Pytorch: रनटाइम त्रुटि: CUDA स्मृति से बाहर। 12.50 MiB आवंटित करने का प्रयास किया (GPU 0; 10.92 GiB कुल क्षमता; 8.57 MiB पहले ही आवंटित; 9.28 GiB मुक्त; 4.68 MiB कैश्ड)
CUDA आउट ऑफ़ मेमोरी त्रुटि लेकिन CUDA मेमोरी लगभग खाली है
मैं वर्तमान में बहुत बड़ी मात्रा में टेक्स्ट डेटा (लगभग 70GiB टेक्स्ट) पर एक हल्के मॉडल का प्रशिक्षण दे रहा हूं।
उसके लिए मैं क्लस्टर पर एक मशीन का उपयोग कर रहा हूं ( ग्रिड 5000 क्लस्टर नेटवर्क का 'ग्रेल' )।
मैं 3 घंटे के प्रशिक्षण के बाद यह बहुत ही अजीब सीयूडीए आउट ऑफ मेमोरी त्रुटि संदेश प्राप्त कर रहा हूं:
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached) ।
संदेश के अनुसार, मेरे पास आवश्यक स्थान है लेकिन यह स्मृति आवंटित नहीं करता है।
कोई विचार यह क्या कारण हो सकता है?
जानकारी के लिए, मेरी प्रीप्रोसेसिंग फ्लाई पर डेटा को प्रीप्रोसेस करने के लिए मेरे स्रोत डेटा की तर्ज पर torch.multiprocessing.Queue और एक पुनरावर्तक पर निर्भर करती है।
पूर्ण स्टैकट्रेस
Traceback (most recent call last):
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1228, in <module>
exec_with_profiler(script_filename, prof, args.backend, script_args)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/memory_profiler.py", line 1129, in exec_with_profiler
exec(compile(f.read(), filename, 'exec'), ns, ns)
File "run.py", line 293, in <module>
main(args, save_folder, load_file)
File "run.py", line 272, in main
trainer.all_epochs()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 140, in all_epochs
self.single_epoch()
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 147, in single_epoch
tracker.add(*self.single_batch(data, target))
File "/home/emarquer/papud-bull-nn/trainer/trainer.py", line 190, in single_batch
result = self.model(data)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/papud-bull-nn/model/model.py", line 54, in forward
emb = self.emb(input)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/modules/sparse.py", line 118, in forward
self.norm_type, self.scale_grad_by_freq, self.sparse)
File "/home/emarquer/miniconda3/envs/pytorch/lib/python3.6/site-packages/torch/nn/functional.py", line 1454, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: CUDA out of memory. Tried to allocate 12.50 MiB (GPU 0; 10.92 GiB total capacity; 8.57 MiB already allocated; 9.28 GiB free; 4.68 MiB cached)
 EMarquer
EMarquer
सभी 91 टिप्पणियाँ
मेरे पास एक ही रनटाइम त्रुटि है:
Traceback (most recent call last):
File "carn\train.py", line 52, in <module>
main(cfg)
File "carn\train.py", line 48, in main
solver.fit()
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 95, in fit
psnr = self.evaluate("dataset/Urban100", scale=cfg.scale, num_step=self.step)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\solver.py", line 136, in evaluate
sr = self.refiner(lr_patch, scale).data
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 74, in forward
b3 = self.b3(o2)
File "C:\Program Files\Python37\lib\site-packages\torch\nn\modules\module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "C:\Users\Omar\Desktop\CARN-pytorch\carn\model\carn.py", line 30, in forward
c3 = torch.cat([c2, b3], dim=1)
RuntimeError: CUDA out of memory. Tried to allocate 195.25 MiB (GPU 0; 4.00 GiB total capacity; 2.88 GiB already allocated; 170.14 MiB free; 2.00 MiB cached)
 OmarBazaraa
27 जन॰ 2019
OmarBazaraa
27 जन॰ 2019
@EMarquer @OmarBazaraa क्या आप एक न्यूनतम
 yf225
28 जन॰ 2019
yf225
28 जन॰ 2019
मैं अब समस्या का पुनरुत्पादन नहीं कर सकता, इस प्रकार मैं इस मुद्दे को बंद कर दूंगा।
समस्या तब गायब हो गई जब मैंने रैम में प्रीप्रोसेस्ड डेटा को स्टोर करना बंद कर दिया।
@OmarBazaraa , मुझे नहीं लगता कि आपकी समस्या मेरी जैसी ही है, जैसे:
- मैं 12.50 MiB आवंटित करने का प्रयास कर रहा हूँ, 9.28 GiB मुक्त के साथ
- आप 170.14 एमआईबी मुक्त के साथ 195.25 एमआईबी आवंटित करने का प्रयास कर रहे हैं
इस समस्या के साथ मेरे पिछले अनुभव से, या तो आप CUDA मेमोरी को मुक्त नहीं करते हैं या आप CUDA पर बहुत अधिक डेटा डालने का प्रयास करते हैं।
CUDA मेमोरी को मुक्त न करके, मेरा मतलब है कि आपके पास संभावित रूप से अभी भी CUDA में टेनर्स के संदर्भ हैं जिनका आप अब उपयोग नहीं करते हैं। वे आवंटित स्मृति को टेंसरों को हटाकर मुक्त होने से रोकेंगे।
EMarquer
28 जन॰ 2019
क्या कोई सामान्य समाधान है?
CUDA स्मृति से बाहर। 196.00 MiB आवंटित करने का प्रयास किया (GPU 0; 2.00 GiB कुल क्षमता; 359.38 MiB पहले ही आवंटित; 192.29 MiB मुक्त; 152.37 MiB कैश्ड)
 aniketspurohit
31 जन॰ 2019
aniketspurohit
31 जन॰ 2019
@ aniks23 हम एक पैच पर काम कर रहे हैं जो मुझे विश्वास है कि इस मामले में बेहतर अनुभव देगा। बने रहें
 fmassa
31 जन॰ 2019
fmassa
31 जन॰ 2019
क्या यह जानने का कोई तरीका है कि मेरा सिस्टम कितना बड़ा मॉडल या नेटवर्क संभाल सकता है
इस मुद्दे में भागे बिना?
शुक्र, 1 फरवरी, 2019 को पूर्वाह्न 3:55 फ़्रांसिस्को मस्सा नोटिफिकेशन @github.com
लिखा था:
@aniks23 https://github.com/aniks23 हम एक ऐसे पैच पर काम कर रहे हैं जिसे मैं
विश्वास इस मामले में बेहतर अनुभव देगा। बने रहें-
आप इसे प्राप्त कर रहे हैं क्योंकि आपका उल्लेख किया गया था।
इस ईमेल का सीधे उत्तर दें, इसे GitHub पर देखें
https://github.com/pytorch/pytorch/issues/16417#issuecomment-459530332 ,
या थ्रेड को म्यूट करें
https://github.com/notifications/unsubscribe-auth/AUEJD4SYN4gnRkrLgFYEKY6y14P1TMgLks5vI21wgaJpZM4aUowv
.
aniketspurohit
1 फ़र॰ 2019
मुझे यह संदेश भी मिला:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)
यह तब हुआ जब मैं Fast.ai पाठ1 पेट्स https://course.fast.ai/ (सेल 31) चलाने की कोशिश कर रहा था।
 adrianovieira
12 मार्च 2019
adrianovieira
12 मार्च 2019
मैं भी उन्हीं त्रुटियों में भाग रहा हूं। मेरा मॉडल पहले सटीक सेटअप के साथ काम कर रहा था, लेकिन अब मैं कुछ असंबंधित कोड को संशोधित करने के बाद यह त्रुटि दे रहा हूं।
RuntimeError: CUDA out of memory. Tried to allocate 1.34 GiB (GPU 0; 22.41 GiB total capacity; 11.42 GiB already allocated; 59.19 MiB free; 912.00 KiB cached)
 treble-maker123
14 मार्च 2019
treble-maker123
14 मार्च 2019
मुझे नहीं पता कि मेरा परिदृश्य मूल मुद्दे से संबंधित है या नहीं, लेकिन मैंने अपनी समस्या का समाधान किया (पिछले संदेश में OOM त्रुटि चली गई) nn को तोड़कर। मेरे मॉडल में अनुक्रमिक परतें, जैसे
self.input_layer = nn.Sequential(
nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm3d(32),
nn.ReLU()
)
output = self.input_layer(x)
प्रति
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0)
self.input_bn = nn.BatchNorm3d(32)
output = F.relu(self.input_bn(self.input_conv(x)))
मेरे मॉडल में इनमें से बहुत कुछ है (सटीक होने के लिए 5 और)। क्या मैं nn.अनुक्रमिक अधिकार का उपयोग कर रहा हूँ? या यह एक बग है? @yf225 @fmassa
treble-maker123
14 मार्च 2019
मुझे भी इसी तरह की त्रुटि मिल रही है:
CUDA out of memory. Tried to allocate 196.50 MiB (GPU 0; 15.75 GiB total capacity; 7.09 GiB already allocated; 20.62 MiB free; 72.48 MiB cached)
@ ट्रेबल-मेकर123, क्या आप निर्णायक रूप से यह साबित करने में सक्षम हैं कि nn.Sequential समस्या है?
 yasheshgaur
17 मार्च 2019
yasheshgaur
17 मार्च 2019
मेरी भी इसी प्रकार की समस्या है। मैं pytorch dataloader का उपयोग कर रहा हूँ। कहते हैं मेरे पास 5 जीबी से अधिक मुफ्त होना चाहिए लेकिन यह 0 बाइट मुफ्त देता है।
रनटाइम त्रुटि ट्रेसबैक (सबसे हालिया कॉल अंतिम)
22
23 डेटा, इनपुट्स = स्टेट्स_इनपुट्स
---> 24 डेटा, इनपुट = वैरिएबल (डेटा)। फ्लोट ()। से (डिवाइस), वेरिएबल (इनपुट)। फ्लोट ()। से (डिवाइस)
25 प्रिंट (डेटा। डिवाइस)
26 enc_out = एन्कोडर (डेटा)
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 11.00 MiB आवंटित करने का प्रयास किया (GPU 0; 6.00 GiB कुल क्षमता; 448.58 MiB पहले ही आवंटित; 0 बाइट्स मुक्त; 942.00 KiB कैश्ड)
 ahsteven
3 अप्रैल 2019
ahsteven
3 अप्रैल 2019
नमस्ते, मुझे भी यह त्रुटि मिली है।
File "xxx", line 151, in __call__
logits = self.model(x_hat)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 67, in forward
x = up(x, blocks[-i-1])
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 120, in forward
out = self.conv_block(out)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "unet.py", line 92, in forward
out = self.block(x)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/container.py", line 92, in forward
input = module(input)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "anaconda3/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 320, in forward
self.padding, self.dilation, self.groups)
RuntimeError: CUDA out of memory. Tried to allocate 8.00 MiB (GPU 1; 11.78 GiB total capacity; 10.66 GiB already allocated; 1.62 MiB free; 21.86 MiB cached)
 AlbertZhangHIT
17 अप्रैल 2019
AlbertZhangHIT
17 अप्रैल 2019
दुख की बात है कि मैं भी इसी मुद्दे से मिला।
RuntimeError: CUDA out of memory. Tried to allocate 1.33 GiB (GPU 1; 31.72 GiB total capacity; 5.68 GiB already allocated; 24.94 GiB free; 5.96 MiB cached)
मैंने अपने मॉडल को सर्वरों के समूह में प्रशिक्षित किया है और त्रुटि अप्रत्याशित रूप से मेरे एक सर्वर में हुई है। साथ ही ऐसी वायर्ड त्रुटि केवल मेरी प्रशिक्षण रणनीतियों में से एक में होती है। और केवल अंतर यह है कि मैं डेटा वृद्धि के दौरान कोड को संशोधित करता हूं, और डेटा प्रीप्रोसेस को दूसरों की तुलना में अधिक जटिल बनाता हूं। लेकिन मुझे यकीन नहीं है कि इस समस्या को कैसे हल किया जाए।
 qingyu-wang
25 अप्रैल 2019
qingyu-wang
25 अप्रैल 2019
मुझे भी यह समस्या हो रही है। इसे कैसे हल करें??? RuntimeError: CUDA out of memory. Tried to allocate 18.00 MiB (GPU 0; 4.00 GiB total capacity; 2.94 GiB already allocated; 10.22 MiB free; 18.77 MiB cached)
 nabil2i
10 मई 2019
nabil2i
10 मई 2019
यहां वही समस्या RuntimeError: CUDA out of memory. Tried to allocate 54.00 MiB (GPU 0; 11.00 GiB total capacity; 7.89 GiB already allocated; 7.74 MiB free; 478.37 MiB cached)
 williamluke4
16 मई 2019
williamluke4
16 मई 2019
@fmassa क्या आपके पास इस बारे में और जानकारी है?
williamluke4
18 मई 2019
https://github.com/pytorch/pytorch/issues/16417#issuecomment -484264163
मेरे लिए एक ही मुद्दा
प्रिय, क्या आपको समाधान मिला?
(आधार) एफ: सुरेश
C:\Users\cudalab10\Anaconda3lib\site-packages\torch\cuda__init__.py:117: UserWarning:
GPU0 TITAN Xp मिला जो कि cuda क्षमता 1.1 का है।
PyTorch अब इस GPU का समर्थन नहीं करता है क्योंकि यह बहुत पुराना है।
चेतावनियाँ। चेतावनी (old_gpu_warn% (d, नाम, प्रमुख, क्षमता [1]))
[05.22.19|12:02:41] पैरामीटर्स:
{'base_lr': 0.1, 'ignore_weights': [], 'मॉडल': 'net.st_gcn.Model', 'eval_interval': 5, 'weight_decay': 0.0001, 'work_dir': './work_dir', 'save_interval' ': 10, 'model_args': {'in_channels': 3, 'ड्रॉपआउट': 0.5, 'num_class': 60, 'edge_importance_weighting': True, 'graph_args': {'strategy': 'spatial', 'layout': 'ntu-rgb+d'}}, 'डीबग': गलत, 'pavi_log': गलत, 'save_result': गलत, 'कॉन्फ़िगरेशन': 'config/st_gcn/ntu-xsub/train.yaml', 'ऑप्टिमाइज़र': 'SGD', 'वेट': कोई नहीं, 'num_epoch': 80, 'batch_size': 64, 'show_topk': [1, 5], 'test_batch_size': 64, 'स्टेप': [10, 50], 'use_gpu ': ट्रू, 'फेज': 'ट्रेन', 'प्रिंट_लॉग': ट्रू, 'लॉग_इंटरवल': 100, 'फीडर': 'फीडर.फीडर.फीडर', 'स्टार्ट_एपोच': 0, 'नेस्टरोव': ट्रू, 'डिवाइस' ': [0], 'save_log': सच, 'test_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/val_data.npy', 'label_path': './data/NTU- RGB-D/xsub/val_label.pkl'}, 'train_feeder_args': {'data_path': './data/NTU-RGB-D/xsub/train_data.npy', 'debug': False, 'label_path': ' ./डेटा/एनटीयू-आरजीबी-डी/xsub/train_l abel.pkl'}, 'num_worker': 4}
[05.22.19|12:02:41] प्रशिक्षण युग: 0
ट्रेसबैक (सबसे हालिया कॉल अंतिम):
फ़ाइल "main1.py", लाइन 31, in
पी.स्टार्ट ()
फ़ाइल "F:\सुरेश\st-gcn\processor\processor.py", लाइन 113, प्रारंभ में
सेल्फ.ट्रेन ()
फ़ाइल "F:\सुरेश\st-gcn\प्रोसेसर\रिकग्निशन.py", लाइन 91, ट्रेन में
आउटपुट = स्वयं मॉडल (डेटा)
फ़ाइल "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", लाइन 489, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "F:\सुरेश\st-gcn\net\st_gcn.py", पंक्ति 82, आगे की ओर
एक्स, _ = जीसीएन (एक्स, स्वयं। ए * महत्व)
फ़ाइल "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", लाइन 489, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "F:\सुरेश\st-gcn\net\st_gcn.py", पंक्ति 194, आगे की ओर
एक्स, ए = स्वयं जीसीएन (एक्स, ए)
फ़ाइल "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", लाइन 489, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "F:\सुरेश\st-gcn\net\utils\tgcn.py", लाइन 60, आगे की ओर
एक्स = स्व.रूपांतरण (एक्स)
फ़ाइल "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\module.py", लाइन 489, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "C:\Users\cudalab10\Anaconda3lib\site-packages\torch\nn\modules\conv.py", लाइन 320, आगे की ओर
सेल्फ़.पैडिंग, सेल्फ़.डीलेशन, सेल्फ़.ग्रुप्स)
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 1.37 GiB आवंटित करने का प्रयास किया (GPU 0; 12.00 GiB कुल क्षमता; 8.28 GiB पहले से ही आवंटित; 652.75 MiB मुक्त; 664.38 MiB कैश्ड)
 Sureshthommandru
22 मई 2019
Sureshthommandru
22 मई 2019
ऐसा इसलिए है क्योंकि डेटा का मिनी-बैच GPU मेमोरी में फिट नहीं होता है। बस बैच का आकार कम करें। जब मैंने cifar10 डेटासेट के लिए बैच आकार = 256 सेट किया तो मुझे वही त्रुटि मिली; फिर मैंने बैच आकार = 128 सेट किया, यह हल हो गया है।
 balcilar
1 जून 2019
balcilar
1 जून 2019
हाँ @balcilar सही है, मैंने बैच का आकार कम कर दिया है और अब यह काम करता है
 EKELE-NNOROM
4 जून 2019
EKELE-NNOROM
4 जून 2019
मेरा भी वही मुद्दा है:
RuntimeError: CUDA out of memory. Tried to allocate 11.88 MiB (GPU 4; 15.75 GiB total capacity; 10.50 GiB already allocated; 1.88 MiB free; 3.03 GiB cached)
मैं मॉडल को प्रशिक्षित करने के लिए 8 V100 का उपयोग कर रहा हूं। भ्रमित करने वाला हिस्सा यह है कि अभी भी 3.03GB कैश्ड है और इसे 11.88MB के लिए आवंटित नहीं किया जा सकता है।
 magic282
10 जून 2019
magic282
10 जून 2019
क्या आपने बैच का आकार बदल दिया है। बैच का आकार आधा कर दें। बैच कहो
आकार 16 लागू करने के लिए है, 8 के बैच आकार का उपयोग करने का प्रयास करें और देखें कि यह काम करता है या नहीं।
आनंद लेना
सोम, जून 10, 2019 को दोपहर 2:10 बजे मैजिक282 नोटिफिकेशन @github.com ने लिखा:
मेरा भी वही मुद्दा है:
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 11.88 एमआईबी आवंटित करने का प्रयास किया (जीपीयू 4; 15.75 जीआईबी कुल क्षमता; 10.50 जीआईबी पहले ही आवंटित; 1.88 एमआईबी मुक्त; 3.03 जीबी कैश्ड)
मैं मॉडल को प्रशिक्षित करने के लिए 8 V100 का उपयोग कर रहा हूं। भ्रमित करने वाला हिस्सा यह है कि वहाँ है
अभी भी 3.03GB कैश्ड है और इसे 11.88MB के लिए आवंटित नहीं किया जा सकता है।-
आप इसे प्राप्त कर रहे हैं क्योंकि आपने टिप्पणी की थी।
इस ईमेल का सीधे उत्तर दें, इसे GitHub पर देखें
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AGGVQNIXGPJ3HXGSVRPOYUTPZXV5NA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW#TNMVW500XHJ
या थ्रेड को म्यूट करें
https://github.com/notifications/unsubscribe-auth/AGGVQNPVGT5RLM6ZV5KMSULPZXV5NANCNFSM4GSSRQXQ
.
EKELE-NNOROM
10 जून 2019
मैंने बैच के आकार को कम करने की कोशिश की और यह काम कर गया। भ्रमित करने वाला हिस्सा त्रुटि संदेश है कि कैश्ड मेमोरी आवंटित की जाने वाली मेमोरी से बड़ी है।
magic282
11 जून 2019
जब मैं भविष्यवाणी का उपयोग करता हूं, तो मुझे एक पूर्व-प्रशिक्षित मॉडल पर एक ही समस्या मिलती है। इसलिए बैच का आकार कम करने से काम नहीं चलेगा।
 pvk444
30 जून 2019
pvk444
30 जून 2019
यदि आप PyTorch के नवीनतम संस्करण में अपडेट करते हैं तो आपके पास उस तरह की कम त्रुटियां हो सकती हैं
fmassa
30 जून 2019
क्या मैं पूछ सकता हूँ कि त्रुटि में संख्याएँ क्यों नहीं जुड़ती हैं ?!
मुझे (आप सभी की तरह) मिलता है:
Tried to allocate 20.00 MiB (GPU 0; 1.95 GiB total capacity; 763.17 MiB already allocated; 6.31 MiB free; 28.83 MiB cached)
मेरे लिए इसका मतलब है कि निम्नलिखित लगभग सत्य होना चाहिए:
1.95 (GB total) - 20 (MiB needed) == 763.17 (MiB already used) + 6.31 (MiB free) + 28.83 (MiB cached)
लेकिन यह नहीं है। मैं क्या गलत कर रहा हूँ?
 AzimAhmadzadeh
3 जुल॰ 2019
AzimAhmadzadeh
3 जुल॰ 2019
जब मैंने यू-नेट को प्रशिक्षित किया तो मुझे भी समस्या हुई, कैश पर्याप्त है, लेकिन यह अभी भी दुर्घटनाग्रस्त है
 tongpinmo
10 जुल॰ 2019
tongpinmo
10 जुल॰ 2019
मुझे एक ही त्रुटि है ...
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 312.00 MiB आवंटित करने का प्रयास किया (GPU 0; 10.91 GiB कुल क्षमता; 1.07 GiB पहले से ही आवंटित; 109.62 MiB मुक्त; 15.21 MiB कैश्ड)
 MSKazemi
10 जुल॰ 2019
MSKazemi
10 जुल॰ 2019
आकार कम करने का प्रयास करें (कोई भी आकार जो परिणाम नहीं बदलेगा) काम करेगा।
 giangnguyen2412
11 जुल॰ 2019
giangnguyen2412
11 जुल॰ 2019
आकार कम करने का प्रयास करें (कोई भी आकार जो परिणाम नहीं बदलेगा) काम करेगा।
हैलो, मैं बैच_साइज को 1 में बदलता हूं, लेकिन यह काम नहीं करता है!
 BCWang93
14 जुल॰ 2019
BCWang93
14 जुल॰ 2019
क्या आपको दूसरा आकार बदलना चाहिए।
वीओ 21:50, सीएन, 14 थ7, 2019 बीसीडब्ल्यू93 नोटिफिकेशन @github.com viết:
आकार कम करने का प्रयास करें (कोई भी आकार जो परिणाम नहीं बदलेगा) काम करेगा।
हैलो, मैं बैच_साइज को 1 में बदलता हूं, लेकिन यह काम नहीं करता है!
-
आप इसे प्राप्त कर रहे हैं क्योंकि आपने टिप्पणी की थी।
इस ईमेल का सीधे उत्तर दें, इसे GitHub पर देखें
https://github.com/pytorch/pytorch/issues/16417?email_source=notifications&email_token=AHLNPF7MWQ7U5ULGIT44VRTP7MOKFA5CNFSM4GSSRQX2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LN37WZWZ5K
या थ्रेड को म्यूट करें
https://github.com/notifications/unsubscribe-auth/AHLNPF4227GHH32PI4WC4SDP7MOKFANCNFSM4GSSRQXQ
.
giangnguyen2412
15 जुल॰ 2019
यह त्रुटि प्राप्त करना:
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 2.00 MiB आवंटित करने का प्रयास किया (GPU 0; 7.94 GiB कुल क्षमता; 7.33 GiB पहले ही आवंटित; 1.12 MiB मुक्त; 40.48 MiB कैश्ड)
एनवीडिया-एसएमआई
गुरु अगस्त 22 21:05:52 2019
+-------------------------------------------------------- -----------------------------+
| NVIDIA-SMI 430.40 ड्राइवर संस्करण: 430.40 CUDA संस्करण: 10.1 |
|------------------------------------------+----------------- -----+---------------------+
| GPU नाम पर्सिस्टेंस-एम| बस-आईडी डिस्प.ए | अस्थिर ईसीसी |
| फैन टेम्प परफ पीआर: उपयोग/कैप | मेमोरी-उपयोग | जीपीयू-यूटिल कंप्यूट एम. |
|=============================+================ =====+======================|
| 0 क्वाड्रो M4000 ऑफ | 00000000:09: 00.0 पर | एन/ए |
| 46% 37C P8 12W / 120W | 71MiB / 8126MiB | 10% डिफ़ॉल्ट |
+---------------------------------------------------------------------- -----+---------------------+
| 1 GeForce GTX 105... ऑफ | 00000000:41:00.0 पर | एन/ए |
| 29% 33सी पी8 एन/ए / 75डब्ल्यू | 262MiB / 4032MiB | 0% डिफ़ॉल्ट |
+---------------------------------------------------------------------- -----+---------------------+
+-------------------------------------------------------- -----------------------------+
| प्रक्रियाएं: जीपीयू मेमोरी |
| GPU PID प्रकार प्रक्रिया का नाम उपयोग |
|============================================ ===========================|
| 0 1909 जी /usr/lib/xorg/Xorg 50MiB |
| 1 1909 जी /usr/lib/xorg/Xorg 128MiB |
| 1 5236 जी ...खोज-चैनल-टोकन=9884100064965360199 130MiB |
+-------------------------------------------------------- -----------------------------+
ओएस: उबंटू 18.04 बायोनिक
कर्नेल: x86_64 लिनक्स 4.15.0-58-जेनेरिक
अपटाइम: 29m
पैकेज: 2002
शैल: बैश 4.4.20
संकल्प: 1920x1080 1080x1920
डे: एलएक्सडीई
डब्ल्यूएम: ओपनबॉक्स
GTK थीम: लुबंटू-डिफॉल्ट [GTK2]
आइकन थीम: लुबंटू
फ़ॉन्ट: उबंटू 11
CPU: AMD Ryzen Threadripper 2970WX 24-कोर @ 48x 3GHz [61.8°C]
GPU: क्वाड्रो M4000, GeForce GTX 1050 Ti
रैम: 3194MiB / 64345MiB
 danindiana
23 अग॰ 2019
danindiana
23 अग॰ 2019
क्या यह तय है? मैंने आकार और बैच आकार दोनों को घटाकर 1 कर दिया है। मुझे यहां कोई अन्य समाधान नहीं दिख रहा है, लेकिन यह टिकट बंद है। मुझे Cuda 10.1 Windows 10, Pytorch 1.2.0 . के साथ भी यही समस्या हो रही है
 hughkf
6 सित॰ 2019
hughkf
6 सित॰ 2019
@hughkf कोड में आप
 aidoshacks
6 सित॰ 2019
aidoshacks
6 सित॰ 2019
@aidoshacks , यह आपके कोड पर निर्भर करता है। लेकिन यहाँ एक उदाहरण है। यह उन नोटबुक्स में से एक है जो मज़बूती से मेरी मशीन पर इस समस्या का कारण बनती है: https://github.com/fastai/course-v3/blob/master/nbs/dl1/lesson3-camvid-tiramisu.ipynb। मैं निम्नलिखित पंक्ति बदलता हूं,
bs,size = 8,src_size//2 से bs,size = 1,1 लेकिन फिर भी मैं इसे स्मृति समस्या से बाहर निकालता हूं।
hughkf
6 सित॰ 2019
मेरे लिए बैच_साइज़ को 128 से 64 में बदलने से काम चल गया, लेकिन यह मेरे लिए एक खुला समाधान नहीं लगता है, या क्या मुझे कुछ याद आ रहा है?
 shalgi
19 सित॰ 2019
shalgi
19 सित॰ 2019
क्या यह समस्या हल हो गई है? मुझे भी यही समस्या हुई। मैंने अपने कोड में कुछ भी नहीं बदला, लेकिन कई बार चलने के बाद, यह त्रुटि होती है:
"रनटाइम त्रुटि: CUDA मेमोरी से बाहर। 40.00 MiB (GPU 0; 15.77 GiB कुल क्षमता; 13.97 GiB पहले से आवंटित; 256.00 KiB मुक्त; 824.57 MiB कैश्ड)" आवंटित करने का प्रयास किया गया।
 mengxiangming
26 सित॰ 2019
mengxiangming
26 सित॰ 2019
अभी भी यह समस्या है, अच्छा होगा यदि स्थिति को अनसुलझे में बदल दिया जाएगा।
संपादित करें:
बैच आकार के साथ बहुत कम करना था क्योंकि मैं इसे बैच आकार 1 के साथ प्राप्त करता हूं। कर्नेल को पुनरारंभ करने से यह मेरे लिए तय हो गया है और यह तब से नहीं हुआ है।
 just-in-kees
29 सित॰ 2019
just-in-kees
29 सित॰ 2019
तो नीचे दिए गए उदाहरणों पर संकल्प क्या है (यानी बहुत सारी मुफ्त मेमोरी और बहुत कम आवंटित करने की कोशिश कर रहा है - जो इस धागे में कुछ उदाहरणों से अलग है जब वास्तव में मुफ्त मेम की थोड़ी मात्रा होती है और कुछ भी गलत नहीं होता है)?
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 1.33 GiB आवंटित करने का प्रयास किया (GPU 1; 31.72 GiB कुल क्षमता; 5.68 GiB पहले ही आवंटित; 24.94 GiB मुक्त ; 5.96 MiB कैश्ड)
मुझे नहीं पता कि मुद्दा 'बंद' स्थिति में क्यों गया, क्योंकि यह अभी भी नवीनतम पाइटोरच वर् (1.2) और आधुनिक एनवीआईडीआईए जीपीयू (वी -100) पर होता है।
धन्यवाद!
 yuribd
3 अक्तू॰ 2019
yuribd
3 अक्तू॰ 2019
अधिकांश समय आपको यह विशेष त्रुटि संदेश fastai पैकेज से मिलता है क्योंकि आप असामान्य रूप से छोटे GPU का उपयोग कर रहे हैं। मैंने अपने कर्नेल को पुनरारंभ करके और आपके द्वारा दिए जा रहे पथ के लिए एक छोटे बैच आकार का उपयोग करके इस समस्या को ठीक किया।
 AurioPinto
5 अक्तू॰ 2019
AurioPinto
5 अक्तू॰ 2019
वही समस्या है। जब मैं pytorch0.4.1, बैच आकार = 4 का उपयोग करता हूं, तो यह ठीक है। लेकिन जब मैं pytorch1.3 में बदलता हूं और यहां तक कि बैच का आकार 1 पर सेट करता हूं, तो मुझे समस्या का सामना करना पड़ता है।
 Sarah20187
21 अक्तू॰ 2019
Sarah20187
21 अक्तू॰ 2019
मेरे pytorch को नवीनतम में अपडेट करके इसे हल किया... conda update pytorch
 kafura0
21 अक्तू॰ 2019
kafura0
21 अक्तू॰ 2019
ऐसा इसलिए है क्योंकि डेटा का मिनी-बैच GPU मेमोरी में फिट नहीं होता है। बस बैच का आकार कम करें। जब मैंने cifar10 डेटासेट के लिए बैच आकार = 256 सेट किया तो मुझे वही त्रुटि मिली; फिर मैंने बैच आकार = 128 सेट किया, यह हल हो गया है।
धन्यवाद, मैंने इस तरह से त्रुटि को संबोधित किया।
 zhangzibao
25 अक्तू॰ 2019
zhangzibao
25 अक्तू॰ 2019
मैंने बैच_साइज़ को घटाकर 8 कर दिया, यह ठीक काम करता है। एक छोटा बैच_साइज रखने का विचार है
 Asutosh11
30 अक्तू॰ 2019
Asutosh11
30 अक्तू॰ 2019
मुझे लगता है कि यह कुल इनपुट आकार पर निर्भर करता है जिससे एक विशेष परत काम कर रही है। उदाहरण के लिए, यदि 256 (32x32) छवियों का एक बैच एक परत में 128 फ़िल्टर से गुजरता है, तो कुल इनपुट आकार 256x32x32x128 = 2^25 है। यह संख्या कुछ दहलीज से नीचे होनी चाहिए, जो मुझे लगता है कि मशीन विशिष्ट है। उदाहरण के लिए AWS p3.2xlarge के लिए, यह 2^26 है। इसलिए यदि आपको CuDA मेमोरी त्रुटियाँ मिल रही हैं, तो बैच आकार या फ़िल्टर की संख्या को कम करने का प्रयास करें या स्ट्राइड या पूलिंग लेयर्स की तरह अधिक डाउनसैंपलिंग डालें
 souryadey
1 नव॰ 2019
souryadey
1 नव॰ 2019
एक ही समस्या है:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 0 bytes already allocated; 3.83 GiB free; 0 bytes cached)
नवीनतम पाइटोरच (1.3) और क्यूडा (10.1) संस्करण के साथ। एनवीडिया-एसएमआई आधा खाली जीपीयू भी दिखाता है, इसलिए त्रुटि संदेश में मुफ्त मेमोरी की मात्रा सही है। इसे अभी तक सरल कोड के साथ पुन: पेश नहीं किया जा सकता
 ArgentumWalker
3 नव॰ 2019
ArgentumWalker
3 नव॰ 2019
कर्नेल को रीसेट करना मेरे लिए भी काम कर गया! बैच आकार = 1 के साथ भी काम नहीं कर रहा था जब तक कि मैंने ऐसा नहीं किया
 kennethjmyers
7 नव॰ 2019
kennethjmyers
7 नव॰ 2019
दोस्तों, मैंने अपने बैच को आधे से कम करने की अपनी समस्या का समाधान किया।
 faizao
19 नव॰ 2019
faizao
19 नव॰ 2019
RuntimeError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 3.95 GiB total capacity; 0 bytes already allocated; 2.02 GiB free; 0 bytes cached)
रिबूट करने के बाद फिक्स्ड
 SomeUserName1
22 नव॰ 2019
SomeUserName1
22 नव॰ 2019
बैच_साइज़ 64 (rtx2080 ti) से 32 (rtx 2060) में बदला गया, समस्या हल हो गई। लेकिन मैं इस तरह की समस्या को हल करने का दूसरा तरीका जानना चाहता हूं।
 sailfish009
3 दिस॰ 2019
sailfish009
3 दिस॰ 2019
यह मेरे साथ हो रहा है जब मैं भविष्यवाणी करता हूँ !
मैंने बैच का आकार 1024 से बदलकर 8 कर दिया है और 82% परीक्षण सेट का मूल्यांकन होने पर भी त्रुटि हो रही है।
जब मैंने with torch.no_grad() जोड़ा तो समस्या का समाधान हो गया।
test_loader = init_data_loader(X_test, y_test, torch.device('cpu'), batch_size, num_workers=0)
print("Starting inference ...")
result = []
model.eval()
valid_loss = 0
with torch.no_grad():
for batch_x, batch_y in tqdm(test_loader):
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
output = model(batch_x)
result.extend(output[:, 0, 0])
loss = torch.sqrt(criterion(output, batch_y))
valid_loss += loss
valid_loss /= len(train_loader)
print("Done!")
 smasoudn
17 दिस॰ 2019
smasoudn
17 दिस॰ 2019
मैंने समस्या हल की
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=4)
प्रति
loader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=4)
 zhonghaochen
27 दिस॰ 2019
zhonghaochen
27 दिस॰ 2019
मेरे पास एक ही समस्या थी और मैंने अपनी मशीन पर GPU उपयोग की जाँच की। इसका बहुत कुछ पहले से ही उपयोग किया जा चुका था और बहुत कम मात्रा में स्मृति बची थी। मैंने अपनी ज्यूपिटर नोटबुक को मार डाला और इसे पुनः आरंभ किया। स्मृति मुक्त हो गई और चीजें काम करने लगीं। आप नीचे उपयोग कर सकते हैं:
nvidia-smi - To check the memory utilization on GPU
ps -ax | grep jupyter - To get PID of jupyter process
sudo kill PID
 prabhatsharma
27 दिस॰ 2019
prabhatsharma
27 दिस॰ 2019
मुझे यह संदेश भी मिला:
RuntimeError: CUDA out of memory. Tried to allocate 32.75 MiB (GPU 0; 4.93 GiB total capacity; 3.85 GiB already allocated; 29.69 MiB free; 332.48 MiB cached)यह तब हुआ जब मैं Fast.ai पाठ1 पेट्स https://course.fast.ai/ (सेल 31) चलाने की कोशिश कर रहा था।
अपने प्रशिक्षण डेटा के बैच आकार (बीएस) को कम करने का प्रयास करें।
देखें कि आपके लिए क्या काम करता है।
 rishi0904
27 दिस॰ 2019
rishi0904
27 दिस॰ 2019
मैंने आपके बैच आकार को समायोजित किए बिना इस समस्या को हल करने योग्य पाया।
ओपन टर्मिनल और एक पायथन प्रॉम्प्ट
import torch
torch.cuda.empty_cache()
पायथन दुभाषिया से बाहर निकलें, अपने मूल PyTorch कमांड को फिर से चलाएं और इसे (उम्मीद है) CUDA मेमोरी त्रुटि नहीं देनी चाहिए।
 cpoptic
3 जन॰ 2020
cpoptic
3 जन॰ 2020
मुझे पता चला कि जब मेरा कंप्यूटर बहुत अधिक CPU RAM का उपयोग करता है, तो यह समस्या आमतौर पर सामने आती है। इसलिए जब हम एक बड़ा बैच आकार चाहते हैं, तो हम CPU RAM के उपयोग को कम करने का प्रयास कर सकते हैं।
 dhKwang
13 जन॰ 2020
dhKwang
13 जन॰ 2020
इसी तरह का मुद्दा था।
बैच आकार को कम करने और कर्नेल को पुनरारंभ करने से समस्या को हल करने में मदद मिली।
 kumarnikhil936
19 जन॰ 2020
kumarnikhil936
19 जन॰ 2020
मेरे मामले में, एडम ऑप्टिमाइज़र को SGD ऑप्टिमाइज़र द्वारा बदलने से वही समस्या हल हो गई।
 tranvanluan2
23 जन॰ 2020
tranvanluan2
23 जन॰ 2020
ठीक है, मेरे मामले में, with torch.no_grad(): (train model) , output.to("cpu") और torch.cuda.empty_cache() और यह समस्या हल हो गई।
 PlanNoa
30 जन॰ 2020
PlanNoa
30 जन॰ 2020
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 54.00 MiB आवंटित करने का प्रयास किया (GPU 0; 3.95 GiB कुल क्षमता; 2.65 GiB पहले से ही आवंटित; 39.00 MiB मुक्त; 87.29 MiB कैश्ड)
मुझे समाधान मिला और मैं बैच_साइज मान घटाता हूं।
 sagrawal06
30 जन॰ 2020
sagrawal06
30 जन॰ 2020
मैं एक कस्टम डेटासेट पर Darknet53 भार के साथ एक YOLOv3 का प्रशिक्षण ले रहा हूं। मेरा GPU एक NVIDIA RTX 2080 है और मैं उसी मुद्दे का सामना कर रहा था। बैच आकार बदलने से इसे हल किया गया।
 wilderrodrigues
2 फ़र॰ 2020
wilderrodrigues
2 फ़र॰ 2020
मुझे यह त्रुटि अनुमान समय के दौरान मिल रही है .... मैं ru . हूँ
CUDA स्मृति से बाहर। 102.00 MiB आवंटित करने का प्रयास किया (GPU 0; 15.78 GiB कुल क्षमता; 14.54 GiB पहले ही आवंटित; 48.44 MiB मुक्त; 14.67 GiB कुल मिलाकर PyTorch द्वारा आरक्षित)
-------------------------------------------------- ---------------------------+
| NVIDIA-SMI 440.59 ड्राइवर संस्करण: 440.59 CUDA संस्करण: 10.2 |
|------------------------------------------+----------------- -----+---------------------+
| GPU नाम पर्सिस्टेंस-एम| बस-आईडी डिस्प.ए | अस्थिर ईसीसी |
| फैन टेम्प परफ पीआर: उपयोग/कैप | मेमोरी-उपयोग | जीपीयू-यूटिल कंप्यूट एम. |
|=============================+================ =====+======================|
| 0 टेस्ला V100-SXM2... ऑन | 00000000:00:1E.0 बंद | 0 |
| एन/ए 35सी पी0 41डब्ल्यू / 300डब्ल्यू | 16112MiB / 16160MiB | 0% डिफ़ॉल्ट |
+---------------------------------------------------------------------- -----+---------------------+
+-------------------------------------------------------- -----------------------------+
| प्रक्रियाएं: जीपीयू मेमोरी |
| GPU PID प्रकार प्रक्रिया का नाम उपयोग |
|============================================ ===========================|
| 0 13978 C /.conda/envs/ /bin/python 16101MiB |
+-------------------------------------------------------- -----------------------------+
 tvinith
29 फ़र॰ 2020
tvinith
29 फ़र॰ 2020
ऐसा इसलिए है क्योंकि डेटा का मिनी-बैच GPU मेमोरी में फिट नहीं होता है। बस बैच का आकार कम करें। जब मैंने cifar10 डेटासेट के लिए बैच आकार = 256 सेट किया तो मुझे वही त्रुटि मिली; फिर मैंने बैच आकार = 128 सेट किया, यह हल हो गया है।
धन्यवाद, तुम सही हो
 Rxma1805
2 मार्च 2020
Rxma1805
2 मार्च 2020
विशेष मामले के लिए, जहां पर्याप्त जीपीयू मेमोरी है, लेकिन एक त्रुटि अभी भी फेंक दी गई है। मेरे मामले में मैंने डेटालोडर में श्रमिकों की संख्या को कम करके इसे हल किया।
 Yurasyk
14 मार्च 2020
Yurasyk
14 मार्च 2020
पृष्ठभूमि
py36, pytorch1.4, tf2.0, conda
रॉबर्टा को ठीक करें
मुद्दा
@EMarquer जैसा ही मुद्दा: pycharm दिखाता है कि मेरे पास अभी भी पर्याप्त स्मृति है, हालांकि स्मृति को आवंटित स्मृति विफल हो गई है।
जिस तरह से मैंने कोशिश की
- "बैच_साइज़ = 1" विफल
- "torch.cuda.empty_cache ()" विफल रहा
- CUDA_VISIBLE_DEVICES="0" python Run.py विफल रहा
- क्योंकि मैं ज्यूपिटर का उपयोग नहीं करता, कर्नेल को पुनः आरंभ करने की कोई आवश्यकता नहीं है
सफल तरीका
- एनवीडिया-एसएमआई


- सच्चाई यह है कि जो pycharm दिखाता है वह "nvidia-smi" शो से अलग है (क्षमा करें, मैंने pycharm की तस्वीर नहीं सहेजी), वास्तव में पर्याप्त मेमोरी नहीं है ।
- प्रक्रिया 6123 और 32644 पहले टर्मिनल पर चलती है।
- सुडो किल -9 6123
- सुडो किल -9 32644
 FernandoZhuang
17 मार्च 2020
FernandoZhuang
17 मार्च 2020
मेरे लिए बस क्या काम किया:
import gc
# Your code with pytorch using GPU
gc.collect()
 MastafaF
6 अप्रैल 2020
MastafaF
6 अप्रैल 2020
मैंने आपके बैच आकार को समायोजित किए बिना इस समस्या को हल करने योग्य पाया।
ओपन टर्मिनल और एक पायथन प्रॉम्प्ट
import torch torch.cuda.empty_cache()पायथन दुभाषिया से बाहर निकलें, अपने मूल PyTorch कमांड को फिर से चलाएं और इसे (उम्मीद है) CUDA मेमोरी त्रुटि नहीं देनी चाहिए।
मेरे मामले में, यह मेरी समस्या का समाधान करता है।
 LiEAEX
10 अप्रैल 2020
LiEAEX
10 अप्रैल 2020
सुनिश्चित करें कि आप अपने GPU का उपयोग स्लॉट 0 पर --device_ids 0 . के साथ कर रहे हैं
मुझे पता है कि मैं शब्दावली को कुचल रहा हूं लेकिन यह काम कर गया। मुझे लगता है कि यह मानता है कि यदि आप एक आईडी का चयन नहीं करते हैं तो आप GPU के बजाय CPU का उपयोग करना चाहते हैं।
 aaron387
12 अप्रैल 2020
aaron387
12 अप्रैल 2020
मुझे समान त्रुटि प्राप्त हो रही है:
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 4.84 GiB आवंटित करने का प्रयास किया (GPU 0; 7.44 GiB कुल क्षमता; 5.22 GiB पहले से ही आवंटित; 1.75 GiB मुक्त; 18.51 MiB कैश्ड)
जब मैं क्लस्टर को पुनरारंभ करता हूं या बैच आकार बदलता हूं, तो यह काम करता है। लेकिन मुझे यह समाधान पसंद नहीं है। मैंने भी कोशिश की मशाल.cuda.empty_cache() , यह मेरे लिए काम नहीं करता है। क्या इसे हल करने का कोई और कारगर तरीका है?
 Tann10
13 अप्रैल 2020
Tann10
13 अप्रैल 2020
मुझे नहीं पता कि मेरा परिदृश्य मूल मुद्दे से संबंधित है या नहीं, लेकिन मैंने अपनी समस्या का समाधान किया (पिछले संदेश में OOM त्रुटि चली गई) nn को तोड़कर। मेरे मॉडल में अनुक्रमिक परतें, जैसे
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)प्रति
self.input_conv = nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0) self.input_bn = nn.BatchNorm3d(32) output = F.relu(self.input_bn(self.input_conv(x)))मेरे मॉडल में इनमें से बहुत कुछ है (सटीक होने के लिए 5 और)। क्या मैं nn.अनुक्रमिक अधिकार का उपयोग कर रहा हूँ? या यह एक बग है? @yf225 @fmassa
ऐसा लगता है कि मैं भी इसी तरह की त्रुटि को हल करता हूं लेकिन इसके विपरीत।
मैं सब बदल देता हूँ
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)प्रति
self.input_layer = nn.Sequential( nn.Conv3d(num_channels, 32, kernel_size=3, stride=1, padding=0), nn.BatchNorm3d(32), nn.ReLU() ) output = self.input_layer(x)
 xml94
14 अप्रैल 2020
xml94
14 अप्रैल 2020
मेरे लिए बैच_साइज़ बदलने या दिए गए किसी भी समाधान से मदद नहीं मिली। लेकिन यह पता चला कि मेरी .cfg फ़ाइल में मेरे पास एक परत में कक्षाओं और फ़िल्टर के गलत मान थे। तो अगर कुछ भी मदद नहीं करता है, तो अपने .cfg को दोबारा जांचें।
 ulaszewskim
1 मई 2020
ulaszewskim
1 मई 2020
टर्मिनल खोलें
पहला प्रकार
एनवीडिया-एसएमआई
फिर उस पीआईडी का चयन करें जो अजगर या एनाकोंडा पथ से मेल खाती है और लिखें
सूडो किल -9 पीआईडी
 krypticmouse
4 मई 2020
krypticmouse
4 मई 2020
मुझे यह बग कुछ समय से हो रहा है। मेरे लिए, यह पता चला है कि मैं एक अजगर चर (यानी मशाल टेंसर) रखता हूं जो मॉडल परिणाम का संदर्भ देता है, और इसलिए इसे सुरक्षित रूप से जारी नहीं किया जा सकता क्योंकि कोड अभी भी इसे एक्सेस कर सकता है।
मेरा कोड कुछ ऐसा दिखता है:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p)
इसके लिए फिक्स p को एक सूची में स्थानांतरित करना था। तो, कोड इस तरह दिखना चाहिए:
predictions = []
for batch in dataloader:
p = model(batch.to(torch.device("cuda:0")))
predictions.append(p.tolist())
यह सुनिश्चित करता है कि predictions मुख्य मेमोरी में मान रखता है, GPU में टेंसर नहीं।
 abdelrahmanhosny
8 मई 2020
abdelrahmanhosny
8 मई 2020
मेरे पास यह बग fastai.vision मॉड्यूल का उपयोग कर रहा है, जो pytorch पर निर्भर करता है। मैं CUDA 10.1 . का उपयोग कर रहा हूँ
 jkomyno
16 मई 2020
jkomyno
16 मई 2020
training_args = TrainingArguments(
output_dir="./",
overwrite_output_dir=True,
num_train_epochs=5,
per_gpu_train_batch_size=4, # 4; 8 ;16 out of memory
save_steps=10_000,
save_total_limit=2,
)
per_gpu_train_batch_size को 16 से घटाकर 8 कर दें, इससे मेरी समस्या हल हो गई।
 autodataming
3 जून 2020
autodataming
3 जून 2020
यदि आप PyTorch के नवीनतम संस्करण में अपडेट करते हैं तो आपके पास उस तरह की कम त्रुटियां हो सकती हैं
सच में,आप ऐसा क्यों कहते हैं
 XinyingZheng
9 जून 2020
XinyingZheng
9 जून 2020
इस मुद्दे का मुख्य प्रश्न अभी भी एक खुली समस्या है। मुझे वही अजीब सीयूडीए स्मृति संदेश से बाहर हो रहा है। इसने 4.08 GiB फ्री में 2.26 GiB आवंटित करने का प्रयास किया। प्रतीत होता है कि पर्याप्त स्मृति है लेकिन यह आवंटित करने में विफल रहता है।
परियोजना की जानकारी: बैच-आकार 4 के साथ एक्टिविटीनेट डेटासेट पर एक रेसनेट 10 को प्रशिक्षित करना, यह पहले युग के फाइनल में विफल रहता है।
संपादित: कुछ धारणाएं: अगर मैं अपनी रैम मेमोरी को साफ करता हूं और केवल पायथन कोड चालू रखता हूं, तो त्रुटि नहीं उठाई जाती है। हो सकता है कि GPU में पर्याप्त मेमोरी हो, लेकिन RAM मेमोरी अन्य सभी प्रोसेसिंग चरणों को संभालने में सक्षम नहीं है।
कंप्यूटर जानकारी: Dell G5 - i7 9th - GTX 1660Ti 6GB - 16 GB RAM
EDITED2: मैं 4 श्रमिकों के साथ "_MultiProcessingDataLoaderIter" का उपयोग कर रहा था और यह फॉरवर्ड कॉल में मेमोरी संदेश से बाहर हो जाता है। अगर मैं श्रमिकों की संख्या को घटाकर 1 कर दूं तो इससे कोई त्रुटि नहीं होती है। 1 कार्यकर्ता के साथ, रैम मेमोरी का उपयोग 11/16GB रहता है, 4 के साथ यह 14.5/16GB तक बढ़ जाता है। और केवल 1 कार्यकर्ता के साथ, वास्तव में, मैं बैच-आकार को 32 तक बढ़ा सकता हूं और GPU मेमोरी को 3.5GB/6GB तक बढ़ा सकता हूं।
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 2.26 GiB आवंटित करने का प्रयास किया (GPU 0; 6.00 GiB कुल क्षमता; 209.63 MiB पहले ही आवंटित; 4.08 GiB मुक्त; 246.00 MiB कुल मिलाकर PyTorch द्वारा आरक्षित)
संपूर्ण त्रुटि संदेश
ट्रेसबैक (सबसे हालिया कॉल अंतिम):
फ़ाइल "main.py", लाइन 450, in
अगर ऑप्ट। वितरित:
फ़ाइल "main.py", लाइन 409, main_worker . में
ऑप्ट.डिवाइस, current_lr, train_logger,
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\training.py", लाइन 37, train_epoch में
आउटपुट = मॉडल (इनपुट)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", लाइन 532, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nnparallel\data_parallel.py", लाइन 150, आगे की ओर
स्व.मॉड्यूल ( इनपुट्स [0], * क्वार्ग्स [0])
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", लाइन 532, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", लाइन 205, आगे में
x = स्वयं परत3(x)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", लाइन 532, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\container.py", लाइन 100, आगे की ओर
इनपुट = मॉड्यूल (इनपुट)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", लाइन 532, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\models\resnet.py", लाइन 51, आगे की ओर
बाहर = स्वयं.conv2 (बाहर)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\module.py", लाइन 532, __call__ में
परिणाम = स्वयं आगे ( इनपुट, * kwargs)
फ़ाइल "D:\Guilherme\Google Drive\Professional\Cursos\Mestrado\Pesquisa\HMDB51\envlib\site-packages\torch\nn\modules\conv.py", लाइन 480, आगे की ओर
सेल्फ़.पैडिंग, सेल्फ़.डीलेशन, सेल्फ़.ग्रुप्स)
रनटाइम त्रुटि: CUDA स्मृति से बाहर। 2.26 GiB आवंटित करने का प्रयास किया (GPU 0; 6.00 GiB कुल क्षमता; 209.63 MiB पहले ही आवंटित; 4.08 GiB मुक्त; 246.00 MiB आरक्षित)
कुल मिलाकर PyTorch द्वारा)
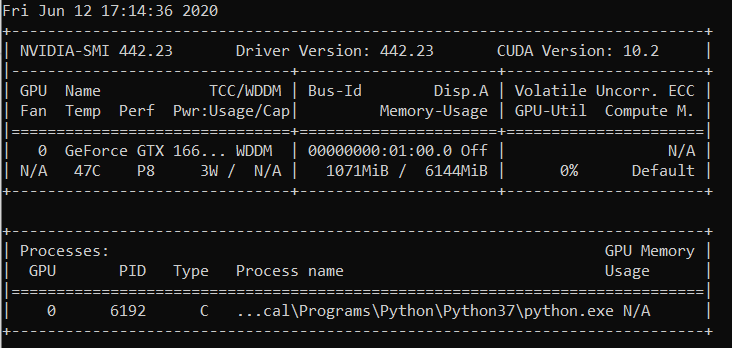
 guilhermesurek
12 जून 2020
guilhermesurek
12 जून 2020
बैच आकार छोटा, यह काम करता है
 cuge1995
15 जून 2020
cuge1995
15 जून 2020
मुझे यह बग कुछ समय से हो रहा है। मेरे लिए, यह पता चला है कि मैं एक अजगर चर (यानी मशाल टेंसर) रखता हूं जो मॉडल परिणाम का संदर्भ देता है, और इसलिए इसे सुरक्षित रूप से जारी नहीं किया जा सकता क्योंकि कोड अभी भी इसे एक्सेस कर सकता है।
मेरा कोड कुछ ऐसा दिखता है:
predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)इसके लिए फिक्स
pको एक सूची में स्थानांतरित करना था। तो, कोड इस तरह दिखना चाहिए:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())यह सुनिश्चित करता है कि
predictionsमुख्य मेमोरी में मान रखता है, GPU में टेंसर नहीं।
@abdelrahmanhosny इसे इंगित करने के लिए धन्यवाद। मुझे PyTorch 1.5.0 में ठीक उसी मुद्दे का सामना करना पड़ा, और प्रशिक्षण के दौरान कोई OOM समस्या नहीं थी, हालांकि अनुमान के दौरान मैं एक अजगर चर (यानी मशाल टेंसर) को भी पकड़े रहा, जो स्मृति में मॉडल के परिणाम को संदर्भित करता है जिसके परिणामस्वरूप GPU मेमोरी से बाहर चला जाता है बैचों की एक निश्चित संख्या के बाद।
मेरे मामले में हालांकि भविष्यवाणियों को सूची में स्थानांतरित करने से काम नहीं चला क्योंकि मैं अपने नेटवर्क के साथ चित्र बना रहा हूं, इसलिए मुझे निम्नलिखित कार्य करने पड़े:
predictions.append(p.detach().cpu().numpy())
इसने तब इस मुद्दे को हल किया!
 samkellerhals
19 जून 2020
samkellerhals
19 जून 2020
क्या कोई सामान्य समाधान है?
CUDA स्मृति से बाहर। 196.00 MiB आवंटित करने का प्रयास किया (GPU 0; 2.00 GiB कुल क्षमता; 359.38 MiB पहले ही आवंटित; 192.29 MiB मुक्त; 152.37 MiB कैश्ड)
क्या कोई सामान्य समाधान है?
CUDA स्मृति से बाहर। 196.00 MiB आवंटित करने का प्रयास किया (GPU 0; 2.00 GiB कुल क्षमता; 359.38 MiB पहले ही आवंटित; 192.29 MiB मुक्त; 152.37 MiB कैश्ड)
 manavkhadka0
24 जून 2020
manavkhadka0
24 जून 2020
मुझे यह बग कुछ समय से हो रहा है। मेरे लिए, यह पता चला है कि मैं एक अजगर चर (यानी मशाल टेंसर) रखता हूं जो मॉडल परिणाम का संदर्भ देता है, और इसलिए इसे सुरक्षित रूप से जारी नहीं किया जा सकता क्योंकि कोड अभी भी इसे एक्सेस कर सकता है।
मेरा कोड कुछ ऐसा दिखता है:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p)इसके लिए फिक्स
pको एक सूची में स्थानांतरित करना था। तो, कोड इस तरह दिखना चाहिए:predictions = [] for batch in dataloader: p = model(batch.to(torch.device("cuda:0"))) predictions.append(p.tolist())यह सुनिश्चित करता है कि
predictionsमुख्य मेमोरी में मान रखता है, GPU में टेंसर नहीं।@abdelrahmanhosny इसे इंगित करने के लिए धन्यवाद। मुझे PyTorch 1.5.0 में ठीक उसी मुद्दे का सामना करना पड़ा, और प्रशिक्षण के दौरान कोई OOM समस्या नहीं थी, हालांकि अनुमान के दौरान मैं एक अजगर चर (यानी मशाल टेंसर) को भी पकड़े रहा, जो स्मृति में मॉडल के परिणाम को संदर्भित करता है जिसके परिणामस्वरूप GPU मेमोरी से बाहर चला जाता है बैचों की एक निश्चित संख्या के बाद।
मेरे मामले में हालांकि भविष्यवाणियों को सूची में स्थानांतरित करने से काम नहीं चला क्योंकि मैं अपने नेटवर्क के साथ चित्र बना रहा हूं, इसलिए मुझे निम्नलिखित कार्य करने पड़े:
predictions.append(p.detach().cpu().numpy())इसने तब इस मुद्दे को हल किया!
मेरे पास ParrallelWaveGAN मॉडल में एक ही समस्या है और मैंने #16417 में समाधानों का उपयोग किया लेकिन यह मेरे लिए काम नहीं करता है
y = self.model_gan(*x).view(-1).detach().cpu().numpy()
जीसी.संग्रह ()
मशाल.कुडा.खाली_कैश ()
 tuong-olli
25 जून 2020
tuong-olli
25 जून 2020
प्रशिक्षण के दौरान भी यही समस्या थी।
प्रत्येक युग के बाद कचरा इकट्ठा करना और कूडा मेमोरी खाली करना मेरे लिए इस मुद्दे को हल करता है।
gc.collect()
torch.cuda.empty_cache()
 IsakWesterlundBitville
5 अग॰ 2020
IsakWesterlundBitville
5 अग॰ 2020
मेरे लिए बस क्या काम किया:
import gc # Your code with pytorch using GPU gc.collect()
शुक्रिया!! मुझे बिल्लियों और कुत्तों का उदाहरण चलाने में परेशानी हो रही थी और इसने मेरे लिए काम किया।
 Michelpayan
5 अग॰ 2020
Michelpayan
5 अग॰ 2020
प्रशिक्षण के दौरान भी यही समस्या थी।
प्रत्येक युग के बाद कचरा इकट्ठा करना और कूडा मेमोरी खाली करना मेरे लिए इस मुद्दे को हल करता है।gc.collect() torch.cuda.empty_cache()
मेरे लिए भी ऐसा
 AleksandrTulenkov
6 अग॰ 2020
AleksandrTulenkov
6 अग॰ 2020
बैच का आकार घटाएं और युगों को बढ़ाएं। इस तरह मैंने इसे हल किया।
 oyekamal
18 सित॰ 2020
oyekamal
18 सित॰ 2020
@areebsyed राम स्मृति की जांच करें, समानांतर में कई श्रमिकों को सेट करते समय मुझे यह समस्या थी।
guilhermesurek
29 सित॰ 2020
मुझे एक ही युग पूरा किए बिना कोलाब में पाइटोरच में बर्ट2बर्ट एनकोडरडीकोडरमॉडल को फाइनट्यूनिंग करते समय भी वही त्रुटि मिल रही है।
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB (GPU 0; 15.90 GiB total capacity; 13.77 GiB already allocated; 59.88 MiB free; 14.98 GiB reserved in total by PyTorch)
 Aakash12980
6 अक्तू॰ 2020
Aakash12980
6 अक्तू॰ 2020
@ Aakash12980 क्या आपने बैच के आकार को कम करने की कोशिश की? साथ ही जिन इनपुट छवियों को आप प्रशिक्षित करना चाहते हैं, वे शायद उनका आकार बदलने का प्रयास करें
 areebsyed
6 अक्तू॰ 2020
areebsyed
6 अक्तू॰ 2020
@areebsyed हाँ, मैंने बैच का आकार घटाकर 4 कर दिया और यह काम कर गया।
Aakash12980
6 अक्तू॰ 2020
वैसा ही
RuntimeError Traceback (most recent call last)
<ipython-input-116-11ebb3420695> in <module>
28 landmarks = landmarks.view(landmarks.size(0),-1).cuda()
29
---> 30 predictions = network(images)
31
32 # clear all the gradients before calculating them
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-112-174da452c85d> in forward(self, x)
13 ##out = self.first_conv(x)
14 x = x.float()
---> 15 out = self.model(x)
16 return out
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x)
218
219 def forward(self, x):
--> 220 return self._forward_impl(x)
221
222
~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x)
204 x = self.bn1(x)
205 x = self.relu(x)
--> 206 x = self.maxpool(x)
207
208 x = self.layer1(x)
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input)
157 return F.max_pool2d(input, self.kernel_size, self.stride,
158 self.padding, self.dilation, self.ceil_mode,
--> 159 self.return_indices)
160
161
~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs)
245 return if_true(*args, **kwargs)
246 else:
--> 247 return if_false(*args, **kwargs)
248
249 if if_true.__doc__ is None and if_false.__doc__ is not None:
~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices)
574 stride = torch.jit.annotate(List[int], [])
575 return torch.max_pool2d(
--> 576 input, kernel_size, stride, padding, dilation, ceil_mode)
577
578 max_pool2d = boolean_dispatch(
RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
 monajalal
7 अक्तू॰ 2020
monajalal
7 अक्तू॰ 2020
वैसा ही
RuntimeError Traceback (most recent call last) <ipython-input-116-11ebb3420695> in <module> 28 landmarks = landmarks.view(landmarks.size(0),-1).cuda() 29 ---> 30 predictions = network(images) 31 32 # clear all the gradients before calculating them ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), <ipython-input-112-174da452c85d> in forward(self, x) 13 ##out = self.first_conv(x) 14 x = x.float() ---> 15 out = self.model(x) 16 return out ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in forward(self, x) 218 219 def forward(self, x): --> 220 return self._forward_impl(x) 221 222 ~/anaconda3/lib/python3.7/site-packages/torchvision/models/resnet.py in _forward_impl(self, x) 204 x = self.bn1(x) 205 x = self.relu(x) --> 206 x = self.maxpool(x) 207 208 x = self.layer1(x) ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs) 720 result = self._slow_forward(*input, **kwargs) 721 else: --> 722 result = self.forward(*input, **kwargs) 723 for hook in itertools.chain( 724 _global_forward_hooks.values(), ~/anaconda3/lib/python3.7/site-packages/torch/nn/modules/pooling.py in forward(self, input) 157 return F.max_pool2d(input, self.kernel_size, self.stride, 158 self.padding, self.dilation, self.ceil_mode, --> 159 self.return_indices) 160 161 ~/anaconda3/lib/python3.7/site-packages/torch/_jit_internal.py in fn(*args, **kwargs) 245 return if_true(*args, **kwargs) 246 else: --> 247 return if_false(*args, **kwargs) 248 249 if if_true.__doc__ is None and if_false.__doc__ is not None: ~/anaconda3/lib/python3.7/site-packages/torch/nn/functional.py in _max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode, return_indices) 574 stride = torch.jit.annotate(List[int], []) 575 return torch.max_pool2d( --> 576 input, kernel_size, stride, padding, dilation, ceil_mode) 577 578 max_pool2d = boolean_dispatch( RuntimeError: CUDA out of memory. Tried to allocate 80.00 MiB (GPU 0; 7.80 GiB total capacity; 1.87 GiB already allocated; 34.69 MiB free; 1.93 GiB reserved in total by PyTorch)
@monajalal बैच आकार या इनपुट आयाम आकार को कम करने का प्रयास करें।
Aakash12980
7 अक्तू॰ 2020
तो नीचे दिए गए उदाहरणों पर संकल्प क्या है (यानी बहुत सारी _free_ मेमोरी और बहुत कम आवंटित करने का प्रयास कर रहा है - जो इस धागे में _some_ उदाहरणों से अलग है जब वास्तव में मुफ्त मेम की थोड़ी मात्रा होती है और कुछ भी गलत नहीं होता है)?
रनटाइम त्रुटि: CUDA स्मृति से बाहर। _ 1.33 GiB _ आवंटित करने का प्रयास किया (GPU 1; 31.72 GiB कुल क्षमता; 5.68 GiB पहले से ही आवंटित; _ 24.94 GiB मुक्त _; 5.96 MiB कैश्ड)
मुझे नहीं पता कि मुद्दा 'बंद' स्थिति में क्यों गया, क्योंकि यह अभी भी नवीनतम पाइटोरच वर् (1.2) और आधुनिक एनवीआईडीआईए जीपीयू (वी -100) पर होता है।
धन्यवाद!
हां, मुझे लगता है कि ज्यादातर लोगों को यह एहसास नहीं है कि समस्या केवल ओओएम नहीं है, यह है कि ओओएम है जबकि त्रुटि कहती है कि पर्याप्त खाली जगह है। मुझे विंडोज़ पर भी इस समस्या का सामना करना पड़ रहा है, क्या आपको कोई समाधान मिला?
 YoadTew
6 नव॰ 2020
YoadTew
6 नव॰ 2020
संबंधित मुद्दों
 bartolsthoorn
·
3टिप्पणियाँ
bartolsthoorn
·
3टिप्पणियाँ
 miguelvr
·
3टिप्पणियाँ
miguelvr
·
3टिप्पणियाँ
 NgPDat
·
3टिप्पणियाँ
NgPDat
·
3टिप्पणियाँ
 soumith
·
3टिप्पणियाँ
soumith
·
3टिप्पणियाँ
 dablyo
·
3टिप्पणियाँ
dablyo
·
3टिप्पणियाँ
सबसे उपयोगी टिप्पणी
ऐसा इसलिए है क्योंकि डेटा का मिनी-बैच GPU मेमोरी में फिट नहीं होता है। बस बैच का आकार कम करें। जब मैंने cifar10 डेटासेट के लिए बैच आकार = 256 सेट किया तो मुझे वही त्रुटि मिली; फिर मैंने बैच आकार = 128 सेट किया, यह हल हो गया है।