.
 giangnguyen2412
em 11 jul. 2019
giangnguyen2412
em 11 jul. 2019
tente reduzir o tamanho (qualquer tamanho que não altere o resultado) funcionará.
Olá, mudo o batch_size para 1, mas não funciona!
 BCWang93
em 14 jul. 2019
BCWang93
em 14 jul. 2019
Você deve mudar outro tamanho.
Vào 21:50, CN, 14 Th7, 2019 Bcw93 [email protected] đã viết:
tente reduzir o tamanho (qualquer tamanho que não altere o resultado) funcionará.
Olá, mudo o batch_size para 1, mas não funciona!
-
Você está recebendo isto porque comentou.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGODZ4EWJI#issuecomment-511200037 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
em 15 jul. 2019
Obtendo este erro:
RuntimeError: CUDA sem memória. Tentei alocar 2,00 MiB (GPU 0; 7,94 GiB de capacidade total; 7,33 GiB já alocados; 1,12 MiB livre; 40,48 MiB em cache)
nvidia-smi
Qui, 22 de agosto, 21:05:52 2019
+ ------------------------------------------------- ---------------------------- +
| Versão do driver NVIDIA-SMI 430.40: 430.40 Versão CUDA: 10.1 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| Nome da GPU Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr: Uso / Tampa | Uso de memória | GPU-Util Compute M. |
| ================================= + ================= ===== + ====================== |
| 0 Quadro M4000 Desligado | 00000000: 09: 00.0 Ativado | N / A |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% Padrão |
+ ------------------------------- + ----------------- ----- + ---------------------- +
| 1 GeForce GTX 105 ... Desligado | 00000000: 41: 00.0 Ativado | N / A |
| 29% 33C P8 N / A / 75W | 262MiB / 4032MiB | 0% Padrão |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| Processos: Memória GPU |
| Tipo de GPU PID Nome do processo Uso |
| ========================================================= ============================== |
| 0 1909 G / usr / lib / xorg / Xorg 50MiB |
| 1 1909 G / usr / lib / xorg / Xorg 128MiB |
| 1 5236 G ... quest-channel-token = 9884100064965360199 130MiB |
+ ------------------------------------------------- ---------------------------- +
SO: Ubuntu 18.04 biônico
Kernel: x86_64 Linux 4.15.0-58-genérico
Tempo de atividade: 29m
Pacotes: 2002
Shell: bash 4.4.20
Resolução: 1920x1080 1080x1920
DE: LXDE
WM: OpenBox
Tema GTK: Lubuntu-default [GTK2]
Tema do ícone: Lubuntu
Fonte: Ubuntu 11
CPU: AMD Ryzen Threadripper 2970WX 24 núcleos @ 48x 3GHz [61,8 ° C]
GPU: Quadro M4000, GeForce GTX 1050 Ti
RAM: 3194 MiB / 64345 MiB
 danindiana
em 23 ago. 2019
danindiana
em 23 ago. 2019
Isso está consertado? Reduzi o tamanho e o tamanho do lote para 1. Não vejo nenhuma outra solução aqui, mas este tíquete está fechado. Estou tendo o mesmo problema com Cuda 10.1 Windows 10, Pytorch 1.2.0
 hughkf
em 6 set. 2019
hughkf
em 6 set. 2019
@hughkf Onde no código você altera batch_size?
 aidoshacks
em 6 set. 2019
aidoshacks
em 6 set. 2019
@aidoshacks , depende do seu código. Mas aqui está um exemplo. Este é um dos notebooks que causa esse problema de forma confiável em minha máquina: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb. Eu mudo a seguinte linha,
bs,size = 8,src_size//2 a bs,size = 1,1 mas ainda assim recebo este problema de falta de memória.
hughkf
em 6 set. 2019
Para mim, alterar batch_size de 128 para 64 funcionou, mas não parece uma solução divulgada para mim, ou estou faltando alguma coisa?
 shalgi
em 19 set. 2019
shalgi
em 19 set. 2019
Este problema foi resolvido? Eu também tenho o mesmo problema. Não mudei nada do meu código, mas depois de executar várias vezes, ocorre este erro:
"RuntimeError: CUDA sem memória. Tentativa de alocar 40,00 MiB (GPU 0; 15,77 GiB de capacidade total; 13,97 GiB já alocados; 256,00 KiB livres; 824,57 MiB em cache)"
 mengxiangming
em 26 set. 2019
mengxiangming
em 26 set. 2019
Ainda tendo esse problema, seria bom se o status fosse alterado para não resolvido.
EDITAR:
Tinha pouco a ver com o tamanho do lote, visto que eu o obtive com o tamanho do lote 1. Reiniciar o kernel corrigiu para mim e não aconteceu desde então.
 just-in-kees
em 29 set. 2019
just-in-kees
em 29 set. 2019
Então, qual é a resolução dos exemplos abaixo (ou seja, muita memória livre e tentar alocar muito pouco - o que é diferente de alguns exemplos neste tópico quando na verdade há pouca quantidade de mem livre e nada está errado)?
RuntimeError: CUDA sem memória. Tentei alocar 1,33 GiB (GPU 1; 31,72 GiB de capacidade total; 5,68 GiB já alocados; 24,94 GiB livres ; 5,96 MiB em cache)
Não vejo por que o problema foi para o status 'Fechado', pois ainda acontece na versão mais recente do pytorch (1.2) e GPU NVIDIA moderna (V-100)
Obrigado!
 yuribd
em 3 out. 2019
yuribd
em 3 out. 2019
Na maioria das vezes, você recebe essa mensagem de erro específica do pacote fastai porque está usando uma GPU incomumente pequena. Corrigi esse problema reiniciando meu kernel e usando um tamanho de lote menor para o caminho que você está fornecendo.
 AurioPinto
em 5 out. 2019
AurioPinto
em 5 out. 2019
mesmo problema aqui. Quando eu uso o pytorch0.4.1, tamanho do lote = 4, tudo bem. Mas quando eu mudo para pytorch1.3 e até mesmo defino o tamanho do lote para 1, eu tenho o problema de oom.
 Sarah20187
em 21 out. 2019
Sarah20187
em 21 out. 2019
resolvi isso atualizando meu pytorch para o mais recente ... conda update pytorch
 kafura0
em 21 out. 2019
kafura0
em 21 out. 2019
É porque o minilote de dados não cabe na memória da GPU. Apenas diminua o tamanho do lote. Ao definir o tamanho do lote = 256 para o conjunto de dados cifar10, obtive o mesmo erro; Então eu defino o tamanho do lote = 128, está resolvido.
obrigado, resolvi o erro dessa forma.
 zhangzibao
em 25 out. 2019
zhangzibao
em 25 out. 2019
Eu diminuí o batch_size para 8, ele funciona bem. A ideia é ter um pequeno batch_size
 Asutosh11
em 30 out. 2019
Asutosh11
em 30 out. 2019
Acho que depende do tamanho total da entrada com o qual uma determinada camada está lidando. Por exemplo, se um lote de 256 (32x32) imagens passar por 128 filtros em uma camada, o tamanho total de entrada é 256x32x32x128 = 2 ^ 25. Esse número deve estar abaixo de algum limite, que acho que é específico da máquina. Para AWS p3.2xlarge, por exemplo, é 2 ^ 26. Portanto, se você estiver obtendo erros de memória CuDA, tente reduzir o tamanho do lote ou o número de filtros ou colocar mais downsampling como stride ou camadas de pool
 souryadey
em 1 nov. 2019
souryadey
em 1 nov. 2019
Tem o mesmo problema:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
Com as últimas versões pytorch (1.3) e cuda (10.1). Nvidia-smi também mostra GPU meio vazio, então a quantidade de memória livre na mensagem de erro está correta. Ainda não é possível reproduzi-lo com um código simples
 ArgentumWalker
em 3 nov. 2019
ArgentumWalker
em 3 nov. 2019
Reinicializar o kernel funcionou para mim também! Não estava trabalhando nem com o tamanho do lote = 1 até que fiz isso
 kennethjmyers
em 7 nov. 2019
kennethjmyers
em 7 nov. 2019
Pessoal, resolvi meu problema reduzindo meu tamanho do lote pela metade.
 faizao
em 19 nov. 2019
faizao
em 19 nov. 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
Corrigido após reinicializar
 SomeUserName1
em 22 nov. 2019
SomeUserName1
em 22 nov. 2019
alterou batch_size 64 (rtx2080 ti) para 32 (rtx 2060), problema resolvido. mas quero saber outra maneira de resolver esse tipo de problema.
 sailfish009
em 3 dez. 2019
sailfish009
em 3 dez. 2019
Isso está acontecendo comigo quando faço a previsão !
Mudei o tamanho do lote de 1024 para 8 e ainda recebo erro quando 82% do conjunto de teste é avaliado.
Quando adicionei with torch.no_grad() o problema foi RESOLVIDO.
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
em 17 dez. 2019
smasoudn
em 17 dez. 2019
Eu resolvi o problema
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
para
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
em 27 dez. 2019
zhonghaochen
em 27 dez. 2019
Eu tive o mesmo problema e verifiquei a utilização da GPU em minha máquina. Já havia muito dele usado e muito menos memória sobrando. Eu matei meu notebook Jupyter e o reiniciei. a memória ficou livre e as coisas começaram a funcionar. Você pode usar abaixo:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
em 27 dez. 2019
prabhatsharma
em 27 dez. 2019
Eu também recebi esta mensagem:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)Aconteceu quando eu estava tentando executar o Fast.ai lição1 Animais de estimação https://course.fast.ai/ (célula 31)
Tente reduzir o tamanho do lote (bs) de seus dados de treinamento.
Veja o que funciona para você.
 rishi0904
em 27 dez. 2019
rishi0904
em 27 dez. 2019
Descobri que esse problema pode ser resolvido sem ajustar o tamanho do lote.
Abra o terminal e um prompt python
import torch
torch.cuda.empty_cache()
Saia do interpretador Python, execute novamente o comando PyTorch original e não deve (com sorte) gerar o erro de memória CUDA.
 cpoptic
em 3 jan. 2020
cpoptic
em 3 jan. 2020
Descobri que quando meu computador usa muita CPU RAM, esse problema geralmente surge. Portanto, quando queremos um tamanho de lote maior, podemos tentar reduzir o uso de RAM da CPU.
 dhKwang
em 13 jan. 2020
dhKwang
em 13 jan. 2020
Teve um problema semelhante.
Reduzir o tamanho do lote e reiniciar o kernel ajudou a resolver o problema.
 kumarnikhil936
em 19 jan. 2020
kumarnikhil936
em 19 jan. 2020
No meu caso, substituir o otimizador Adam pelo otimizador SGD resolveu o mesmo problema.
 tranvanluan2
em 23 jan. 2020
tranvanluan2
em 23 jan. 2020
Bem, no meu caso, usei with torch.no_grad(): (train model) , output.to("cpu") e torch.cuda.empty_cache() e este problema foi resolvido.
 PlanNoa
em 30 jan. 2020
PlanNoa
em 30 jan. 2020
RuntimeError: CUDA sem memória. Tentei alocar 54,00 MiB (GPU 0; 3,95 GiB de capacidade total; 2,65 GiB já alocados; 39,00 MiB livres; 87,29 MiB em cache)
Encontrei a solução e diminuo o valor batch_size.
 sagrawal06
em 30 jan. 2020
sagrawal06
em 30 jan. 2020
Estou treinando um YOLOv3 com pesos Darknet53 em um conjunto de dados personalizado. Minha GPU é uma NVIDIA RTX 2080 e eu estava enfrentando o mesmo problema. Mudar o tamanho do lote resolveu.
 wilderrodrigues
em 2 fev. 2020
wilderrodrigues
em 2 fev. 2020
Estou recebendo este erro durante o tempo de inferência ... estou ru
CUDA sem memória. Tentei alocar 102,00 MiB (GPU 0; 15,78 GiB de capacidade total; 14,54 GiB já alocados; 48,44 MiB livres; 14,67 GiB reservados no total por PyTorch)
-------------------------------------------------- --------------------------- +
| Versão do driver NVIDIA-SMI 440.59: 440.59 Versão CUDA: 10.2 |
| ------------------------------- + ----------------- ----- + ---------------------- +
| Nome da GPU Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr: Uso / Tampa | Uso de memória | GPU-Util Compute M. |
| ================================= + ================= ===== + ====================== |
| 0 Tesla V100-SXM2 ... Ligado | 00000000: 00: 1E.0 Desligado | 0 |
| N / A 35C P0 41W / 300W | 16112MiB / 16160MiB | 0% Padrão |
+ ------------------------------- + ----------------- ----- + ---------------------- +
+ ------------------------------------------------- ---------------------------- +
| Processos: Memória GPU |
| Tipo de GPU PID Nome do processo Uso |
| ========================================================= ============================== |
| 0 13978 C /.conda/envs/ / bin / python 16101MiB |
+ ------------------------------------------------- ---------------------------- +
 tvinith
em 29 fev. 2020
tvinith
em 29 fev. 2020
É porque o minilote de dados não cabe na memória da GPU. Apenas diminua o tamanho do lote. Ao definir o tamanho do lote = 256 para o conjunto de dados cifar10, obtive o mesmo erro; Então eu defino o tamanho do lote = 128, está resolvido.
obrigado, você está certo
 Rxma1805
em 2 mar. 2020
Rxma1805
em 2 mar. 2020
Para o caso específico, em que há memória de GPU suficiente, mas um erro ainda é gerado. No meu caso RESOLVEI reduzindo o número de trabalhadores no dataloader.
 Yurasyk
em 14 mar. 2020
Yurasyk
em 14 mar. 2020
Fundo
py36, pytorch1.4, tf2.0, conda
afinar a roberta
Edição
O problema é o mesmo que @EMarquer : o pycharm mostra que ainda tenho memória suficiente, porém a alocação de memória falhou, sem memória.
Maneiras que eu tentei
- "batch_size = 1" falhou
- "torch.cuda.empty_cache ()" falhou
- CUDA_VISIBLE_DEVICES = "0" python Run.py falhou
- Porque eu não uso o jupyter, não há necessidade de reiniciar o kernel
Forma de sucesso
- nvidia-smi


- A verdade é que o que o pycharm mostra é diferente do que "nvidia-smi" mostra (desculpe, eu não salvei a foto do pycharm), na verdade não há memória suficiente .
- Os processos 6123 e 32644 são executados no terminal antes.
- sudo kill -9 6123
- sudo kill -9 32644
 FernandoZhuang
em 17 mar. 2020
FernandoZhuang
em 17 mar. 2020
O que simplesmente funcionou para mim:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
em 6 abr. 2020
MastafaF
em 6 abr. 2020
Descobri que esse problema pode ser resolvido sem ajustar o tamanho do lote.
Abra o terminal e um prompt python
import torch torch.cuda.empty_cache()Saia do interpretador Python, execute novamente o comando PyTorch original e não deve (com sorte) gerar o erro de memória CUDA.
No meu caso, resolve meu problema.
 LiEAEX
em 10 abr. 2020
LiEAEX
em 10 abr. 2020
Certifique-se de usar sua GPU no slot 0 com --device_ids 0
Eu sei que estou massacrando a terminologia, mas funcionou. Acho que presume que você deseja usar a CPU em vez da GPU se você não selecionar um id.
 aaron387
em 12 abr. 2020
aaron387
em 12 abr. 2020
Estou recebendo o mesmo erro:
RuntimeError: CUDA sem memória. Tentei alocar 4,84 GiB (GPU 0; 7,44 GiB de capacidade total; 5,22 GiB já alocados; 1,75 GiB livres; 18,51 MiB em cache)
Quando eu reinicio o cluster ou altero o tamanho do lote, ele funciona. Mas não gosto dessa solução. Eu até tentei torch.cuda.empty_cache (), isso não funciona para mim. Existe alguma outra maneira eficiente de resolver isso?
 Tann10
em 13 abr. 2020
Tann10
em 13 abr. 2020
Não sei se meu cenário pode ser relacionado ao problema original, mas resolvi meu problema (o erro OOM na mensagem anterior foi embora) quebrando as camadas nn. Camadas sequenciais em meu modelo, por exemplo,
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)para
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))Meu modelo tem muito mais destes (mais 5 para ser exato). Estou usando nn.Sequential certo? Ou isso é um bug? @ yf225 @fmassa
Parece que também resolvo o erro semelhante, mas de maneira inversa com você.
Eu mudo tudo
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)para
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
em 14 abr. 2020
xml94
em 14 abr. 2020
Para mim, alterar batch_size ou qualquer uma das soluções fornecidas não ajudou. Mas descobri que no meu arquivo .cfg eu tinha valores errados de classes e filtro em uma camada. Portanto, se nada ajudar, verifique novamente o seu .cfg.
 ulaszewskim
em 1 mai. 2020
ulaszewskim
em 1 mai. 2020
Terminal aberto
Primeiro tipo
nvidia-smi
em seguida, selecione o PID que corresponde ao caminho python ou anaconda e escreva
sudo kill -9 PID
 krypticmouse
em 4 mai. 2020
krypticmouse
em 4 mai. 2020
Eu tenho tido esse bug há algum tempo. Para mim, continuo segurando uma variável Python (ou seja, tensor da tocha) que faz referência ao resultado do modelo e, portanto, não pode ser liberado com segurança, pois o código ainda pode acessá-lo.
Meu código é parecido com:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
A solução para isso foi transferir p para uma lista. Portanto, o código deve ser semelhante a:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
Isso garante que predictions mantenha os valores na memória principal, não um tensor na GPU.
 abdelrahmanhosny
em 8 mai. 2020
abdelrahmanhosny
em 8 mai. 2020
Estou tendo esse bug usando o módulo fastai.vision, que depende do pytorch. Estou usando CUDA 10.1
 jkomyno
em 16 mai. 2020
jkomyno
em 16 mai. 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
reduzir o per_gpu_train_batch_size de 16 para 8, resolveu meu problema.
 autodataming
em 3 jun. 2020
autodataming
em 3 jun. 2020
Se você atualizar para a versão mais recente do PyTorch, poderá ter menos erros como esse
realmente, por que você diz isso
 XinyingZheng
em 9 jun. 2020
XinyingZheng
em 9 jun. 2020
A principal questão dessa questão ainda é um problema em aberto. Estou recebendo a mesma mensagem CUDA estranha de memória insuficiente. Ele tentou alocar 2,26 GiB em 4,08 GiB grátis. Aparentemente, há memória suficiente, mas não consegue alocar.
Informações do projeto: treinar um resnet 10 sobre um conjunto de dados activitynet com tamanho de lote 4, ele falha no final da primeira época.
EDITADO: Algumas percepções: Se eu limpar minha memória RAM e apenas mantiver o código Python rodando, o erro não é gerado. Talvez haja memória suficiente na GPU, mas a memória RAM não é capaz de lidar com todas as outras etapas de processamento.
Informações do computador: Dell G5 - i7 9º - GTX 1660Ti 6 GB - 16 GB de RAM
EDITADO2: Eu estava usando "_MultiProcessingDataLoaderIter" com 4 trabalhadores e isso gerou a mensagem de memória insuficiente na chamada de encaminhamento. Se eu reduzir o número de trabalhadores para 1, não haverá erro. Com 1 trabalhador, o uso de memória RAM permanece 11/16 GB, com 4 aumenta para 14,5 / 16 GB. E com apenas 1 trabalhador, na verdade, posso aumentar o tamanho do lote para 32, aumentando a memória da GPU para 3,5 GB / 6 GB.
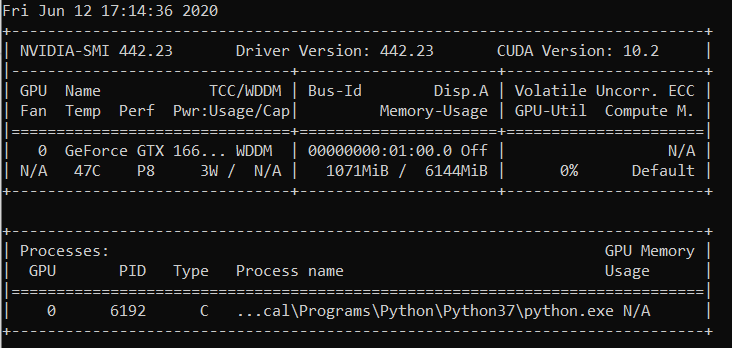
RuntimeError: CUDA sem memória. Tentei alocar 2,26 GiB (GPU 0; capacidade total de 6,00 GiB; 209,63 MiB já alocados; 4,08 GiB grátis; 246,00 MiB reservados no total por PyTorch)
Mensagem de erro completa
Traceback (última chamada mais recente):
Arquivo "main.py", linha 450, em
se opt.distributed:
Arquivo "main.py", linha 409, em main_worker
opt.device, current_lr, train_logger,
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ training.py", linha 37, em train_epoch
saídas = modelo (entradas)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", linha 532, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nnparallel \ data_parallel.py", linha 150, in forward
return self.module ( entradas [0], * kwargs [0])
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", linha 532, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py", linha 205, em forward
x = self.layer3 (x)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", linha 532, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ container.py", linha 100, a seguir
entrada = módulo (entrada)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", linha 532, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ models \ resnet.py", linha 51, em forward
out = self.conv2 (out)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ module.py", linha 532, em __call__
resultado = self.forward ( input, * kwargs)
Arquivo "D: \ Guilherme \ Google Drive \ Profissional \ Cursos \ Mestrado \ Pesquisa \ HMDB51 \ envlib \ site-packages \ torch \ nn \ modules \ conv.py", linha 480, a seguir
self.padding, self.dilation, self.groups)
RuntimeError: CUDA sem memória. Tentei alocar 2,26 GiB (GPU 0; capacidade total de 6,00 GiB; 209,63 MiB já alocados; 4,08 GiB grátis; 246,00 MiB reservados
no total por PyTorch)
 guilhermesurek
em 12 jun. 2020
guilhermesurek
em 12 jun. 2020
pequeno o tamanho do lote, funciona
 cuge1995
em 15 jun. 2020
cuge1995
em 15 jun. 2020
Eu tenho tido esse bug há algum tempo. Para mim, continuo segurando uma variável Python (ou seja, tensor da tocha) que faz referência ao resultado do modelo e, portanto, não pode ser liberado com segurança, pois o código ainda pode acessá-lo.
Meu código é parecido com:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)A solução para isso foi transferir
ppara uma lista. Portanto, o código deve ser semelhante a:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Isso garante que
predictionsmantenha os valores na memória principal, não um tensor na GPU.
@abdelrahmanhosny Obrigado por apontar isso. Enfrentei exatamente o mesmo problema no PyTorch 1.5.0 e não tive problemas de OOM durante o treinamento, no entanto, durante a inferência, também mantive segurando uma variável Python (ou seja, tensor da tocha) que referencia o resultado do modelo na memória, o que resultou na GPU ficando sem memória após um certo número de lotes.
No meu caso, porém, a transferência das previsões para a lista não funcionou, pois estou gerando imagens com minha rede, portanto, tive que fazer o seguinte:
predictions.append(p.detach().cpu().numpy())
Isso resolveu o problema!
 samkellerhals
em 19 jun. 2020
samkellerhals
em 19 jun. 2020
Existe alguma solução geral?
CUDA sem memória. Tentou alocar 196,00 MiB (GPU 0; capacidade total de 2,00 GiB; 359,38 MiB já alocado; 192,29 MiB livre; 152,37 MiB em cache)
Existe alguma solução geral?
CUDA sem memória. Tentou alocar 196,00 MiB (GPU 0; capacidade total de 2,00 GiB; 359,38 MiB já alocado; 192,29 MiB livre; 152,37 MiB em cache)
 manavkhadka0
em 24 jun. 2020
manavkhadka0
em 24 jun. 2020
Eu tenho tido esse bug há algum tempo. Para mim, continuo segurando uma variável Python (ou seja, tensor da tocha) que faz referência ao resultado do modelo e, portanto, não pode ser liberado com segurança, pois o código ainda pode acessá-lo.
Meu código é parecido com:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)A solução para isso foi transferir
ppara uma lista. Portanto, o código deve ser semelhante a:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())Isso garante que
predictionsmantenha os valores na memória principal, não um tensor na GPU.@abdelrahmanhosny Obrigado por apontar isso. Enfrentei exatamente o mesmo problema no PyTorch 1.5.0 e não tive problemas de OOM durante o treinamento, no entanto, durante a inferência, também mantive segurando uma variável Python (ou seja, tensor da tocha) que referencia o resultado do modelo na memória, o que resultou na GPU ficando sem memória após um certo número de lotes.
No meu caso, porém, a transferência das previsões para a lista não funcionou, pois estou gerando imagens com minha rede, portanto, tive que fazer o seguinte:
predictions.append(p.detach().cpu().numpy())Isso resolveu o problema!
Tenho o mesmo problema no modelo ParrallelWaveGAN e usei as soluções em # 16417, mas não funcionam para mim
y = self.model_gan (* x) .view (-1) .detach (). cpu (). numpy ()
gc.collect ()
torch.cuda.empty_cache ()
 tuong-olli
em 25 jun. 2020
tuong-olli
em 25 jun. 2020
Tive o mesmo problema durante o treinamento.
Coletar lixo e esvaziar a memória cuda após cada época resolveu o problema para mim.
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
em 5 ago. 2020
IsakWesterlundBitville
em 5 ago. 2020
O que simplesmente funcionou para mim:
import gc # Your code with pytorch using GPU gc.collect()
Obrigado!! Eu estava tendo problemas para executar o exemplo de Cães e gatos e isso funcionou para mim.
 Michelpayan
em 5 ago. 2020
Michelpayan
em 5 ago. 2020
Tive o mesmo problema durante o treinamento.
Coletar lixo e esvaziar a memória cuda após cada época resolveu o problema para mim.gc.collect() torch.cuda.empty_cache()
O mesmo para mim
 AleksandrTulenkov
em 6 ago. 2020
AleksandrTulenkov
em 6 ago. 2020
diminua o tamanho do lote e aumente as épocas. foi assim que resolvi.
 oyekamal
em 18 set. 2020
oyekamal
em 18 set. 2020
@areebsyed Verifique a memória RAM, tive esse problema ao definir muitos trabalhadores em paralelo.
guilhermesurek
em 29 set. 2020
Também estou recebendo o mesmo erro ao fazer o ajuste fino do bert2bert EncoderDecoderModel pré-treinado em pytorch no Colab sem nem mesmo concluir uma única época.
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
em 6 out. 2020
Aakash12980
em 6 out. 2020
@ Aakash12980 você tentou reduzir o tamanho do lote? Além disso, as imagens de entrada que você deseja treinar talvez tente redimensioná-las
 areebsyed
em 6 out. 2020
areebsyed
em 6 out. 2020
@areebsyed Sim, reduzi o tamanho do lote para 4 e funcionou.
Aakash12980
em 6 out. 2020
mesmo
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
em 7 out. 2020
monajalal
em 7 out. 2020
mesmo
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal tente reduzir o tamanho do lote ou o tamanho da dimensão de entrada.
Aakash12980
em 7 out. 2020
Então, qual é a resolução em exemplos como abaixo (ou seja, muita memória _free_ e tentando alocar muito pouco - o que é diferente de _alguns_ exemplos neste tópico quando na verdade há pouca quantidade de mem livre e nada está errado)?
RuntimeError: CUDA sem memória. Tentei alocar _ 1,33 GiB _ (GPU 1; 31,72 GiB de capacidade total; 5,68 GiB já alocados; _ 24,94 GiB livres _; 5,96 MiB em cache)
Não vejo por que o problema foi para o status 'Fechado', pois ainda acontece na versão mais recente do pytorch (1.2) e GPU NVIDIA moderna (V-100)
Obrigado!
Sim, sinto que a maioria das pessoas não percebe que o problema não é simplesmente OOM, é que há OOM enquanto o erro diz que há espaço livre suficiente. Estou enfrentando esse problema também no windows, encontrou alguma solução?
 YoadTew
em 6 nov. 2020
YoadTew
em 6 nov. 2020
Questões relacionadas
 a1363901216
·
3Comentários
a1363901216
·
3Comentários
 eliabruni
·
3Comentários
eliabruni
·
3Comentários
 kdexd
·
3Comentários
kdexd
·
3Comentários
 bartvm
·
3Comentários
bartvm
·
3Comentários
 mishraswapnil
·
3Comentários
mishraswapnil
·
3Comentários
Comentários muito úteis
É porque o minilote de dados não cabe na memória da GPU. Apenas diminua o tamanho do lote. Ao definir o tamanho do lote = 256 para o conjunto de dados cifar10, obtive o mesmo erro; Então eu defino o tamanho do lote = 128, está resolvido.